I have a 200/20 Mbps internet connection and a 1Gbps LAN.
Since maybe 2 weeks ago (roughly when 28.4 version became live but that might be just coincidental) my node receives high download traffic. However the percentage of failed download attempts is worryingly high as well (it’s now about 46%, roughly 2/3 of them are context cancelled, 1/2 is stream closed). I’ve already ruled out the disk performance and CPU usage, I’m well provisioned there.
Roughly 1 month ago the traffic was about the same with download failure rate <5%. nstat shows that my 20Mbps uplink is saturated >90% of the time and I suspect many simultaneous download attempts fired at roughly the same time make the whole download process slower for all pieces.
It’d be nice if storjnode did not start the download of a new piece until network utilization started to drop below certain configured throughput (I’d set it to 80% of my uplink capacity). This likely hampers this particular download request but gives all other in flight requests much higher chances to succeed.
WDYT?
Here’s the /funcs for the doDownload since yesterday midday:
This is a result of how the over-provisioning of downloads works. As I’m sure you know more pieces are downloaded then required for each segment and when enough pieces have been downloaded the rest are cancelled. Because your node is bottlenecked on downloads you’re losing that race more often. The problem with the alternative you are suggesting is that if nodes start to reject downloads, there is a chance not enough pieces are downloaded to recreate the segment at which point the download for the customer will fail. This is obviously something that should be prevented.
Rather than having nodes reject the transfer, it would be better if satellites learned what kind of capacity nodes can handle and simply send fewer downloads to nodes which can handle less download traffic. This would require some more intelligence in node selection but is a much more robust solution to this issue.
I’m not saying the node should reject the download rather not start until the uplink capacity is available. And it should be a queue rather than a stack otherwise median latency will benefit but tail latency will degrade considerably and may result in unretrievable pieces.
With my proposal the success rate for saturated node will be higher than with starting the download right away resulting in higher storj overall performance.
Satellites should not participate in this process as they can’t see how their traffic interferes with traffic from other satellites.
I’m not sure what you mean by not start. If you mean wait for other downloads to complete, that will make your piece download waay to slow and it will fail anyway because others would finish much faster. A queuing system would also mean that one slow download on your node slows down all other downloads, which is not at all scale-able.
I’m certain it will not as a result of the problem I just mentioned. Slow uplinks would slow down and queue downloads on all nodes and the entire thing would slow to a crawl.
I think it’s important to realize that while your node may see high failure rates, the downloads are actually working fine for the customer, because enough faster nodes have finished. This isn’t great for you as a node operator, but it’s not a problem for the network because it cuts off the long tail of slow transfers by using over-provisioning.
Satellites are the traffic managers of this network. It is their task to pick which nodes to use for upload and download. This is the only component in the network that can choose to select nodes for the download that have the bandwidth to best serve those downloads. They also know how much traffic was sent to nodes recently and can decide based on that and historic success rates which nodes are most likely to finish the download quickly. If you let the satellites select congested nodes, the only solution is to either do it as is and cut off the congested node in the long tail, which will hit the same nodes over and over. Or you wait for queuing which will slow down the downloads. Or you reject transfers which can in some cases fail the downloads. Making the satellites better predict the amount of traffic nodes can handle and act accordingly is by far the most efficient way to deal with this, which would cause the least slowdown, while also spreading the network load according to capability, preventing high failure rates on individual nodes.
hi @xopok
the community team just checked in with engineering. We’re always try to balance the user experience with functionality and its an ever-moving target during this time.
When we mentioned this issue, it seems the behavior you’re describing is a result of some adjustments and testing thats going on. It may get worse for a little while before it gets better.
They agree with you that the issue is occurring and have placed it on the list of things to look at after we push to production.
I bet your upload speed is causing more failure, but like Bright says, it’s OK. Nothing to worry about because it’s not critical. You’re probably in a higher traffic region as well. I have 900Mb up, and central USA. (i feel like it’s a little harder to complete in this region.) My node has pretty high success rate in 24hrs, only 7%, 15% fails.
Node software should be adjustable. Easy fix. The node can receive a request for download and then pause the download if network download activity is high. The request is in the node queue and responded when bandwidth becomes available. The satellite request is fulfilled and downloads will be cancelled with thresholds is reached.
