My biggest nodes finished retain. 7 machines running 2 nodes, 1 running 1 node.
c21 - 1GB RAM
2024-05-03T02:38:19Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 497512, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 14971763, "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Duration": "4h54m57.465579453s", "Retain Status": "enabled"}
c22 - 1GB RAM
2024-05-03T11:24:50Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 870972, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 16702227, "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Duration": "6h50m56.643776581s", "Retain Status": "enabled"}
o11 - 10GB RAM
2024-05-04T11:56:39Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 8920068, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 39679616, "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Duration": "38h13m18.232162572s", "Retain Status": "enabled"}
p11 - 18GB RAM
2024-05-04T00:42:33Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 8841137, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 41333620, "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Duration": "23h25m22.955227817s", "Retain Status": "enabled"}
b11 - 18GB RAM
2024-05-04T07:29:39Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 10111171, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 52834911, "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Duration": "32h36m50.416953082s", "Retain Status": "enabled"}
c11 - 18GB RAM
2024-05-03T20:01:26Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 8309277, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 38004048, "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Duration": "19h28m55.526847405s", "Retain Status": "enabled"}
g11 - 18GB RAM
2024-05-03T19:46:26Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 9021317, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 45557230, "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Duration": "24h40m13.705897155s", "Retain Status": "enabled"}
o21 - 18GB RAM
2024-05-04T00:25:33Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 9798363, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 46085859, "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Duration": "27h52m2.24455936s", "Retain Status": "enabled"}
r11 - 18GB RAM, space used 11.02TB, trash 1.74TB, sat report 10.2TB
2024-05-03T23:02:28Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 9784271, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 45714626, "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Duration": "28h54m40.065068586s", "Retain Status": "enabled"}
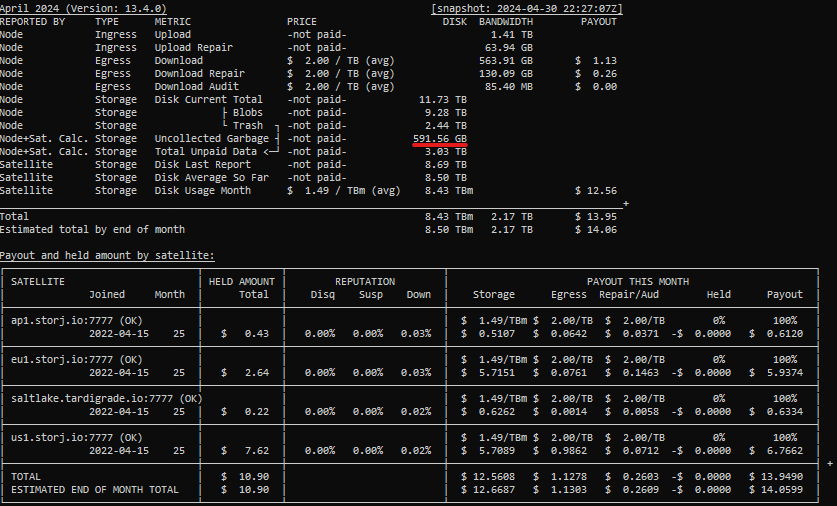
I put the dashboard data for the last one as reference. This is now, after retain.
RAM has the biggest influence on walkers speed, including used-space and retain.
You can see the difference between o11 and p11, which have almost the same piece count and pieces removed: 38h/10GB and 23h/18GB. p11 has 2 nodes, o11 has one node.