Yeah, sure. You’ve got bad, worse, and worst…
I just did a check on all my nodes. Suddenly each node has 200-400GB of data sent to trash in one day…
Yeah, that might be normal once or twice a week due to the bloom filter. At least if your nodes are filled up to 4-8TB each.
I don’t really have answers to your problem. I didn’t find any other anomaly, so my best guess it was normal, just strange usage pattern.
I have a few ideas, but couldn’t prove them without doing very expensive db restore process:
- your node may be started later than the others, at the time when one specific customer was extremely active, who deleted all the data.
- one other variation: in case you use proxy nodes, your IP country code might be changed in the geoip database, and data is moved to different countries.
I checked my storagenodes, and they were fine.
BTW, I like your query with PARTITION BY. I tried to edit my original post, but failed (that’s why I deleted my previous post).
Generic update:
- We are planning to use max ~4 Mbyte bloom filters from today or tomorrow (first on SLC/AP)
That’s not the optimal for very big nodes, bust based on the simulation it’s enough to start shrinking the unnecessary data. Full shrinking requires more GC period (=more weeks), which also useful, as trash can be processed meantime, and is not necessary to delete everything in one round.
Bigger bloom filter requires protocol changes (this, and few more patches)
https://review.dev.storj.io/c/storj/common/+/12353
That’s a long term solution as requires full rollout.
Also, two more metrics are added (satellite_usage/blobs_usage), and will be available from 1.98:
These can be used to monitor locally the space usage reported by storagenode and satellite, and you can also compare it.
If you telemetry is enabled, the data will be received by us, and we can be alerted by big discrepancies (and monitor the shrinking process).
Will changes be made to the “filewalker” code so that it remembers where it “stopped” and does not start from 0 every time?
Exactly the same thought came up to me some days ago. But I could imagine it still wouldn’t make a consistent state. However, that may also happen when files are being deleted during running the node by hand out any other process.
So you, let’s consider this suggestion
On all my nodes there is a difference of 2-2.5 Tb between “Average Disk Space Used This Month” and “Used”. I think that’s a lot. Minimum 2 Tb of unaccounted and unpaid data on each node.
And how are you?
Probbaly same.
Because node has to catch up to the last month ingress.
It can take even 1 to 3 weeks, if node is slow.
Last month there was 2-2,5TB of new data, and to account that for “Average Disk Space Used This Month”, (on which base the node shows payment in dashboards) is a time-consuming work for a disk. Storj is not for small disk nodes IMHO, if one month is like 2TB comes and goes, IMHO there always will be some discrepancy by the amount of last month, untill the node does catch up, and that can take him time, like 1-3+ weeks just to account last month’s data.
EDIT:
I saw that discrepancies even before announcments of satelites decomisioning, like 1-1,5year ago, when i looked into logs, but it does NOT matter back then, because we were payed much more overall, and no one cared about those stats. Now, the main income depends on that, so everyones somehow annoyed.
I have WD 20 Tb disks on all nodes. They don’t “strain” at all and work at 5-10%. It doesn’t look like the disks are don’t have time.
You may check this:
docker logs storagenode 2>&1 | grep walk | grep -iE "failed|error"
Who may check this?
ps. all nodes on Windows without docker
Then you may check it with a PowerShell
sls walk "C:\Program Files\Storj\Storage Node\storagenode.log" | sls "failed|error"
Check on all 50 nodes?
Well, this is nonsense.
This is a global problem, not a node problem. This is observed on all nodes + others have the same problem
Yes. And if they failed on all your nodes - you did it wrong, it shouldn’t fail.
First of all, I must understand what I should see (or should not see) from this command?
Here is an example of an answer for one of the nodes.
