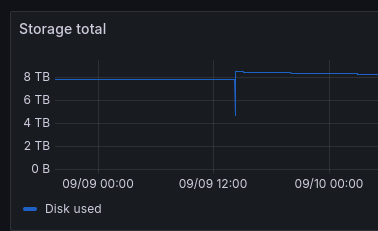
Disconnect briefly every day after moved to Hashstore on version 1.35.5
I have a problem with one of my Storj nodes. They have been moved to Hashstore, but I don’t know if that’s where the problem lies.
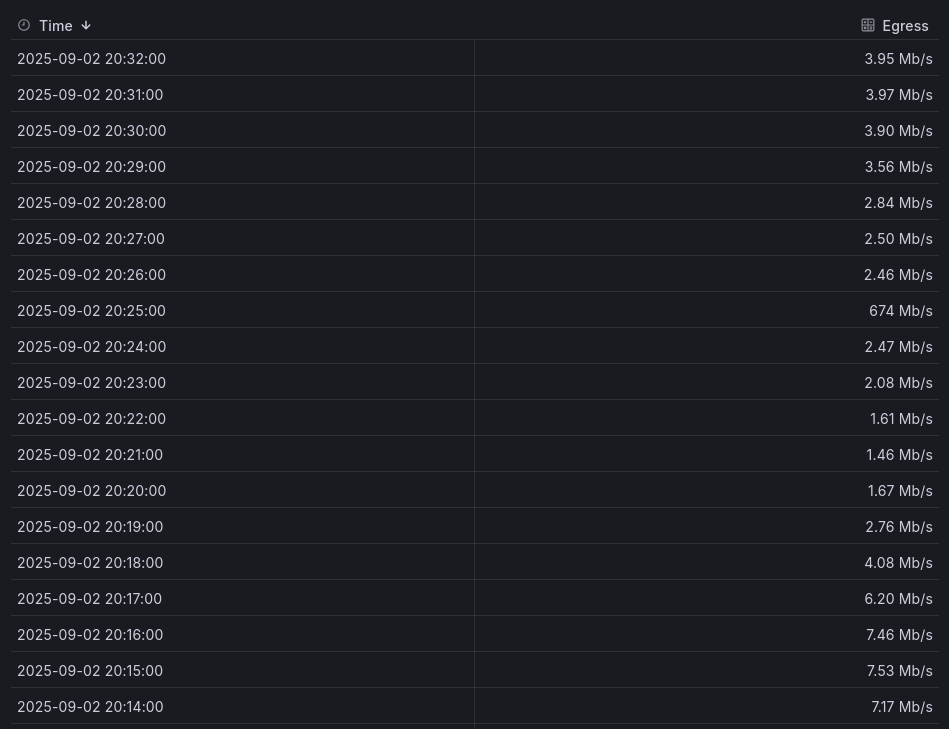
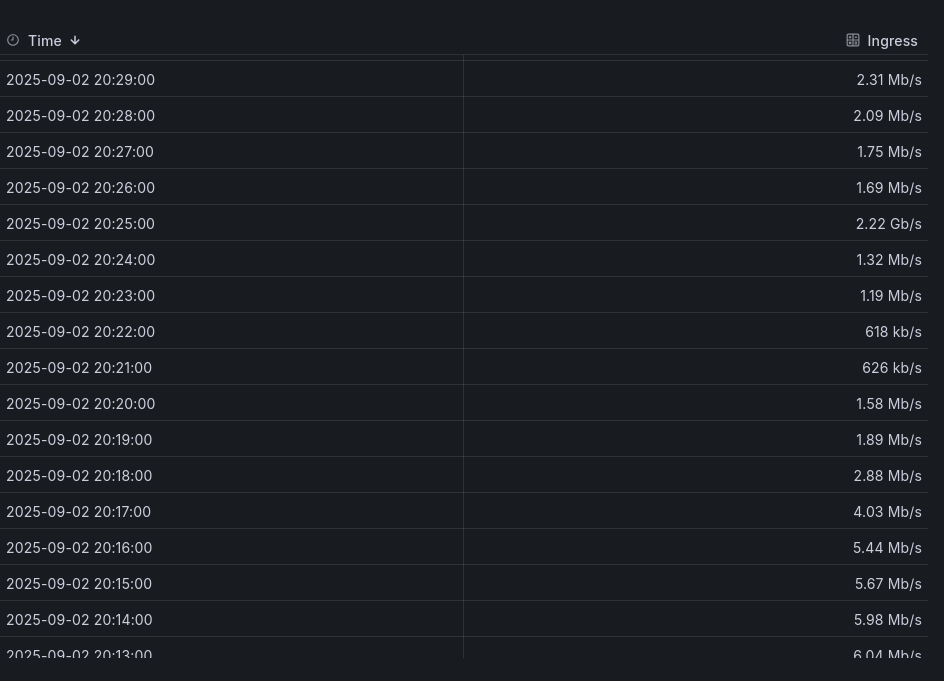
The problem is that every day, sometimes after 8 p.m. and sometimes after 8 a.m., they disconnect briefly. It doesn’t last very long, but it keeps happening, which is lowering my online score.
