No. I changed it back. Because it did not work out. Sorry bad sentence
no, there are two parameters - the check interval (which are 1m0s for readability and 5m0s for writeability) and timeouts (1m0s by default).
So, you need to change the timeout (and interval, if it’s lower than a specified timeout)
See
Smr affects performance only when writing.
All info i could find points to cmr.
All that changed was the node fill up and the client version.
Smr was only up to 6TB.
The problem was before the new version - the checker was just hangs forever instead of throw an error, now it’s fixed.
Will try to find out if it is one
My node has stopped again. I re-enabled file scanning when starting node yesterday.
This morning the drive was 100% checking files.
This afternoon I found the node stopped.
I pass a screenshot. It wouldn’t let me copy the text.
The notepad was working very slow, the storageode.log file is 1Gb.

I have tried “chkdsk /f d:” in power shell. There are no errors.
You may try to increase a writeability timeout
its an helium filed wd 120 edgz without trim. most likely cmr…
…but used space and trash never gets aktualised since the update because it cant gather all informations about the milions of 1k files in time.so its caching or filesystem problem. visible trough the timeout, so increasing it is just temporary fix.
Now i have to monitor the used space manualy via windows. Will it crush when it only sees 6 tb used and exeeds free space?
I don’t see either of them.
I appear:
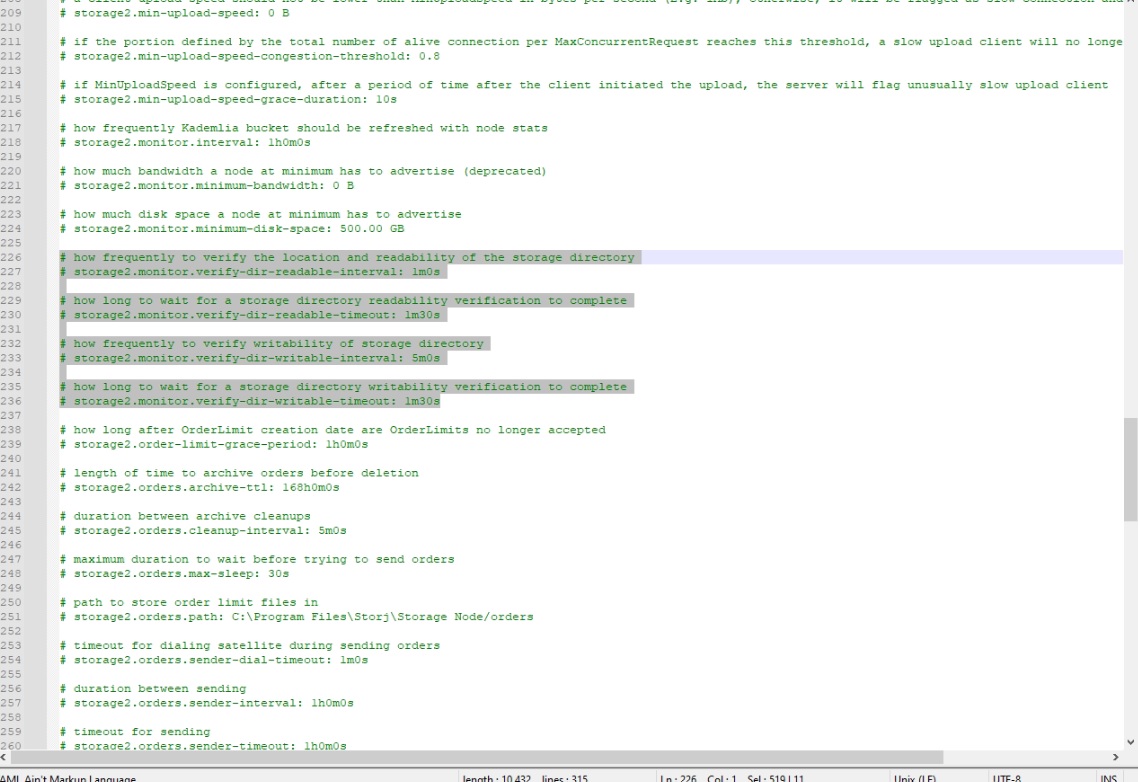
how often to check the location and readability of the storage directory
storage2.monitor.verify-dir-readable-interval: 1m0s
how often to check the writeability of the storage directory
storage2.monitor.verify-dir-writable-interval: 5m0s
do i have to add? “# storage2.monitor.verify-dir-writable-timeout: 1m30s”
do i have to remove #?
I copied the -intervals and pasted them down and replaced “interval” with “timeout”
Working so far.
# is a comment symbol, meaning everything after it is ignored.
You need to add this parameter
without # and without space before the parameter to your config.yaml if it’s missing, save the config file and restart the node.
Hi @Alexey,
I dont have either “storage2.monitor.verify-dir-readable-timeout” or “storage2.monitor.verify-dir-writable-timeout”.
Just have “storage2.monitor.verify-dir-readable-interval” and “storage2.monitor.verify-dir-writable-interval”
Node version is 1.76.2
EDITED:
Just added “storage2.monitor.verify-dir-writable-timeout: 1m30s” in between both parameters:

Monitoring to see if it improves.