O:\storagenode.log:95870:2024-02-01T12:18:43+02:00 INFO lazyfilewalker.gc-filewalker subprocess exited with status
{“satelliteID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “status”: 1, “error”: “exit status 1”}
O:\storagenode.log:95871:2024-02-01T12:18:43+02:00 ERROR pieces lazyfilewalker failed {“error”: “lazyfilewalker: exit
status 1”, “errorVerbose”: “lazyfilewalker: exit status 1\n\tstorj.io/storj/storagenode/pieces/lazyfilewalker.(*process
).run:83\n\tstorj.io/storj/storagenode/pieces/lazyfilewalker.(*Supervisor).WalkSatellitePiecesToTrash:130\n\tstorj.io/s
torj/storagenode/pieces.(*Store).SatellitePiecesToTrash:555\n\tstorj.io/storj/storagenode/retain.(*Service).retainPiece
s:325\n\tstorj.io/storj/storagenode/retain.(*Service).Run.func2:221\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75”
}
O:\storagenode.log:95872:2024-02-01T12:18:43+02:00 ERROR retain retain pieces failed {“error”: “retain: filewalker:
context canceled”, “errorVerbose”: “retain: filewalker: context canceled\n\tstorj.io/storj/storagenode/pieces.(*FileWal
ker).WalkSatellitePieces:69\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkSatellitePiecesToTrash:146\n\tstorj.
io/storj/storagenode/pieces.(*Store).SatellitePiecesToTrash:562\n\tstorj.io/storj/storagenode/retain.(*Service).retainP
ieces:325\n\tstorj.io/storj/storagenode/retain.(*Service).Run.func2:221\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1
:75”}
O:\storagenode.log:5485233:2024-02-04T18:43:19+02:00 ERROR piecestore upload failed {“Piece ID”:
“WCPCYJBDQUGWWNODGRMFPIBKVSUSVVVUAKDXY7TW7UMWALKCFBTA”, “Satellite ID”:
“12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “PUT”, “error”: “manager closed: unexpected EOF”,
“errorVerbose”: “manager closed: unexpected EOF\n\tgithub.com/jtolio/noiseconn.(*Conn).readMsg:225\n\tgithub.com/jtolio
/noiseconn.(*Conn).Read:171\n\tstorj.io/drpc/drpcwire.(*Reader).ReadPacketUsing:96\n\tstorj.io/drpc/drpcmanager.(*Manag
er).manageReader:226”, “Size”: 196608, “Remote Address”: “5.161.211.187:43988”}
O:\storagenode.log:6742412:2024-02-05T13:26:07+02:00 ERROR piecestore upload failed {“Piece ID”:
“KEFPFYK42DZMYTGQWALKZDVOXAVOCW7ZKYRODJHPLR5LJG3C2UFA”, “Satellite ID”:
“12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “PUT”, “error”: “manager closed: unexpected EOF”,
“errorVerbose”: “manager closed: unexpected EOF\n\tgithub.com/jtolio/noiseconn.(*Conn).readMsg:225\n\tgithub.com/jtolio
/noiseconn.(*Conn).Read:171\n\tstorj.io/drpc/drpcwire.(*Reader).ReadPacketUsing:96\n\tstorj.io/drpc/drpcmanager.(*Manag
er).manageReader:226”, “Size”: 458752, “Remote Address”: “5.161.211.187:43956”}
O:\storagenode.log:7986070:2024-02-06T08:00:14+02:00 ERROR piecestore upload failed {“Piece ID”:
“NNNMCNSGSMQFOL3SE5VO3ALTP7HPQOZJ4WALKU76OUENPBPIDNCQ”, “Satellite ID”:
“12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “PUT”, “error”: “manager closed: unexpected EOF”,
“errorVerbose”: “manager closed: unexpected EOF\n\tgithub.com/jtolio/noiseconn.(*Conn).readMsg:225\n\tgithub.com/jtolio
/noiseconn.(*Conn).Read:171\n\tstorj.io/drpc/drpcwire.(*Reader).ReadPacketUsing:96\n\tstorj.io/drpc/drpcmanager.(*Manag
er).manageReader:226”, “Size”: 393216, “Remote Address”: “79.127.219.34:56440”}
If one user has a problem then most likely the user did something wrong.