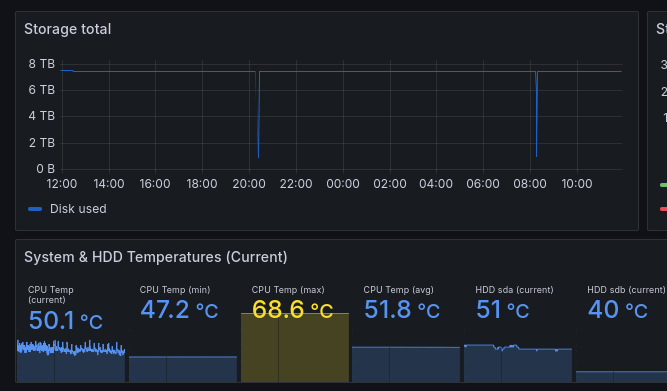
Here is the information on the node.
HDD: TOSHIBA Enterprise Capacity MG10AFA, 22TB (20% full)
Raspberry Pi 4 (with Debian ARM)
1 GB UP/DOWN connection
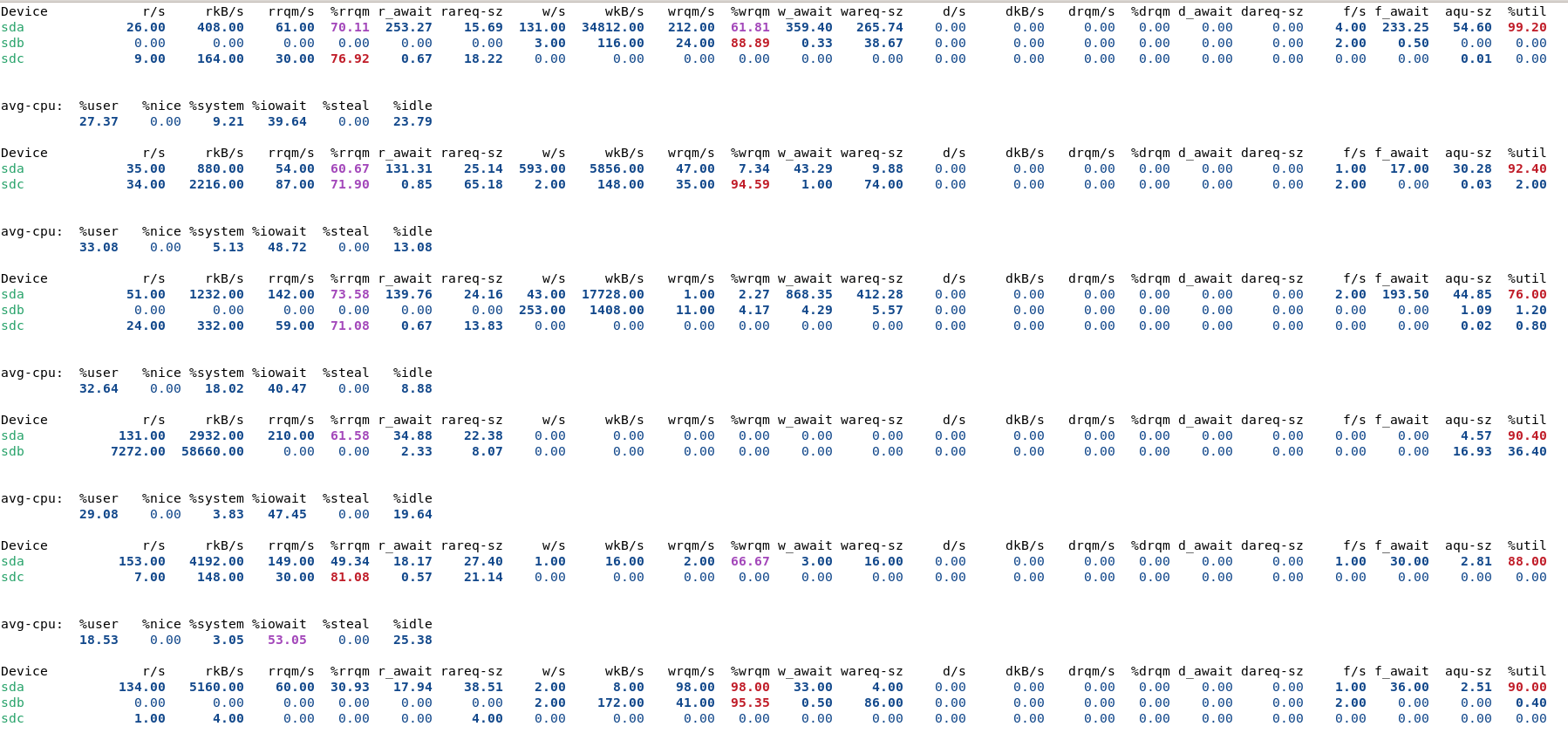
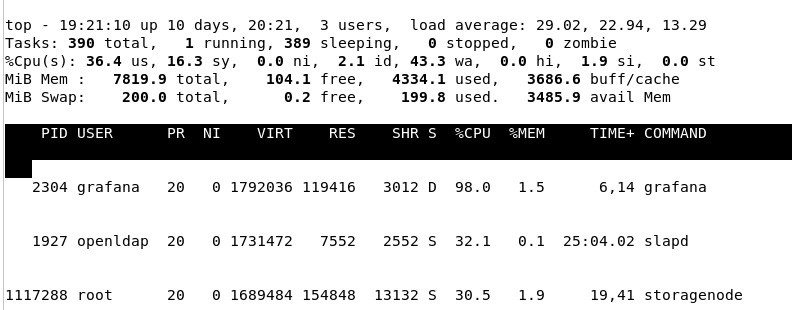
As I thought at first, Promteuse can’t keep up, but in reality, the Storj dashboard has the same information (I think it is not a ISP problem because the Promteuse look on the local network)
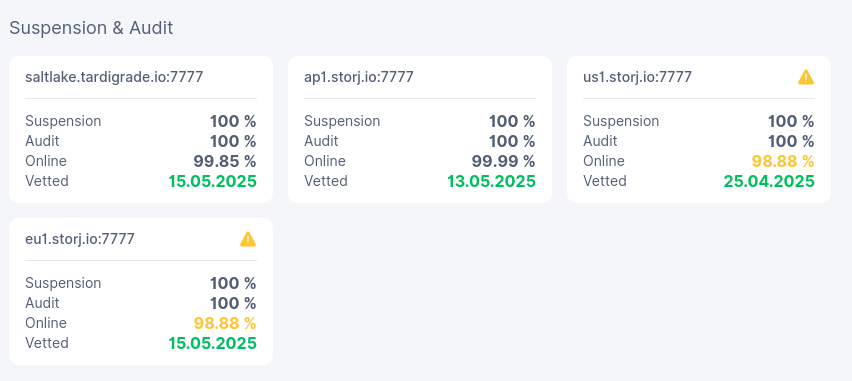
The problem is that I have gone from 100% to 98.88% since migrating to version 1.35.5 and migrating to Hashstore in a week or two (I don’t remember)
There are no problems in the logs, the migration to Hashstore is complete, but the temperature of my HDD has increased by 5°-7° to since I switched to Hashstore, the cabinets that contain the servers is the same temperature as before.
What worries me is that the score keeps going down, which isn’t great for the Storj network (I think if my node disconnected). Are there any explanations or ideas? Why do these disconnections always happen at the same times?
For your information, the server (raspberry pi) remains stable and also the docker image.
Perhaps you have noticed something similar, or it could be explained by the new version 1.35.5 or the switch to Hashstore.
Please let me know what you think. I would lean towards an HDD problem as the temperature has increased, but to be honest, I don’t really know.
PS: Disconnections are between 2 and 10 minutes. Could this disqualify my node over time, or is this time insignificant (if you think about it, a 20-minute disconnection every day adds up to 10 hours, which is enormous)?