Hi All,
What do you think ? is something broken, or about to break ? looks like an expired piece failed to delete due to DB lock, and then its got confused ?
Node (v1.22.2) is running in docker, on alpine Linux 3.13 virtualised on X64
Node data is on F2FS filesystem, mounted at virtual level on REFS
I’ve only noticed as was about to upgrade to new docker release, and was checking logs and noticed error.
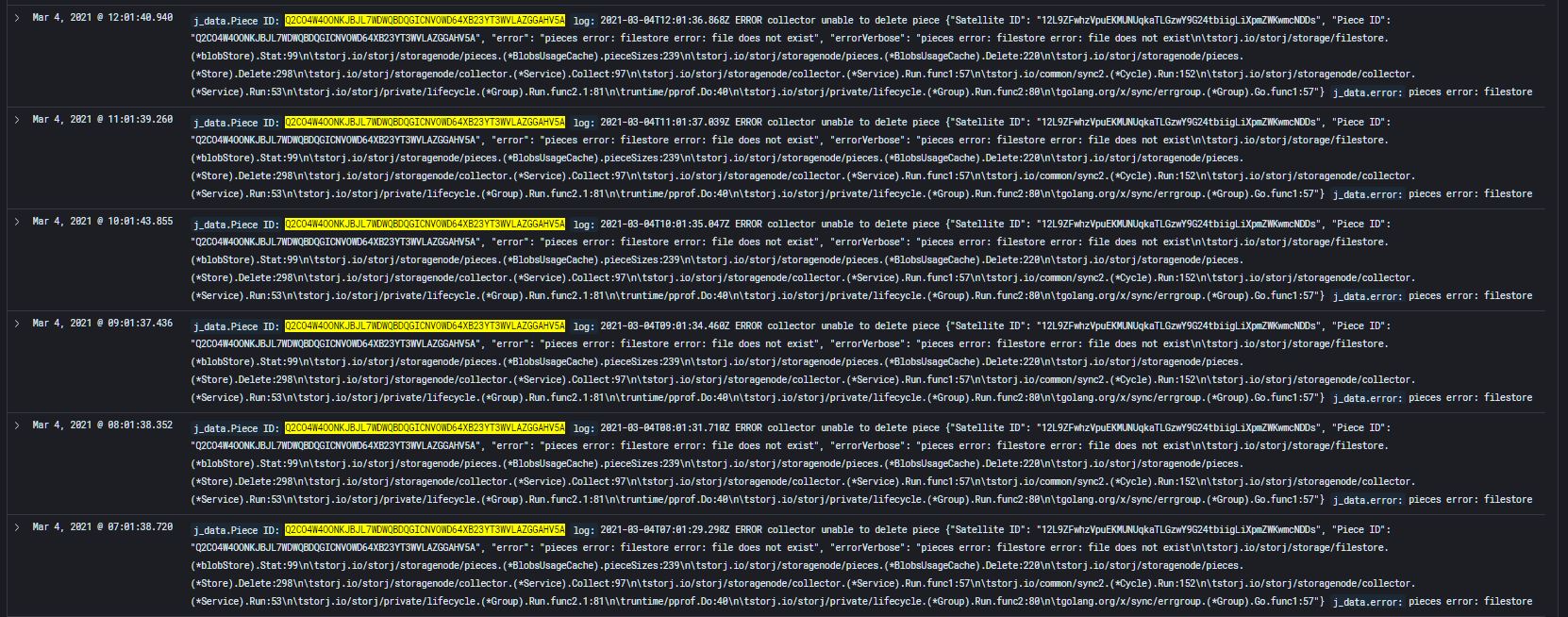
It’s for the same satellite - 12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs
It’s for same piece - Q2CO4W4OONKJBJL7WDWQBDQGICNVOWD64XB23YT3WVLAZGGAHV5A
It repeats in the logs every hour, just this one piece and satellite and started on 25th Feb 2021.
Isn’t there some scrub process, or garbage process to kill this ? ideas on how I could fix 
#Edit, so tracing that piece.
Upload started - Feb 9th 2021
2021-02-09T23:50:57.692Z INFO piecestore upload started {"Piece ID": "Q2CO4W4OONKJBJL7WDWQBDQGICNVOWD64XB23YT3WVLAZGGAHV5A", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Action": "PUT", "Available Space": 758338564160}
Upload Completed - Feb 9th 2021
2021-02-09T23:51:25.896Z INFO piecestore uploaded {"Piece ID": "Q2CO4W4OONKJBJL7WDWQBDQGICNVOWD64XB23YT3WVLAZGGAHV5A", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Action": "PUT", "Size": 2319360}
Request to Delete expired Piece - DB locked - Feb 25th 2021
2021-02-25T00:29:09.470Z ERROR collector unable to update piece info {"Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Piece ID": "Q2CO4W4OONKJBJL7WDWQBDQGICNVOWD64XB23YT3WVLAZGGAHV5A", "error": "piece expiration error: database is locked", "errorVerbose": "piece expiration error: database is locked\n\tstorj.io/storj/storagenode/storagenodedb.(*pieceExpirationDB).DeleteFailed:99\n\tstorj.io/storj/storagenode/pieces.(*Store).DeleteFailed:546\n\tstorj.io/storj/storagenode/collector.(*Service).Collect:103\n\tstorj.io/storj/storagenode/collector.(*Service).Run.func1:57\n\tstorj.io/common/sync2.(*Cycle).Run:152\n\tstorj.io/storj/storagenode/collector.(*Service).Run:53\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2.1:81\n\truntime/pprof.Do:40\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2:80\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:57"}
Repeating hourly error from expired piece, from then until now
2021-02-25T00:30:22.082Z ERROR collector unable to delete piece {"Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Piece ID": "Q2CO4W4OONKJBJL7WDWQBDQGICNVOWD64XB23YT3WVLAZGGAHV5A", "error": "pieces error: filestore error: file does not exist", "errorVerbose": "pieces error: filestore error: file does not exist\n\tstorj.io/storj/storage/filestore.(*blobStore).Stat:99\n\tstorj.io/storj/storagenode/pieces.(*BlobsUsageCache).pieceSizes:239\n\tstorj.io/storj/storagenode/pieces.(*BlobsUsageCache).Delete:220\n\tstorj.io/storj/storagenode/pieces.(*Store).Delete:298\n\tstorj.io/storj/storagenode/collector.(*Service).Collect:97\n\tstorj.io/storj/storagenode/collector.(*Service).Run.func1:57\n\tstorj.io/common/sync2.(*Cycle).Run:152\n\tstorj.io/storj/storagenode/collector.(*Service).Run:53\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2.1:81\n\truntime/pprof.Do:40\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2:80\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:57"}