If many users do have a problem most likely it is the software.
At least for me it did not change any config file. Also the permissions are fine. Also the ressources and the performance of the system are plenty.
So if it is not working correctly then the software needs to take care of it.
If a filewalker process stops then it has to be restarted automatically. Also it has to restarted at or a little before the point where it stopped and not from the beginning.
I again have some doubts on a node:
# use of the STORJ-filesystem, turns out to be 2.4TB in contrast to the 2.78 according to the dashboard (although finished filewalkers, done days ago)
root@STORJ4:/# df /storj/disk
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/disk/by-partlabel/STORJ4-DATA 2883097784 2422340592 314229248 89% /storj/disk
# All (gc-)filewalker and retain info.
root@STORJ4:/# docker logs storagenode 2>&1 | grep -iE "walk|retain" | grep -iE "starting|finish|complete|error|trash"
2024-02-08T14:14:53Z INFO lazyfilewalker.used-space-filewalker starting subprocess {"process": "storagenode", "satelliteID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2024-02-08T16:12:32Z INFO lazyfilewalker.gc-filewalker starting subprocess {"process": "storagenode", "satelliteID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S"}
2024-02-08T16:58:40Z INFO lazyfilewalker.used-space-filewalker.subprocess used-space-filewalker completed {"process": "storagenode", "satelliteID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "process": "storagenode", "piecesTotal": 106283422464, "piecesContentSize": 106189359872}
2024-02-08T16:58:40Z INFO lazyfilewalker.used-space-filewalker subprocess finished successfully {"process": "storagenode", "satelliteID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2024-02-08T16:58:40Z INFO lazyfilewalker.used-space-filewalker starting subprocess {"process": "storagenode", "satelliteID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2024-02-09T01:47:53Z INFO lazyfilewalker.used-space-filewalker.subprocess used-space-filewalker completed {"process": "storagenode", "satelliteID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "process": "storagenode", "piecesTotal": 419935116032, "piecesContentSize": 419678183168}
