guys, try to update to 1.77.3. I did it and things seem better now.
1 Like
I have similar problem.
Has been running fine for a long time. Now service is crashing again an again.
OS: Windows
I get a lot of these Fatal errors:
FATAL Unrecoverable error {"error": "piecestore monitor: timed out after 1m0s while verifying readability of storage directory", "errorVerbose": "piecestore monitor: timed out after 1m0s while verifying readability of storage directory\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func1.1:142\n\tstorj.io/common/sync2.(*Cycle).Run:160\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func1:134\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75"}
My config file looks like this:
# how frequently bandwidth usage rollups are calculated
# bandwidth.interval: 1h0m0s
# how frequently expired pieces are collected
# collector.interval: 1h0m0s
# use color in user interface
# color: false
# server address of the api gateway and frontend app
# console.address: 127.0.0.1:14002
# path to static resources
# console.static-dir: ""
# the public address of the node, useful for nodes behind NAT
contact.external-address: 62.66.145.73:28967
# how frequently the node contact chore should run
# contact.interval: 1h0m0s
# Maximum Database Connection Lifetime, -1ns means the stdlib default
# db.conn_max_lifetime: 30m0s
# Maximum Amount of Idle Database connections, -1 means the stdlib default
# db.max_idle_conns: 1
# Maximum Amount of Open Database connections, -1 means the stdlib default
# db.max_open_conns: 5
# address to listen on for debug endpoints
# debug.addr: 127.0.0.1:0
# expose control panel
# debug.control: false
# If set, a path to write a process trace SVG to
# debug.trace-out: ""
# open config in default editor
# edit-conf: false
# in-memory buffer for uploads
# filestore.write-buffer-size: 128.0 KiB
# how often to run the chore to check for satellites for the node to exit.
# graceful-exit.chore-interval: 1m0s
# the minimum acceptable bytes that an exiting node can transfer per second to the new node
# graceful-exit.min-bytes-per-second: 5.00 KB
# the minimum duration for downloading a piece from storage nodes before timing out
# graceful-exit.min-download-timeout: 2m0s
# number of concurrent transfers per graceful exit worker
# graceful-exit.num-concurrent-transfers: 5
# number of workers to handle satellite exits
# graceful-exit.num-workers: 4
# path to the certificate chain for this identity
identity.cert-path: C:\Users\administrator\Documents\identity.cert
# path to the private key for this identity
identity.key-path: C:\Users\administrator\Documents\identity.key
# if true, log function filename and line number
# log.caller: false
# if true, set logging to development mode
# log.development: false
# configures log encoding. can either be 'console', 'json', or 'pretty'.
# log.encoding: ""
# the minimum log level to log
log.level: FATAL
# can be stdout, stderr, or a filename
log.output: winfile:///D:\Storj-DB\\storagenode.log
# if true, log stack traces
# log.stack: false
# address(es) to send telemetry to (comma-separated)
# metrics.addr: collectora.storj.io:9000
# application name for telemetry identification
# metrics.app: storagenode.exe
# application suffix
# metrics.app-suffix: -release
# instance id prefix
# metrics.instance-prefix: ""
# how frequently to send up telemetry
# metrics.interval: 1m0s
# maximum duration to wait before requesting data
# nodestats.max-sleep: 5m0s
# how often to sync reputation
# nodestats.reputation-sync: 4h0m0s
# how often to sync storage
# nodestats.storage-sync: 12h0m0s
# operator email address
operator.email: Thorben@j
# operator wallet address
...
# operator wallet features
operator.wallet-features: ""
# move pieces to trash upon deletion. Warning: if set to false, you risk disqualification for failed audits if a satellite database is restored from backup.
# pieces.delete-to-trash: true
# file preallocated for uploading
# pieces.write-prealloc-size: 4.0 MiB
# whether or not preflight check for database is enabled.
# preflight.database-check: true
# whether or not preflight check for local system clock is enabled on the satellite side. When disabling this feature, your storagenode may not setup correctly.
# preflight.local-time-check: true
# how many concurrent retain requests can be processed at the same time.
retain.concurrency: 5
# allows for small differences in the satellite and storagenode clocks
# retain.max-time-skew: 72h0m0s
# allows configuration to enable, disable, or test retain requests from the satellite. Options: (disabled/enabled/debug)
# retain.status: enabled
# public address to listen on
server.address: :28967
# if true, client leaves may contain the most recent certificate revocation for the current certificate
# server.extensions.revocation: true
# if true, client leaves must contain a valid "signed certificate extension" (NB: verified against certs in the peer ca whitelist; i.e. if true, a whitelist must be provided)
# server.extensions.whitelist-signed-leaf: false
# path to the CA cert whitelist (peer identities must be signed by one these to be verified). this will override the default peer whitelist
