This suggests me to use a virtual disk file on the normal disk. This it pretty the same.
You can do this now, then check how much it is better than a normal disk.
1 Like
Yes and no, most files systems are very inefficient at handling millions of small files. That’s what databases are for. But I agree the Bucket have diminishing returns past a certain point (when the file get large enough of if you have a reasonable number of files)
That’s the neat part, 0 fragmentation as you bucket contain (bucket size / max single file size) any deleted files is replaced by a new one on the same blocks so no fragmentation can occur (at the loss of some empty bits)
I see it more as “Storing the large files on the filesystem and the small files in dedicated databases”. My storage node is large and fragmentation is very hard to contain as small files get mixed with large ones.
But I know that Storj philosophy if mor toward lot’s of small/medium nodes and I’m ok with that. It’s more a though and experience feedback than a feature request ![]()
1 Like
I just created a fresh new node 1 month ago, all default parameters (Windows, NTFS 4k Clusters) and I now have 53GB stored.
This is what the drive clusters looks like:

The fact that Storj create a 4MB empty file, write what it need inside then trim it to the correct side is very bad for data allocation. It should create a file the size of the final data, not an arbitrary number.
1 Like
This would only work if the entire size is pre-allocated. But yeah, that would be quite nice.
Oof, yeah. I’m pretty sure this used to be smaller (I think something around 256KB). But 4MiB makes no sense as pieces can never be more than 64/29 ~= 2.2MiB. This setting should at most be 2.5MiB if you want to keep a small margin. You can change it in the config.yaml. Smaller might not be ideal either as that might fragment files as they come in. It would be really great if the uplink could just communicate the actual piece size before sending, so we don’t have to use one universal setting to begin with.
4 Likes
setting preallocate to small might also leave you with near useless capacity between the larger blocks.
i’ve been running on the 4MiB preallocate setting with ZFS for like 1½ year now, my pool fragmentation is at 53% currently… which isn’t great but so far as i understand, its fine…
don’t remember how we ended with the 4MiB number back then…
of ZFS being Copy on Write might also make it less of a factor.
also keep in mind HDD’s makes a lot of optimization with how the put down blocks of data and how to best retrieve i’m unsure if the “block map” you @JDA showed really indicates any issues.
it is a cool way to visualize it and might be very useful… but its also takes a lot of training for a doctor to evaluate an xray.
plus its a very new node, it would be interesting to see similar data from much older windows nodes running the same or similar setups for comparisons.
but yeah … maybe 4MiB is a bad setting… i’ve been running it and maybe even promoting it for lack of better options…
any optimization would be great, but at present i duno why i would switch, since it has been working fine thus far…
i’m pretty sure one wants to leave a certain sized gap for other smaller blocks to fit in-between the largest storj blocks, how much… no real clue…
doubt i would have started using it at 4MiB without a semi good reason or argument for why it was a good choice, but can’t remember so its a mute point really… lol
maybe somebody else wiser on this could enlighten us.
1 Like
OK I have a slightly older node (10 months) with 1.45TB of data and after 4h I managed to get a defrag report.
Note that I defragmented this volume a couple of time around 3 months ago
Stats:
Unfragmented: 4 377 037 items
Fragmented: 322 718 items
Gaps: 186 392 gaps
“Big picture”
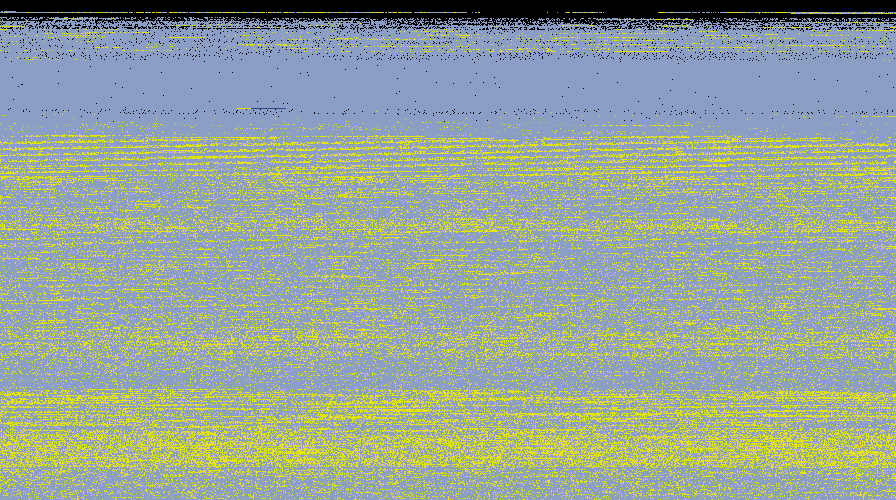
Zoom:

PS: I can’t do the same on my big node, it’s over 17TB of data and the reports will take weeks to generate.
3 Likes
I decided to check the ap1 folder for my oldest node for fragmentation. This is kind of a worst case scenario on ext4, as it’s a multiuse array with several nodes and other things that is usually around 90% full (and has been over 95% full at times).