2024-02-09T01:47:53Z INFO lazyfilewalker.used-space-filewalker subprocess finished successfully {"process": "storagenode", "satelliteID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2024-02-09T01:47:53Z INFO lazyfilewalker.used-space-filewalker starting subprocess {"process": "storagenode", "satelliteID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE"}
2024-02-09T02:19:51Z INFO lazyfilewalker.used-space-filewalker.subprocess used-space-filewalker completed {"process": "storagenode", "satelliteID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "piecesTotal": 64790018560, "piecesContentSize": 64773615104, "process": "storagenode"}
2024-02-09T02:19:51Z INFO lazyfilewalker.used-space-filewalker subprocess finished successfully {"process": "storagenode", "satelliteID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE"}
2024-02-09T02:19:51Z INFO lazyfilewalker.used-space-filewalker starting subprocess {"process": "storagenode", "satelliteID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S"}
2024-02-10T04:23:53Z INFO lazyfilewalker.gc-filewalker starting subprocess {"process": "storagenode", "satelliteID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2024-02-10T04:39:29Z INFO lazyfilewalker.gc-filewalker.subprocess gc-filewalker completed {"process": "storagenode", "satelliteID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "process": "storagenode", "piecesCount": 183742, "piecesSkippedCount": 0}
2024-02-10T04:39:29Z INFO lazyfilewalker.gc-filewalker subprocess finished successfully {"process": "storagenode", "satelliteID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2024-02-10T04:52:45Z INFO retain Moved pieces to trash during retain {"process": "storagenode", "Deleted pieces": 4773, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 183742, "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "Duration": "28m52.160008061s", "Retain Status": "enabled"}
# usage from different nodes (very well matches filewalker info above)
root@STORJ4:/storj/DBs# sqlite3 storage_usage.db "SELECT satellite, timestamp, avgByteOverTime FROM (SELECT timestamp, hex(satellite_id) AS satellite, at_rest_total / (julianday(interval_end_time) - julianday(LAG(interval_end_time, -1) OVER (PARTITION BY satellite_id ORDER BY timestamp DESC))) / 24 AS avgByteOverTime, ROW_NUMBER() OVER (PARTITION BY satellite_id ORDER BY timestamp DESC) AS rown FROM storage_usage) WHERE rown <= 5 ORDER BY satellite,timestamp"
