These are unrelated activities. You can change the database location, moving databases to that location, it requires to restart the node. The MND will show the result, handled by storagenode in question (via their API).
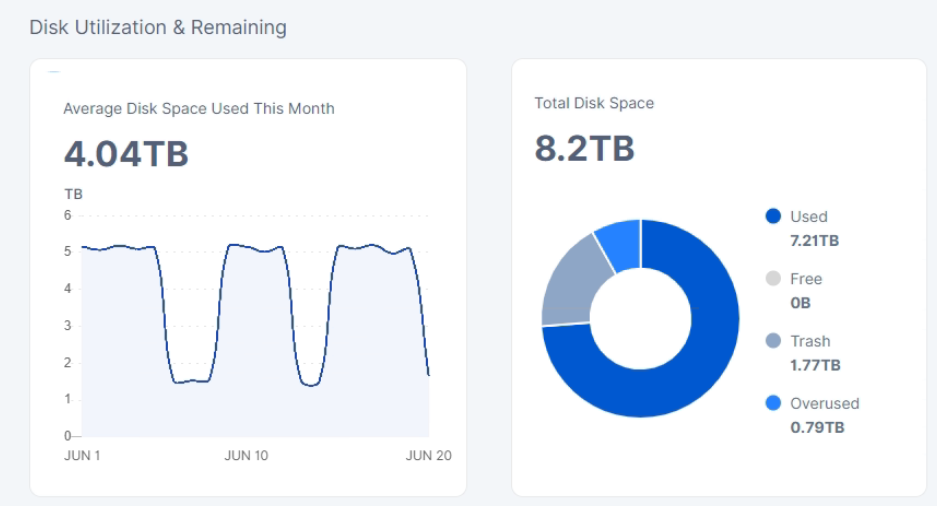
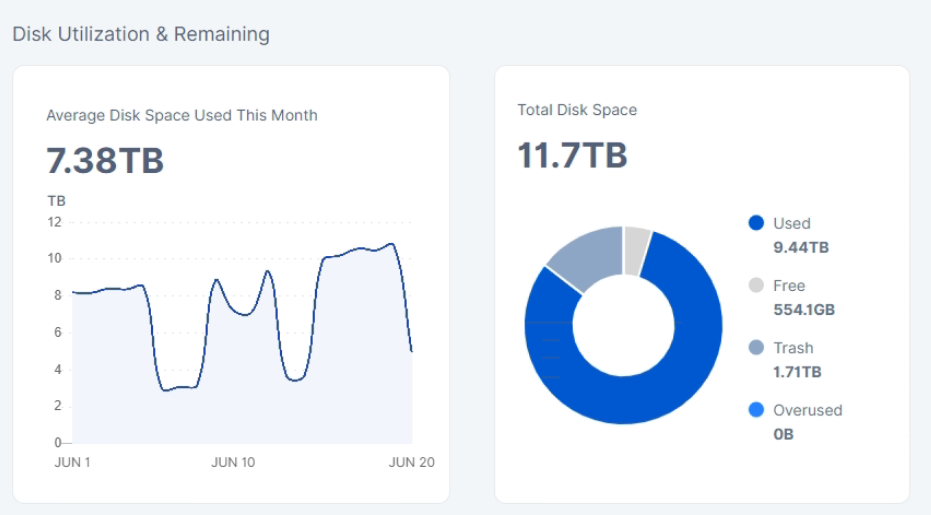
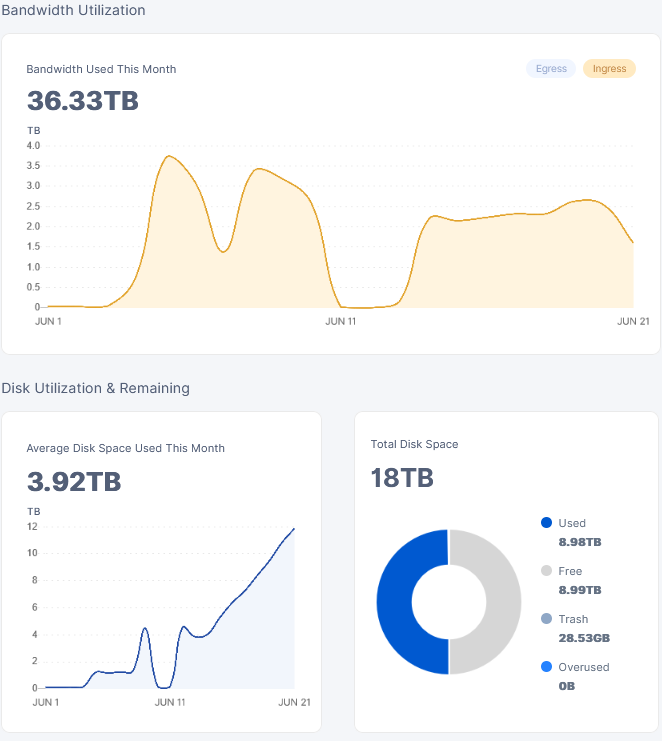
in the config the size is set at 11.7TB
but on this one windows is having a hard time saying the drive is full:
it seems all my disk have some sort of weird discrepancy that i cant figure out.
