Уже почти месяц не могу ноду под докером запустить.
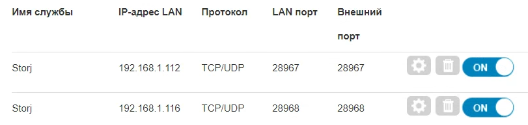
Если я пытаюсь пробросить 28968 to 28968, то роутер не дает этого сделать

Если я меняю проброс 28967 to 28968 на 28968 to 28968, дэшборд сообщает offline и misconfigurated
20 строк лога:
2023-02-03T09:57:58.463Z INFO Event collection enabled {"Process": "storagenode", "instance ID": "12MkEbqLJLpAMesAYmxtvic2WGzBR9niP5PuX6A2pVfC6t1SJeL"}
2023-02-03 09:57:58,464 INFO success: processes-exit-eventlistener entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
2023-02-03 09:57:58,465 INFO success: storagenode entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
2023-02-03 09:57:58,465 INFO success: storagenode-updater entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
2023-02-03T09:57:59.385Z INFO db.migration Database Version {"Process": "storagenode", "version": 54}
2023-02-03T09:58:00.076Z INFO preflight:localtime start checking local system clock with trusted satellites' system clock. {"Process": "storagenode"}
2023-02-03T09:58:01.053Z INFO preflight:localtime local system clock is in sync with trusted satellites' system clock. {"Process": "storagenode"}
2023-02-03T09:58:01.054Z INFO bandwidth Performing bandwidth usage rollups {"Process": "storagenode"}
2023-02-03T09:58:01.057Z INFO Node 12MkEbqLJLpAMesAYmxtvic2WGzBR9niP5PuX6A2pVfC6t1SJeL started {"Process": "storagenode"}
2023-02-03T09:58:01.057Z INFO Public server started on [::]:28967 {"Process": "storagenode"}
2023-02-03T09:58:01.057Z INFO Private server started on 127.0.0.1:7778 {"Process": "storagenode"}
2023-02-03T09:58:01.057Z INFO failed to sufficiently increase receive buffer size (was: 208 kiB, wanted: 2048 kiB, got: 416 kiB). See https://github.com/lucas-clemente/quic-go/wiki/UDP-Receive-Buffer-Size for details. {"Process": "storagenode"}
2023-02-03T09:58:01.059Z INFO trust Scheduling next refresh {"Process": "storagenode", "after": "4h42m49.563511092s"}
2023-02-03T09:58:01.060Z INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "12rfG3sh9NCWiX3ivPjq2HtdLmbqCrvHVEzJubnzFzosMuawymB"}
2023-02-03T09:58:01.090Z INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "12tRQrMTWUWwzwGh18i7Fqs67kmdhH9t6aToeiwbo5mfS2rUmo"}
2023-02-03T09:58:01.096Z INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE"}
2023-02-03T09:58:01.101Z INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2023-02-03T09:58:01.104Z INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S"}
2023-02-03T09:58:01.122Z INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2023-02-03T09:58:46.473Z ERROR nodestats:cache Get stats query failed {"Process": "storagenode", "error": "nodestats: EOF; nodestats: EOF; nodestats: EOF; nodestats: EOF; nodestats: EOF; nodestats: EOF", "errorVerbose": "group:\n--- nodestats: EOF\n\tstorj.io/storj/storagenode/nodestats.(*Service).GetReputationStats:74\n\tstorj.io/storj/storagenode/nodestats.(*Cache).CacheReputationStats.func1:152\n\tstorj.io/storj/storagenode/nodestats.(*Cache).satelliteLoop:261\n\tstorj.io/storj/storagenode/nodestats.(*Cache).CacheReputationStats:151\n\tstorj.io/storj/storagenode/nodestats.(*Cache).Run.func2:118\n\tstorj.io/common/sync2.(*Cycle).Run:99\n\tstorj.io/common/sync2.(*Cycle).Start.func1:77\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75\n--- nodestats: EOF\n\tstorj.io/storj/storagenode/nodestats.(*Service).GetReputationStats:74\n\tstorj.io/storj/storagenode/nodestats.