04489F5245DED48D2A8AC8FB5F5CD1C6A638F7C6E75EFD800EF2D72000000000|2023-07-16 00:00:00+00:00|144192716.626476
04489F5245DED48D2A8AC8FB5F5CD1C6A638F7C6E75EFD800EF2D72000000000|2023-07-17 00:00:00+00:00|146073591.259973
04489F5245DED48D2A8AC8FB5F5CD1C6A638F7C6E75EFD800EF2D72000000000|2023-07-18 00:00:00+00:00|147369797.354646
04489F5245DED48D2A8AC8FB5F5CD1C6A638F7C6E75EFD800EF2D72000000000|2023-07-19 00:00:00+00:00|148666727.815211
04489F5245DED48D2A8AC8FB5F5CD1C6A638F7C6E75EFD800EF2D72000000000|2023-07-20 00:00:00+00:00|131463354.901321
7B2DE9D72C2E935F1918C058CAAF8ED00F0581639008707317FF1BD000000000|2024-02-08 00:00:00+00:00|64738277257.9981
7B2DE9D72C2E935F1918C058CAAF8ED00F0581639008707317FF1BD000000000|2024-02-09 00:00:00+00:00|64738663687.9754
7B2DE9D72C2E935F1918C058CAAF8ED00F0581639008707317FF1BD000000000|2024-02-10 00:00:00+00:00|64742384747.9321
7B2DE9D72C2E935F1918C058CAAF8ED00F0581639008707317FF1BD000000000|2024-02-11 00:00:00+00:00|64747554091.643
7B2DE9D72C2E935F1918C058CAAF8ED00F0581639008707317FF1BD000000000|2024-02-12 00:00:00+00:00|64750030319.395
84A74C2CD43C5BA76535E1F42F5DF7C287ED68D33522782F4AFABFDB40000000|2024-02-08 00:00:00+00:00|105015750541.093
84A74C2CD43C5BA76535E1F42F5DF7C287ED68D33522782F4AFABFDB40000000|2024-02-09 00:00:00+00:00|104981023087.647
84A74C2CD43C5BA76535E1F42F5DF7C287ED68D33522782F4AFABFDB40000000|2024-02-10 00:00:00+00:00|104956704999.931
84A74C2CD43C5BA76535E1F42F5DF7C287ED68D33522782F4AFABFDB40000000|2024-02-11 00:00:00+00:00|104945103006.922
84A74C2CD43C5BA76535E1F42F5DF7C287ED68D33522782F4AFABFDB40000000|2024-02-12 00:00:00+00:00|104977068589.734
A28B4F04E10BAE85D67F4C6CB82BF8D4C0F0F47A8EA72627524DEB6EC0000000|2024-02-08 00:00:00+00:00|1028081732731.87
A28B4F04E10BAE85D67F4C6CB82BF8D4C0F0F47A8EA72627524DEB6EC0000000|2024-02-09 00:00:00+00:00|1025146820207.34
A28B4F04E10BAE85D67F4C6CB82BF8D4C0F0F47A8EA72627524DEB6EC0000000|2024-02-10 00:00:00+00:00|1021859087881.31
A28B4F04E10BAE85D67F4C6CB82BF8D4C0F0F47A8EA72627524DEB6EC0000000|2024-02-11 00:00:00+00:00|1020705120188.91