PS: Funny enough, this only happens on my multi-disk nodes on Windows (one volume with at least 1 5400rpm CMR, total of 4 disks)
Synology 412+ doesn´t happen (4 disks, one volume, no RAID)
Windows 10 with one 16TB 7200 CMR doesn´t happen.
Could it be you guys tested this on higher spec nodes and forgot about the “little ones”?
The config file is not updating so often like storagenode.exe. But the executable uses missing parameters with default values even if they don’t appear in config. You can use the -help flag to display all parameters, or you can start a new node and copy the config file created. Modify what you want in it and replace the old one, than restart the old node. When I create a new node, I copy the new config to all my nodes, just to have the latest version.
it is not tests it is real life, clients started to realize benefits and loading data to system, it is mostly from EU satellite, not test satellites
Added "storage2.monitor.verify-dir-writable-timeout: 1m30s
" to the configuration file config.yaml .
The error is the same.
The configuration change was not applied. any ideas?
The node was updated to version 1.76.2
Failure:
2023-04-11T21:56:57.557+0200 INFO piecestore upload canceled {“Piece ID”: “HWETPURWBGAYGU27JU3QJCL2DTBDRC7TJKNPG34URCPWM2OIT6PQ”, “Satellite ID”: “12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs”, “Action”: “PUT”, “Size”: 0, “Remote Address”: “142.132.167.251:50594”}
2023-04-11T21:56:57.557+0200 INFO piecestore upload canceled {“Piece ID”: “N3K3MR5OQW44D4I67UF7DDZCNZTL7UBQGY7S3HGXAFIXSHQWVZBA”, “Satellite ID”: “121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6”, “Action”: “PUT”, “Size”: 0, “Remote Address”: “128.140.5.239:61766”}
2023-04-11T21:56:57.557+0200 INFO piecestore upload canceled {“Piece ID”: “OC3F6VMPVB2EHRLKU4LWIXB3FCUEBNDNBJ4CLCICHVHBKVSIC62A”, “Satellite ID”: “121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6”, “Action”: “PUT”, “Size”: 0, “Remote Address”: “128.140.5.236:34454”}
2023-04-11T21:56:57.557+0200 INFO piecestore upload canceled {“Piece ID”: “UAM5APFU3QWO6VP3RYMHVWNHEHVESGTHBBXQKMTR4JLFC5TG4QDA”, “Satellite ID”: “121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6”, “Action”: “PUT”, “Size”: 0, “Remote Address”: “50.7.22.66:36058”}
2023-04-11T21:56:58.036+0200 FATAL Unrecoverable error {“error”: “piecestore monitor: timed out after 1m0s while verifying readability of storage directory”, “errorVerbose”: “piecestore monitor: timed out after 1m0s while verifying readability of storage directory\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func1.1:137\n\tstorj.io/common/sync2.(*Cycle).Run:160\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func1:133\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75”}
yep, you confused writeable and readable.(+ility)
i have still no audit errors, node restarts serveral times a day. but used space in dashboard to low.
had anybody success with the timeouts?
also if im correct, filewalking takes ages because of small files who are moved and deleted furiously so what is the maximum i can increase this timer?
will storj test it and fill up an windows node with 5TB of 1k files and look what happens? and how to increase capability to handle small files?
maybe putting them in an zip or compressed format with no compression but the filesize does not matter that much? will there be an 64bit nodesoftware, since it may better perform?
usualy programmers have lots of small code files maybe? since boosting hardware will not help, that have i tested. (drive still slow in that particular task to gather the folder sizes of big folders?) maybe defragmentation can help, but will take ages also. 80h+ i estimate in my case.
Now I got confused.
The first time it failed to write. The second time it failed to read.
now it is a readability timeout, so not the same.
This one is a bad sign - this is mean that your node is unable to read a small file within 1m0s, this is also mean, that it likely happened for pieces too, so your node could start to fail audits because of timeouts (when the node responses on audit request but cannot provide a piece after 5 minutes timeout, it will be placed into a containment mode and will be asked for the same piece 2 more times with 5 minutes timeout each before considering this audit as failed).
You may increase a readability timeout but also you should increase the readability check interval too, because by default they are equal, so
storage2.monitor.verify-dir-readable-interval: 1m30s
storage2.monitor.verify-dir-readable-timeout: 1m30s
save the config and restart the node.
my Windows GUI node (single CMR, Toshiba 7200) 2TB, Windows docker node (single CMR, WD RED 5400) 7TB, Windows docker node (single CMR, WD RED 5400) 800GB are working fine without modifying of timeouts, so I guess a difference in the setup. As you may see, I also run docker nodes under Windows, so they are a little bit slower than a native, because they uses a network access via 9P protocol (WSL2) to the local disks.
This will slow down your node on writes and reads even more (you need to compress/expand data on the fly), so it will lose race even more and the customers will have a reduced speed as well.
it’s 64 bit software, we do not provide a 32-bit software for Windows at all. I even not sure is it possible to build it for i386.
perhaps it’s related to disk itself or type of the connection (USB1-USB2 will be slow regardless of compute power).
Perhaps it could help if you would have more RAM to allow OS to use more RAM for disk cache.