they have done file walkers - but i will do another right now by restarting nodes.
The difference between OS reporting and the dashboard reporting could be caused by several issues:
you use a filesystem with a big cluster size (any bigger than 4kiB). On Windows you can see it in the folder properties - it shows the folder size and the size on the disk;
your OS reports used space in binary measure units (MiB, GiB, TiB, i.e. base 2), but the dashboard uses SI measure units (base 10);
you have issues with a used-space-filewalker (you have errors related to a filewalker in your logs) or it’s disabled on start (it’s enabled by default).
Yes, it’s finished for all trusted satellites. If you do not have errors related to databases in your logs, then your dashboard should show correct numbers.
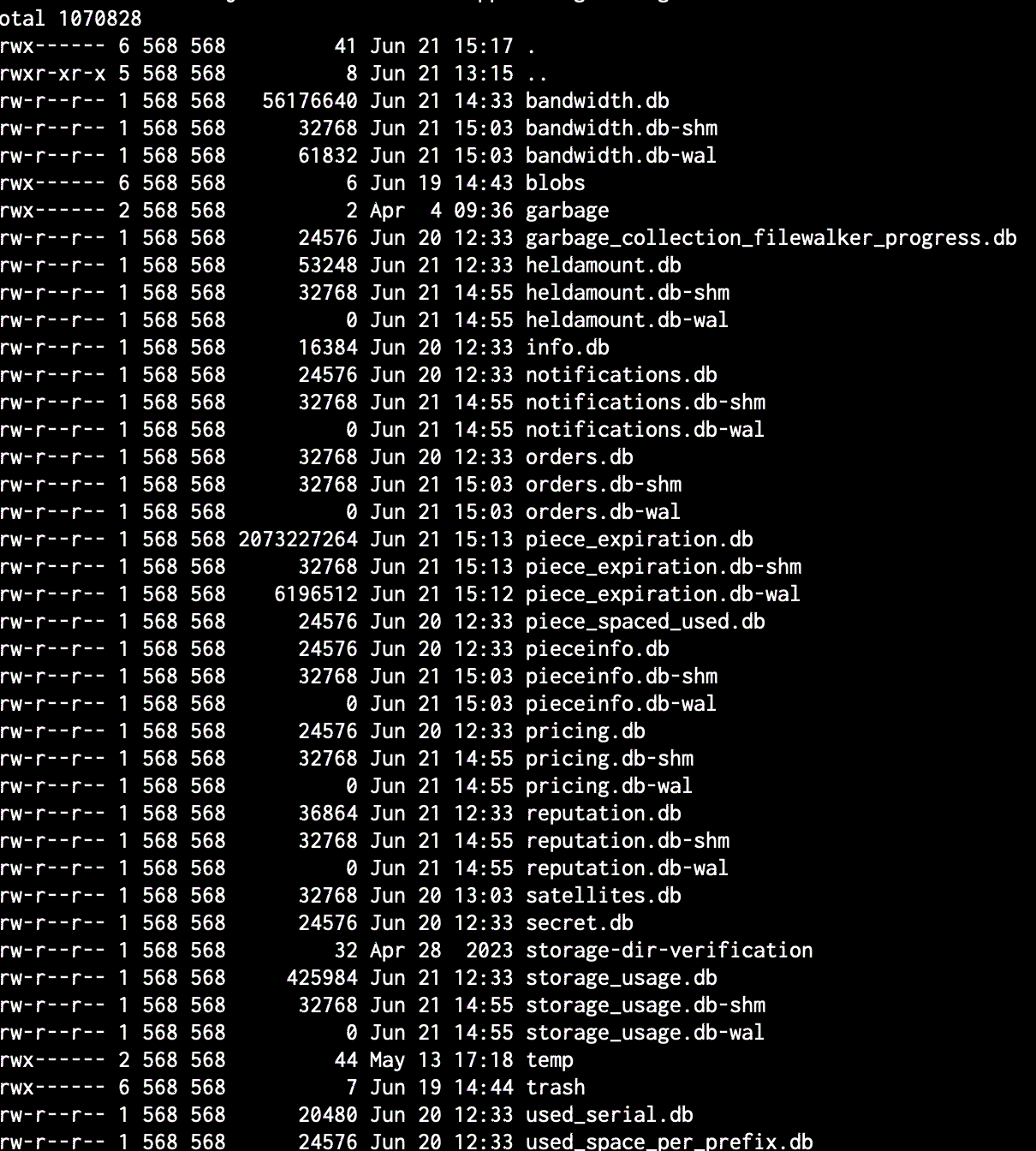
Which I’m not sure how to fix through TrueNAS Scale. As of now Storj has used 100% of the allocated data but does not recognize over 2/3 of it. I found this folder with a bunch of databases in it
So… I recently added another hard drive to both my nodes that increased them to 18TB (which filled completely yesterday) I restarted my nodes and the dashboard now says there is half the amount of stored data. When I check the drives, its reading full… Nodes were originally 9TB and I increased them to 18TB once it filled up. Maybe I partitioned them incorrectly? Any help would be greatly appreciated!
so instead, I tried to edit the config.yaml and set the path to the log file and upon restarting the docker container the node never fully restarted. For now I’ve reverted the config.yaml file back. Then I checked the last 20 lines of the log once restarted and its just showing upload data…
After reading a few posts in the forum, sounds like its an issue with the firewalker process? With this influx of test data, my node filled up within a matter of days and upon reboot that process had to start again is my guess? I’ll leave the node on for a few more days and see what happens…
The same way - you need to move databases to a less used dataset or to the SSD if you have it. Some uses even USB sticks, if they don’t mind to lose the stat with that stick…
The best would be to add an SSD as a special device as many suggested, since the TrueNAS Scale uses ZFS.
sudo docker logs storagenode 2>&1 | grep "database is locked"
You likely tried to specify the host path, right? It should be a path inside the container, the easiest one is to specify it like