A28B4F04E10BAE85D67F4C6CB82BF8D4C0F0F47A8EA72627524DEB6EC0000000|2024-02-12 00:00:00+00:00|1020602180000.92
AF2C42003EFC826AB4361F73F9D890942146FE0EBE806786F8E7190800000000|2024-02-08 00:00:00+00:00|390792862074.954
AF2C42003EFC826AB4361F73F9D890942146FE0EBE806786F8E7190800000000|2024-02-09 00:00:00+00:00|390576643412.888
AF2C42003EFC826AB4361F73F9D890942146FE0EBE806786F8E7190800000000|2024-02-10 00:00:00+00:00|390452972495.512
AF2C42003EFC826AB4361F73F9D890942146FE0EBE806786F8E7190800000000|2024-02-11 00:00:00+00:00|390414367902.742
AF2C42003EFC826AB4361F73F9D890942146FE0EBE806786F8E7190800000000|2024-02-12 00:00:00+00:00|390223688111.124
F474535A19DB00DB4F8071A1BE6C2551F4DED6A6E38F0818C68C68D000000000|2023-07-07 00:00:00+00:00|7486600615.43177
F474535A19DB00DB4F8071A1BE6C2551F4DED6A6E38F0818C68C68D000000000|2023-07-08 00:00:00+00:00|8107823697.52226
F474535A19DB00DB4F8071A1BE6C2551F4DED6A6E38F0818C68C68D000000000|2023-07-09 00:00:00+00:00|8735136386.23363
F474535A19DB00DB4F8071A1BE6C2551F4DED6A6E38F0818C68C68D000000000|2023-07-10 00:00:00+00:00|8513675933.10673
F474535A19DB00DB4F8071A1BE6C2551F4DED6A6E38F0818C68C68D000000000|2023-07-11 00:00:00+00:00|3118324227.59878
root@STORJ4:/storj/disk/DATA/storage/blobs# ls
pmw6tvzmf2jv6giyybmmvl4o2ahqlaldsaeha4yx74n5aaaaaaaa
qstuylguhrn2ozjv4h2c6xpxykd622gtgurhql2k7k75wqaaaaaa
ukfu6bhbboxilvt7jrwlqk7y2tapb5d2r2tsmj2sjxvw5qaaaaaa
v4weeab67sbgvnbwd5z7tweqsqqun7qox2agpbxy44mqqaaaaaaa
Interestingly, the database is reporting on 6 satellites of which one apparently is thrash. But I don’t know what F474535A19DB00DB4F8071A1BE6C2551F4DED6A6E38F0818C68C68D000000000 is meant to be. In the blobs folder in each case there are only four folders.
As can be seen, over 24 hours after last bloom filters of all satellites have come along, the thrash is virtually empty with a big difference between reported and used disk space over 1TB:
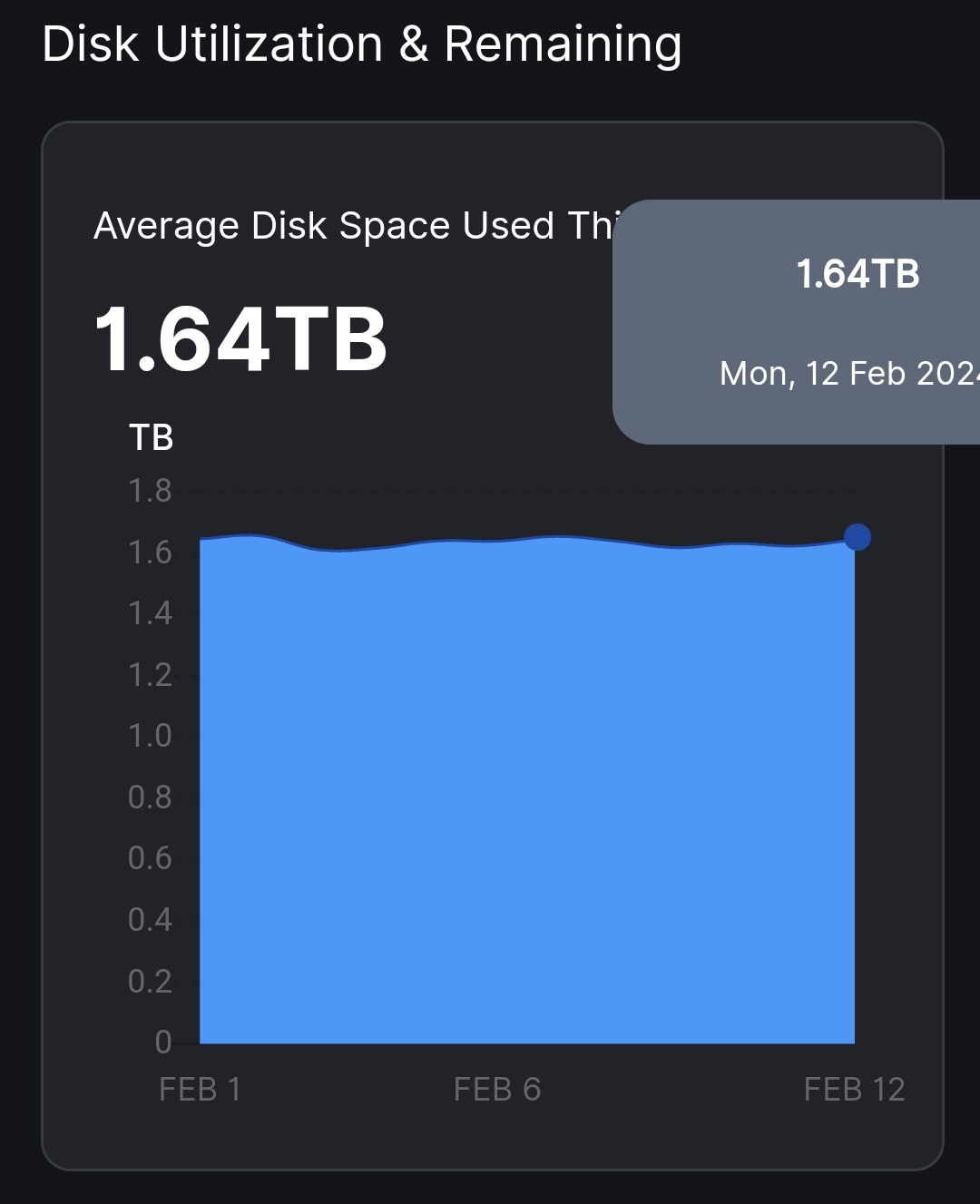
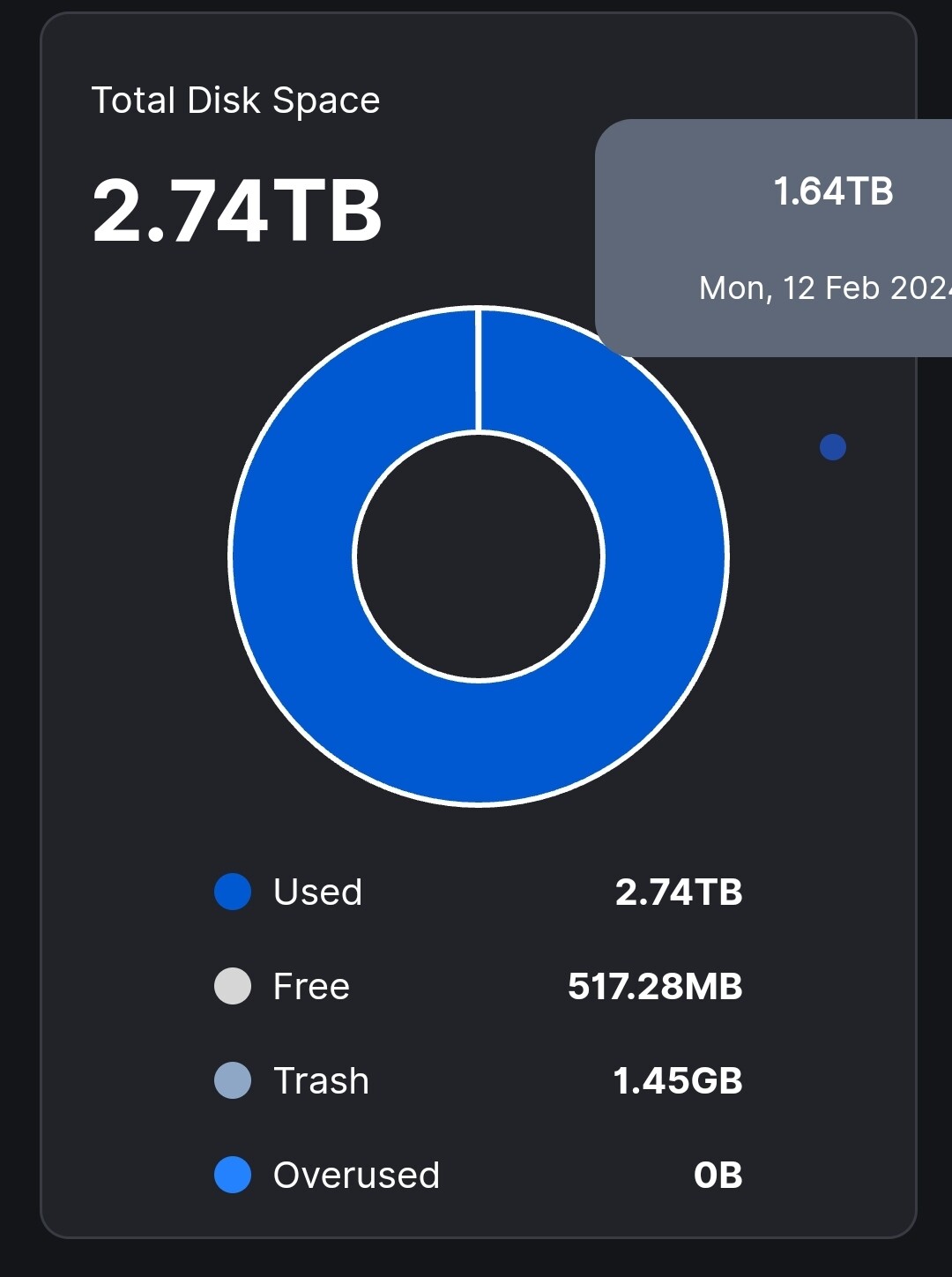
The problem seems to be a silent one, not reported in the logs.
A restart confirms this:
root@STORJ4:~# docker logs storagenode 2>&1 | grep -iE "walk|retain" | grep -iE "starting|finish|complete|error|trash"
