Which Windows are you using ?
i use windows 10,…
My 2¢.
Recently I have migrated the node to a new larger disk. The migration was done with rsync, both old and new disks were ext4, same Raspberry pi 4/4Gb running nodes.
The old node was full with 6TB of data written over the course of one year (August 2019 to August 2020).
When I first ran the migrated node I didn’t observe the usual long 100% disk utilization upon the node start. That was very unexpected.
My hypothesis is that over many months the directory structure became heavily fragmented on the old disk.
When one walks the directory tree then the disk has to seek across the whole disk surface in random order. Quite the opposite, in a freshly written disk the data layout in directories more or less correlates with the actual layout on disk and more of these data can be read sequentially.
I have even disabled the bcache caching device to see if I’m missing something, no, the single spinning disk feels totally fine.
1 Like
It could be still the problem with the old HDD.
For the old disk iostat showed a very expected 300 QPS for many hours straight, I don’t see how this load (…:7777/ps reported it as WalkSatellite or something like that) could be attributed to a disk problem.
Of course the storj code might have changed.
Is anyone else still having problems with this and/or has anything been done on the engineering side to improve this situation?
My nodes seem to still have these periodic many-hour disk utilization spikes. Example from the last few days:

These are Linux nodes, all configured the same (each being a SBC with one enterprise drive). I’ve tried playing with with vfs_cache_pressure to try to retain more inodes in cache but in order to retain 100% in RAM I estimate I’d need to have 213GB (max inode count * 0.7KB) for my volume. Also, since the scan is likely done in the same order from pass to pass, there would be little to no benefit if the cache was not able to hold the entirety in RAM.
In normal applications we’d scale across multiple spindles but that either adds local redundant storage or amplifies the system failure rate.
I do like the bcache idea and have used bcache in the past but this does add a requirement on an additional, fast, SSD which my current SBCs cannot supply.
This seems like an engineering issue that we shouldn’t need to worry about on the node operator side of the fence. Curious on others’ thoughts.
2 Likes
I see the same pattern on my nodes. During garbage collection (which seems to start every day around the same time) my drives are on 100% for 1-4 hours. Slowing that down a little bit might not be a bad idea. During normal operation, my disk utilisation is around 10%. So I don’t care if garbage collection would run for 8 hours, if it then only consumes 50% of my drives capabilities.
I doubt you will ever reach max inode count. On my node with 25TB used, only 31M inodes are used and that would, according to your formula, require 21GB of RAM - much more manageable.
My Storj VM has 16GB of RAM, but the host has 106GB. Filewalker runs for about 30 minutes to maybe an hour.
This is my disk IO utilization graph (as seen from the VM) for the last week:
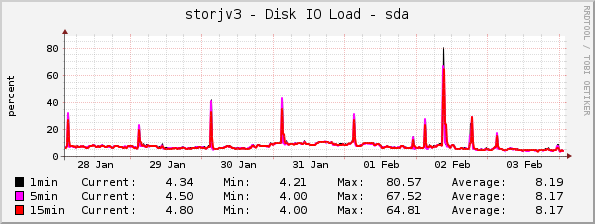
Expanding the highest peak:

2 Likes
This problems has been reported again and again over the last two years in different threads on the forum. We know it doesn’t affect many setups, we know several workarounds, and there is an idea how to improve the situation a lot—though apparently it needs some engineering time.
For those that follow this thread later, there has been some progress on this:
As for me and my SBC-based nodes, I think I need to find a new SBC which can handle more RAM as well as and additional nvme/SSD to improve node performance for this access pattern…