There should be a node limit set of concurrent/simultaneous downloads available at one time like previously done with uploads. This would queue the request on the node but not affect satellite or client. This would help nodes adjust bandwidth usage. concurrent/simultaneous downloads should be a different number from uploads. As can be seen many internet users have storj download limits of say 10 Mbps vs available uploads of 100 Mbps.
The node will continue to see download context cancelled reports but limiting the number of concurrent downloads may help improve overall node network speeds.
THe other way is to reprogram the router to have traffic control. I think many routers can be programmed to limit bandwidth throughput on a specific IP address in the internal network. You could limit the throughput to 5-7Mbps storj download(network upload) speeds so your overall network has better bandwidth sharing, check your router traffic control for availability.
Node network control may be much easier to do than Storj having to reprogram the node software.
For example, on a dlink router you can enable traffic control and set the mbps limit for a specific internal IP address.
Don’t worry about download failures its the design of the storj system. Eventually you may discover that small files pieces download faster and successfully off your network than large pieces. it’s still a successful process. Higher download success rates would require higher uplink bandwidth and closer distance to the client. at higher costs
The node could pause new downloads if the upload traffic is above 90% of set capacity (so, for a 100mbps connection it would be 90mbps). This way, the downloads that have already started would complete faster and the new one (that was paused) would fail most of the time (but would still succeed if the other nodes with that particular file are even slower).
This would not waste bandwidth on downloads that are very likely to fail due to overloaded connection anyway.
Sure, but it would be even better if the satellite had selected nodes that aren’t congested to begin with. It’s the only solution that would get the customer the fastest results. I don’t think it’s ever acceptable to make a customer wait for queued up downloads on nodes on a system that should be capable of preventing that at all costs. So as long as at least 35 uncongested nodes with pieces for the segment to be downloaded are available, the satellite should strive to select those nodes instead of selecting nodes that will cause the customer to have to wait. In short, preventing is better than fixing after the fact.
I’m not sure what you mean by not start. If you mean wait for other downloads to complete, that will make your piece download waay to slow and it will fail anyway because others would finish much faster. A queuing system would also mean that one slow download on your node slows down all other downloads, which is not at all scale-able.
As others mentioned, “not start” is accepting the request and not sending data until bandwidth is available. It doesn’t mean sending pieces one by one, of course.
I’m certain it will not as a result of the problem I just mentioned. Slow uplinks would slow down and queue downloads on all nodes and the entire thing would slow to a crawl.
Let’s compare the synthetic example in the current state and with the proposal.
Imagine the node with 1MB/s uplink receives 10 download requests 2MB each all at the same time. In the ideal conditions each piece alone is transmitted in exactly 2 seconds, just simple math. However if transmitting them together it takes 20 seconds for each and every piece. Most likely these downloads will be context-cancelled and all this bandwidth (both on the node and on the receiver) will be wasted.
If downloads are only started when there’s an uplink capacity then pieces get downloaded in 2, 4, …, 20 seconds. Some of these downloads will have high chances to succeed.
Some of these downloads will also be context-cancelled for being too slow however for some cancelled pieces the transmission was not even started so less wasted bandwidth (win-win).
They [satellites] also know how much traffic was sent to nodes recently and can decide based on that and historic success rates which nodes are most likely to finish the download quickly.
This is a good observation. Need to take care of each individual satellite not falling into a trap of preferring few fast nodes over many-many slower ones.
Yes it should be chance based. So that slower nodes have a lower chance of being selected but are still selected as well, such that nodes are selected as much as possible within their actual capabilities. Satellites could learn these limits for nodes based on historic behavior.
It wasn’t too bad, but i’m a sysadmin, so i have a bit of previous experience to help. Right now i only have a script for linux systems, and have a few pending pull requests for improvements from the community.
Satellites could learn these limits for nodes based on historic behavior.
I want to look at this situation from a decentralized system perspective.
All nodes in this system want to maximize their profit.
To achieve that every storage node wants to store as much data as it can and also maximize the paid download traffic while minimizing the unpaid (e.g. context-cancelled in the middle of the transfer) traffic. We’ll set unpaid upload traffic aside for the time being as it doesn’t compete for the limited uplink bandwidth.
Every satellite wants to maximize the data durability, upload and download latency and is free to pick storage nodes based on whatever criteria it has.
What I’m trying to say is that these two strategies are not mutually exclusive: storage node can do its best to optimize its success rate (that’s what satellites also want because it positively affects the end-user latency) and satellite will choose best storage nodes for every request.
