Does your node receives bloom filters from the satellites? You need to search in your logs for piecestore:retain or retain they shows receiving of bloom filters.
For their processing there are should be lines
gc-filewalker (I believe only for piecestore)
for hashstore something like INFO hashstore iterated pieces for retain {"Process": "storagenode", "satellite": "121RTSDpyN...", "duration": "45.12ms", "pieces_checked": 1420551} and INFO hashstore queued pieces for trash {"Process": "storagenode", "satellite": "121RTSDpyN...", "pieces_queued": 1422, "bytes_to_reclaim": 421890021},
for the filter processed INFO retain bloom filter process completed {"Process": "storagenode", "Satellite ID": "121RTSDpyN...", "duration": "1m12s", "status": "success"}
The logs show reclaim and compaction tasks running without any errors. retain was only found for us1, but I recreated the container this morning, so maybe I just need to wait a bit longer.
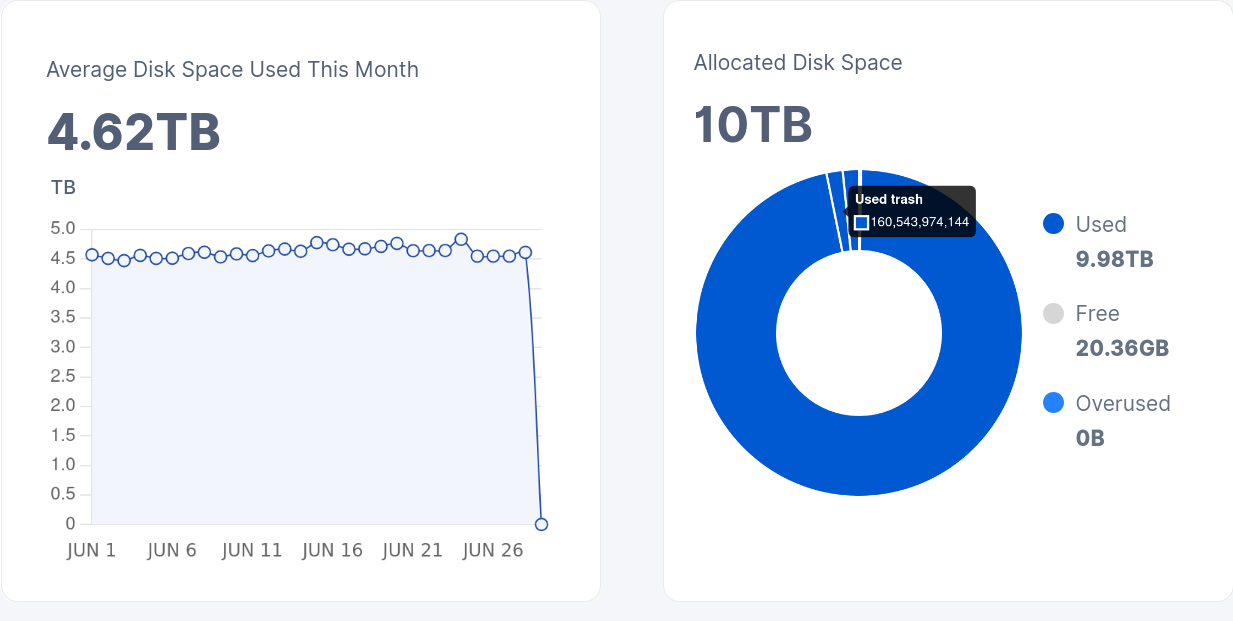
I also found some interesting data when comparing the folder sizes across nodes using du -sh:
ap1 - Average disk space: 161 GB, du -sh: 204G
us1 - Average disk space: 3.42TB, du -sh: 3.6T
eu1- Average disk space: 1.01 TB, du -sh: 5.3T
Also, the db folder on ap1 and eu1 has an excessive amount of .dat files—way more than any other node:
ls qstuylguhrn2ozjv4h2c6xpxykd622gtgurhql2k7k75wqaaaaaa/ | wc -l
120
ls v4weeab67sbgvnbwd5z7tweqsqqun7qox2agpbxy44mqqaaaaaaa/ | wc -l
36
I have a 2GB log limit set. Right now, the earliest event is 2026-06-26t00:15:14z info piecestore downloaded, and because of that, running grep for ‘retain’ only shows results for saltlake:
I’ll increase the log size, but it looks like ap1 wasn’t even there, and we can’t tell about eu1 anymore. However, the garbage and reclaim sizes are too small for such a big discrepancy.