2024-02-12T06:25:39Z INFO lazyfilewalker.used-space-filewalker starting subprocess {"process": "storagenode", "satelliteID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2024-02-12T07:50:42Z INFO lazyfilewalker.used-space-filewalker.subprocess used-space-filewalker completed {"process": "storagenode", "satelliteID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "process": "storagenode", "piecesTotal": 105489881856, "piecesContentSize": 105398152448}
2024-02-12T07:50:42Z INFO lazyfilewalker.used-space-filewalker subprocess finished successfully {"process": "storagenode", "satelliteID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2024-02-12T07:50:42Z INFO lazyfilewalker.used-space-filewalker starting subprocess {"process": "storagenode", "satelliteID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2024-02-12T11:34:54Z INFO lazyfilewalker.used-space-filewalker.subprocess used-space-filewalker completed {"process": "storagenode", "satelliteID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "process": "storagenode", "piecesTotal": 420682321664, "piecesContentSize": 420424405760}
2024-02-12T11:34:54Z INFO lazyfilewalker.used-space-filewalker subprocess finished successfully {"process": "storagenode", "satelliteID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2024-02-12T11:34:54Z INFO lazyfilewalker.used-space-filewalker starting subprocess {"process": "storagenode", "satelliteID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE"}
2024-02-12T11:46:35Z INFO lazyfilewalker.used-space-filewalker.subprocess used-space-filewalker completed {"process": "storagenode", "satelliteID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "process": "storagenode", "piecesTotal": 64806331392, "piecesContentSize": 64789923328}
2024-02-12T11:46:35Z INFO lazyfilewalker.used-space-filewalker subprocess finished successfully {"process": "storagenode", "satelliteID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE"}
2024-02-12T11:46:35Z INFO lazyfilewalker.used-space-filewalker starting subprocess {"process": "storagenode", "satelliteID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S"}
# Filter upload/download-failures and ping issues
root@STORJ4:~# docker logs storagenode 2>&1 | grep -iE "error" | grep -ivE "error\s+(piecestore|contact:service)"
[EMPTY RESULT]
# filter context cancelled
root@STORJ4:~# docker logs storagenode 2>&1 | grep -iE "context"