I think we’re in agreement The only thing I would add to this is that the satellite can’t assume nodes are “behaving”. So the satellite should do what it can to best distribute the load before the node has anything to say about it. And I think in almost all cases it would be possible to prevent the congestion / queuing situation from happening on the node at all. Clearly this is not yet how it’s implemented. But given the choice on where to spend developing effort, I would suggest to upgrade the node selection mechanism on the satellite end before looking at changing how nodes deal with queuing/failing while congested.
As i understanc encryption is made on client side, this mean then if client have 1GB file, he wil need to upload 2,5 GB to nodes. Is it some overkill? today is most slow is client side upload?
That’s correct. But that applies to uploads, we were discussing downloads. It depends of course on the upload speed the customer has. But in order for direct transfers to be possible, the uplink will have to encrypt and erasure encode the data.
To close the loop.
Last week I received a call from my internet provider asking if I’m satisfied with their services and so on and suddenly I negotiated a nice deal to bump my internet speed 5x for a 10% monthly fee increase.
Now I have 1Gbps/100Mbps ADSL and I’m no longer restricted by the uplink capacity.
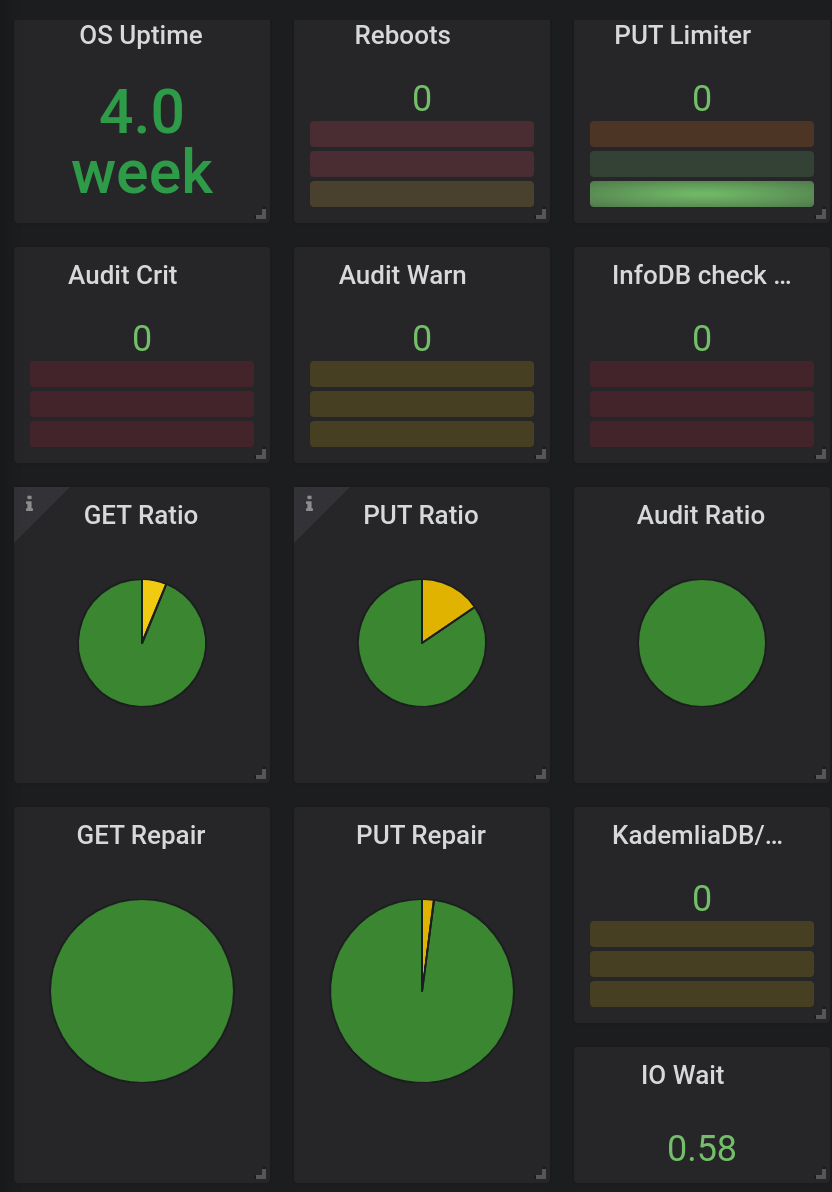
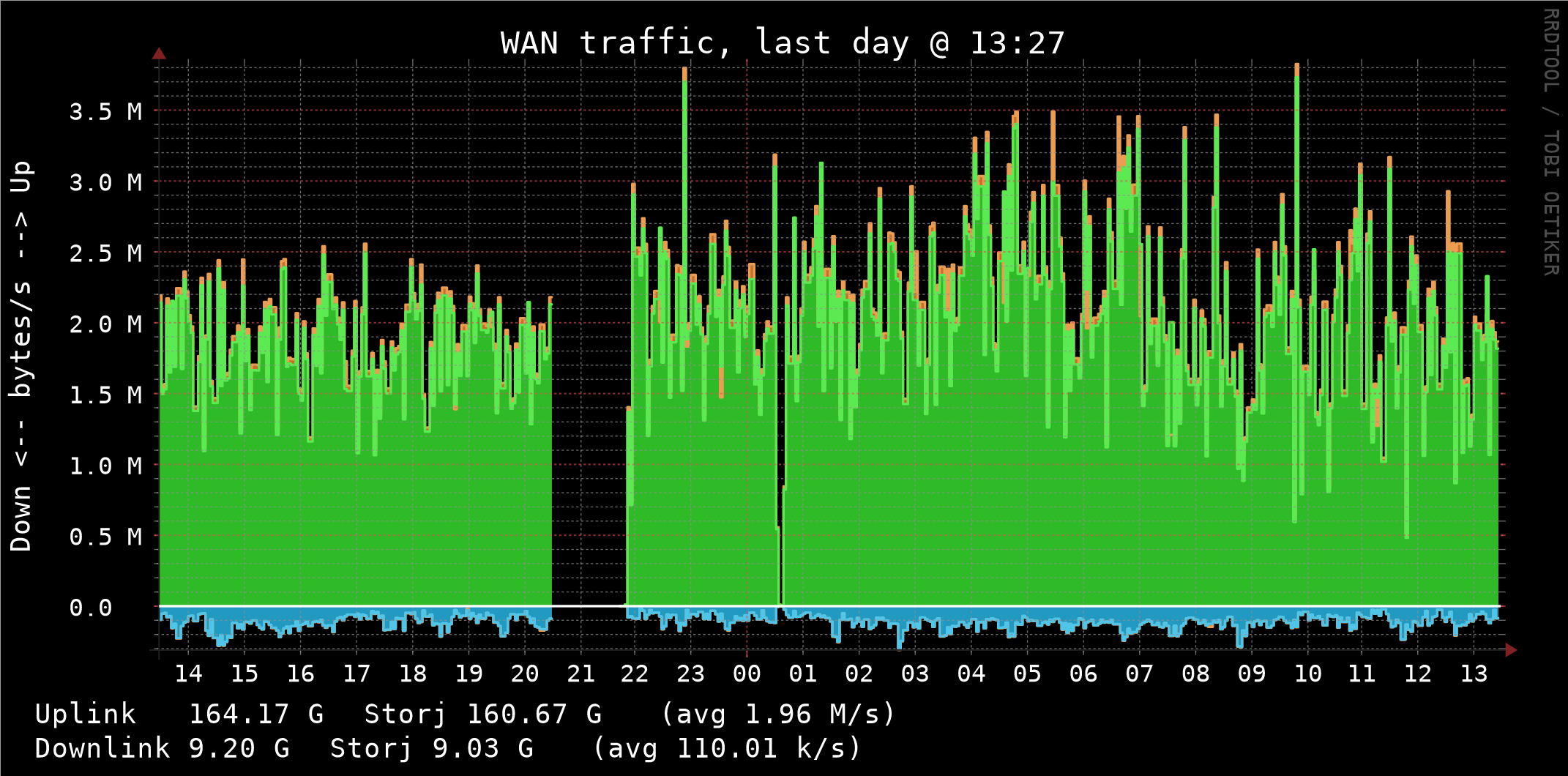
What’s interesting is that my average transferred bytes are not at all far from what I had before. However my current download success rate jumped to 99%.
Here are two charts from yesterday for 24 hours periods (the gap in the middle is for that one hour when I swapped provider’s boxes).
One obvious conclusion is that faster link is very important for the current Storj node implementation especially when demand is high (no guarantee if it’ll be that high later at production).
 upgrading my connection to 100/30 as my 40/10 was completely overloaded!
upgrading my connection to 100/30 as my 40/10 was completely overloaded!