(*Cache).CacheReputationStats.func1:152\n\tstorj.io/storj/storagenode/nodestats.(*Cache).satelliteLoop:261\n\tstorj.io/storj/storagenode/nodestats.(*Cache).CacheReputationStats:151\n\tstorj.io/storj/storagenode/nodestats.(*Cache).Run.func2:118\n\tstorj.io/common/sync2.(*Cycle).Run:99\n\tstorj.io/common/sync2.(*Cycle).Start.func1:77\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75\n--- nodestats: EOF\n\tstorj.io/storj/storagenode/nodestats.(*Service).GetReputationStats:74\n\tstorj.io/storj/storagenode/nodestats.(*Cache).CacheReputationStats.func1:152\n\tstorj.io/storj/storagenode/nodestats.(*Cache).satelliteLoop:261\n\tstorj.io/storj/storagenode/nodestats.(*Cache).CacheReputationStats:151\n\tstorj.io/storj/storagenode/nodestats.(*Cache).Run.func2:118\n\tstorj.io/common/sync2.(*Cycle).Run:99\n\tstorj.io/common/sync2.(*Cycle).Start.func1:77\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75\n--- nodestats: EOF\n\tstorj.io/storj/storagenode/nodestats.(*Service).GetReputationStats:74\n\tstorj.io/storj/storagenode/nodestats.(*Cache).CacheReputationStats.func1:152\n\tstorj.io/storj/storagenode/nodestats.(*Cache).satelliteLoop:261\n\tstorj.io/storj/storagenode/nodestats.(*Cache).CacheReputationStats:151\n\tstorj.io/storj/storagenode/nodestats.(*Cache).Run.func2:118\n\tstorj.io/common/sync2.(*Cycle).Run:99\n\tstorj.io/common/sync2.(*Cycle).Start.func1:77\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75\n--- nodestats: EOF\n\tstorj.io/storj/storagenode/nodestats.(*Service).GetReputationStats:74\n\tstorj.io/storj/storagenode/nodestats.(*Cache).CacheReputationStats.func1:152\n\tstorj.io/storj/storagenode/nodestats.(*Cache).satelliteLoop:261\n\tstorj.io/storj/storagenode/nodestats.(*Cache).CacheReputationStats:151\n\tstorj.io/storj/storagenode/nodestats.(*Cache).Run.func2:118\n\tstorj.io/common/sync2.(*Cycle).Run:99\n\tstorj.io/common/sync2.(*Cycle).Start.func1:77\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75\n--- nodestats: EOF\n\tstorj.io/storj/storagenode/nodestats.(*Service).GetReputationStats:74\n\tstorj.io/storj/storagenode/nodestats.(*Cache).CacheReputationStats.func1:152\n\tstorj.io/storj/storagenode/nodestats.(*Cache).satelliteLoop:261\n\tstorj.io/storj/storagenode/nodestats.(*Cache).CacheReputationStats:151\n\tstorj.io/storj/storagenode/nodestats.(*Cache).Run.func2:118\n\tstorj.io/common/sync2.(*Cycle).Run:99\n\tstorj.io/common/sync2.(*Cycle).Start.func1:77\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75"}
Если при пробросе 28967 to 28968 я меняю команду запуска контейнера на
docker run -d --restart unless-stopped --stop-timeout 300 -p 28967:28967/tcp -p 28967:28967/udp -p 127.0.0.1:14003:14002 -e WALLET="0x867xxxx" -e EMAIL="xxxx@gmail.com" -e ADDRESS="xxx.xxx.xxx.xxx:28968" -e STORAGE="0.5TB" --mount type=bind,source="D:\Identity\storagenode",destination=/app/identity --mount type=bind,source="D:\Storj4.1",destination=/app/config --name storagenode storjlabs/storagenode:latest
То нода тоже не запускается совсем:
docker: Error response from daemon: driver failed programming external connectivity on endpoint storagenode (206a196680573e4384d9ec951a419e98de14c466c9ce5cb71c0fdcefa2d3f2c0): Error starting userland proxy: listen tcp 0.0.0.0:28967: bind: Only one usage of each socket address (protocol/network address/port) is normally permitted.
Подскажи, пожалуйста, в чем может быть дело? Может можем сделать созвон в зум или энидеск?
С уважением,
Александр