[EMPTY RESULT]
# real used space per node
root@STORJ4:/storj/disk/DATA/storage# sudo du --max-depth=2 --apparent-size
4 ./garbage
911912 ./trash/qstuylguhrn2ozjv4h2c6xpxykd622gtgurhql2k7k75wqaaaaaa
36580 ./trash/v4weeab67sbgvnbwd5z7tweqsqqun7qox2agpbxy44mqqaaaaaaa
4120 ./trash/pmw6tvzmf2jv6giyybmmvl4o2ahqlaldsaeha4yx74n5aaaaaaaa
220908 ./trash/ukfu6bhbboxilvt7jrwlqk7y2tapb5d2r2tsmj2sjxvw5qaaaaaa
1173524 ./trash # interestingly not matching sum of above figures?!
19335402 ./temp
103049781 ./blobs/qstuylguhrn2ozjv4h2c6xpxykd622gtgurhql2k7k75wqaaaaaa
410967481 ./blobs/v4weeab67sbgvnbwd5z7tweqsqqun7qox2agpbxy44mqqaaaaaaa
63293815 ./blobs/pmw6tvzmf2jv6giyybmmvl4o2ahqlaldsaeha4yx74n5aaaaaaaa
(... still running ...)
# parallel in another shell, the filesystem stays with it's opinion on total size of trash
root@STORJ4:/storj/disk/DATA/storage/trash# du --max-depth=1
922268 ./qstuylguhrn2ozjv4h2c6xpxykd622gtgurhql2k7k75wqaaaaaa
40552 ./v4weeab67sbgvnbwd5z7tweqsqqun7qox2agpbxy44mqqaaaaaaa
4124 ./pmw6tvzmf2jv6giyybmmvl4o2ahqlaldsaeha4yx74n5aaaaaaaa
224648 ./ukfu6bhbboxilvt7jrwlqk7y2tapb5d2r2tsmj2sjxvw5qaaaaaa
1191596 .
Filewalkers seem to run fine, although taking their time …
But they just seem not to do what they are supposed to do. Especially the gc-filewalker, since the thrash bin essentially is too empty considering the space used versus reported space.
@elek: any comments on this? Do we need more info? Is there some timeout or something on moving files? Apparently files incorrectly aren’t marked as thrashable or aren’t moved to thrash. There seem to be silent failures. Are files moved to thrash during the gc-filewalking or afterwards? By the gc-filewalker process itself, or by the retain process?
Yes, how much has already been said about “filewalker”. Many worthy ideas were proposed. And what? We talked and went our separate ways. Given that the “filewalker” must bypass 45 million files, it has a 99% chance of not being completed. There is no point in talking about “lazy-filewalker” at all. For such volumes it is a useless function. It is necessary to change its operating principle so that it remembers where it stops and does not start everything from 0.
Therefore, a “filewalker” solution should already be in the works.