log.output: /app/config/node.log
then the log node.log will be there:
/mnt/storjdata/node.log
It could be, but since you have a little different issue:
which suggests that your node has issues with the databases, either with their locks or corruption or both. The failed filewalker is another set of the problems, but first you need to solve an issue with the databases.
Seriously??? That is the best answer? I thought Storj was to be ran on “spare hardware”? For a system that hasn’t even paid out $100 in a year you guys sure have some flawed hardware demands.
It’s on spare hardware. However, if the spare hardware cannot keep up there are workarounds.
One of them - move databases to a less used disk. Unfortunately I do not have any other suggestion right now.
My DBs are on HDD too, and one of the node has had issues with a “database is locked” errors, which I never saw for the last several years.
I know, that’s mostly related to the high throughput from SLC and that we found this issue with a databases become happen much more often only recently.
As a result - not updated databases and wrong stat on a piechart on the dashboard.
However, no better solution so far.
Yes, that is the answer.
“Spare hardware” doesn’t mean “spare crap hardware”, it’s just we’ve been getting away with that for a long time.
Look, I understand your frustration. The network is being pushed very hard right now so naturally hardware demands also went up. It appears the best thing about stress testing Storj like this was that they discovered choke points and possibly some bugs in the current software design. They won’t be fixed overnight.
In the mean time, a possible solution for your problem (call it a “work around”, if you will) has been suggested by Alex.
It is not a very difficult to implement (in many, but certainly not all circumstances) and not too expensive either (you can get a 64 GB SSD for fairly cheap these days).
If it’s any consolation, you’re not the only one who’s had issues (I currently have a pieces.scan running on a node that’s been going on for 5 days and counting!). This is not a daytime job for anyone (not even @Th3Van!), it’s a good opportunity to learn to tweak and fiddle, make preemptive adjustments to other nodes you may be running or thinking of running and if it all gets too much for you and you decide to quit or the node dies…. well, it’s not the end of the world