Total/best extents 3925124/3626416
Average size per extent 384 KB
Fragmentation score 1
[0-30 no problem: 31-55 a little bit fragmented: 56- needs defrag]
This directory (redacted) does not need defragmentation.
So doesn’t seem to be an issue on ext4 at least.
As a (kinda former) (a bit drunk at this specific moment) data scientist I’d warn against trusting averages. The average might be decent, but where it actually matters (i.e. the directory entries), fragmentation might be huge. After all, if you have a set of million elements, one of them 1M, all others at 1, the average is still “just” 2.
1 Like
The worst files were listed and had 16 extents… So I’m not too worried about that.
1 Like
my zfs is also doing fine, its been hosting storj for 1½ year.
has been running around 50-95% full with changes as more storage was added.
did push it to 98% but that was to much for zfs, then i had to stop ingress and delete other stuff to free up space enough that it would work correctly again.
fragmentation is fine… i’m at 50% currently which means 50% of the holes doesn’t have enough space for a full record, or thats how i remember it… the zfs fragmentation number is a bit of a complex size when one digs into the details.
works fine for now, but i do have my eye on it…
fragmentation is also very much a result of limited capacity… just don’t go to close to often…
caches and such can also help.
been wanting to run zfs with sync always, but that is very demanding on the hardware.
sync always with a proper dedicated ram based or fast enterprise ssd slog, is the recommended way to avoid or limit fragmentation on zfs.
basically the idea is that the data is written to the SLOG and then every 5 sec is written to raid / hdd’s in one sweep.
I’m still running Storj + Chia, so I’m always close to 90% and remove Chia plots when it goes over. Though I don’t really know why I still bother with Chia, it practically earns me $0. But yeah… my setup seems to be a worst case scenario because of this… and yet it doesn’t seem to be a problem.
Of course it’s very file system dependent. And my setup is ext4 with a 1TB read/write cache, which probably also helps.
1 Like
That’s for sure fragmentation is extremely related to the filesystem
NTFS is really old… maybe using the much newer ReFS would be a better option for windows based SNO’s.
do keep in mind one cannot boot of a ReFS storage, but it is made for data storage.
while NTFS was more the replacement filesystem from when microsofts customers went from msdos to windows … i really hope NTFS has gotten updated since then lol…
from 2012 so only 10 years old.
lol 29 years old…
My sysadmin friend said he’d never let ReFS near his production systems. This thing breaks constantly.
4 Likes
i guess i should have written might be… lol because i never actually used it myself.
1 Like
And any one cared for this since?
because i had clean formatted 4TB disk, with 2TB of storj, finished usedspace FW under 1h, so i was jumping and singing happily, and now 4-5 days later its staring to be slower and slower by the day. Wonder if writing new files by storagenode.exe is optimised to not cause more fragmentation…?
and not only database files defragmentation is there a must i see,
i defragmented a MFT alone by ultraddefrag “optimize MFT” and only that gave my disk a boost again under bare metal, its back to normal again. i forget that after copying files back, to freshly formated disk. But it was fast without this. Well now MFT weights 10GB and are together now, hope it will last some longer that 4 days. So also to prevent that in future, a “MFT zone” - some defragmenters allow to rezerve more space for MFT, didn’t tried this yet.
I use NTFS under windows.
Edit: I used Contig.exe and a file of 245KB from 16.06.2024 is in 1 fragment. (after disk defrag)
but a file in same blob 2a folder from 26.06.2024(new files after defrag) is in 2 fragments, and the disk is half empty, is it realy there was no space to put it in 1 fragment?
looks like new files that lands, by default are fragmented on half empy disk, thats no good?@Alexey okay many files after 26.06 are also in 1 fragment, but still would like to bring what BS and JDA said to Your attention
what do you want my 4 TB node contains 16.1M files, it is crazy ammount, i remember there was like 3-6m of files, but file sizes gone so small.
Does fragmentation matter that much here? The files are written in one go and never modified, so, unless the file system is really full, it should be able to fit the file without fragmenting it. Files are read in a random way anyway (you don’t know which files the customers are going to download), so that does not matter.
Oh, and the “big file with small files inside it” approach most likely would not work on zfs, the big file would just end up fragmented.
2 Likes
Yes, the filesystem is mostly full in most cases. Also if it matters then for MFT, and database files for sure i see. I keep database files together with storj folder with blobs. To be on 1 disk. They work fast really if not fragmentted, opening a storj dashboard is significantly faster than before.
i dont even know how to do it on windows 10, or ntfs.
yes, constant deletes of unmodified files and filling the gaps causes fragmentation.
for filewalks it matters and for dbs also. MFT same. it will be scattered over the whole disk.
with 2 filewalkers running at the same time, dont even think about defragging 8TB even with ram-cache it cloggs the whole system.
i see myself taking the node offline and trying to run a defrag in less than 10 days.
and on systems with low ram (8GB is low) swap will stress the OS ssd.