# server.peer-ca-whitelist-path: ""
# identity version(s) the server will be allowed to talk to
# server.peer-id-versions: latest
# private address to listen on
server.private-address: 127.0.0.1:7778
# url for revocation database (e.g. bolt://some.db OR redis://127.0.0.1:6378?db=2&password=abc123)
server.revocation-dburl: bolt://D:\Storj-DB/revocations.db
# if true, uses peer ca whitelist checking
# server.use-peer-ca-whitelist: true
# total allocated bandwidth in bytes (deprecated)
storage.allocated-bandwidth: 0 B
# total allocated disk space in bytes
storage.allocated-disk-space: 2.1 TB
# how frequently Kademlia bucket should be refreshed with node stats
# storage.k-bucket-refresh-interval: 1h0m0s
# path to store data in
storage.path: E:\jStorage\
# a comma-separated list of approved satellite node urls (unused)
# storage.whitelisted-satellites: ""
# how often the space used cache is synced to persistent storage
# storage2.cache-sync-interval: 1h0m0s
# directory to store databases. if empty, uses data path
storage2.database-dir: D:\Storj-DB\
# size of the piece delete queue
# storage2.delete-queue-size: 10000
# how many piece delete workers
# storage2.delete-workers: 1
# how soon before expiration date should things be considered expired
# storage2.expiration-grace-period: 48h0m0s
# how many concurrent requests are allowed, before uploads are rejected. 0 represents unlimited.
# storage2.max-concurrent-requests: 0
# amount of memory allowed for used serials store - once surpassed, serials will be dropped at random
# storage2.max-used-serials-size: 1.00 MB
# how frequently Kademlia bucket should be refreshed with node stats
# storage2.monitor.interval: 1h0m0s
# how much bandwidth a node at minimum has to advertise (deprecated)
# storage2.monitor.minimum-bandwidth: 0 B
# how much disk space a node at minimum has to advertise
# storage2.monitor.minimum-disk-space: 500.00 GB
# how frequently to verify the location and readability of the storage directory
# storage2.monitor.verify-dir-readable-interval: 1m0s
# how frequently to verify writability of storage directory
#storage2.monitor.verify-dir-writable-interval: 5m0s
# how long after OrderLimit creation date are OrderLimits no longer accepted
# storage2.order-limit-grace-period: 1h0m0s
# length of time to archive orders before deletion
# storage2.orders.archive-ttl: 168h0m0s
# duration between archive cleanups
# storage2.orders.cleanup-interval: 5m0s
# maximum duration to wait before trying to send orders
# storage2.orders.max-sleep: 30s
# path to store order limit files in
# storage2.orders.path: C:\Program Files\Storj\Storage Node/orders
# timeout for dialing satellite during sending orders
# storage2.orders.sender-dial-timeout: 1m0s
# duration between sending
# storage2.orders.sender-interval: 1h0m0s
# timeout for sending
# storage2.orders.sender-timeout: 1h0m0s
# allows for small differences in the satellite and storagenode clocks
# storage2.retain-time-buffer: 48h0m0s
# how long to spend waiting for a stream operation before canceling
# storage2.stream-operation-timeout: 30m0s
# file path where trust lists should be cached
# storage2.trust.cache-path: C:\Program Files\Storj\Storage Node/trust-cache.json
# list of trust exclusions
# storage2.trust.exclusions: ""
# how often the trust pool should be refreshed
# storage2.trust.refresh-interval: 6h0m0s
# list of trust sources
# storage2.trust.sources: https://tardigrade.io/trusted-satellites
# address for jaeger agent
# tracing.agent-addr: agent.tracing.datasci.storj.io:5775
# application name for tracing identification
# tracing.app: storagenode.exe
# application suffix
# tracing.app-suffix: -release
# buffer size for collector batch packet size
# tracing.buffer-size: 0
# whether tracing collector is enabled
# tracing.enabled: false
# how frequently to flush traces to tracing agent
# tracing.interval: 0s
# buffer size for collector queue size
# tracing.queue-size: 0
# how frequent to sample traces
# tracing.sample: 0
# Interval to check the version
# version.check-interval: 15m0s
# Request timeout for version checks
# version.request-timeout: 1m0s
# server address to check its version against
# version.server-address: https://version.storj.io
storage2.monitor.verify-dir-writable-timeout: 4m00s
but
Since you have a readability timeout error (not writeability), you need to add:
storage2.monitor.verify-dir-readable-interval: 1m30s
storage2.monitor.verify-dir-readable-timeout: 1m30s
you need to save the config and restart the node either from the Services applet or from the elevated PowerShell
Restart-Service storagenode
is it ok since then?
im on 1.78.3 thinking of reenabling ingress,
somebody has a node not full and the timeout error gone?
maybe i have the time to monitor it close in a week or so…
yeah for me it’s fine now, no error since update
I hope it’s not because of the bug Storagenode 1.77.2 wont stop, when the service just refuses to stop.
Hi @daki82, I’ve been here for almost a month and everything works correctly.
To avoid the timeout and stop the service, I left the following settings:
storage2.monitor.verify-dir-readable-timeout: 4m30s
storage2.monitor.verify-dir-writable-timeout: 8m0s
If the intervals are a bit exaggerated, but since I have set them like this, I have not had any problem in the node.
Attached below how is the node and its scores.

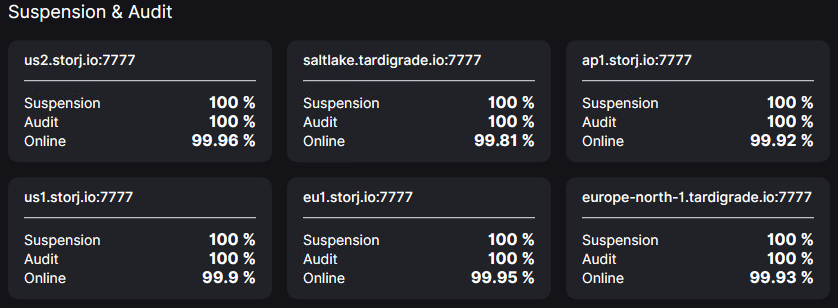
All the best
1 Like
seemd ok so far, no more problems. drive defragmented.
did not change the timeouts, ingres 30GB today, 99,98% uptime now.
but i let the service to be restarted after 2 min (will be ok for me) and the updates are done automaticaly are compatible (one update was done while).
This was a hellride for me, but i managed to save my only node.
![]()
![]()
3 Likes
had to do this too after 180h uptime
1 Like
You also need to update
storage2.monitor.verify-dir-readable-interval: 4m30s
1 Like
Maybe the SNO should decide what’s better.
A setting similar to --storage2.monitor.verify-dir-warn-only if the storage directory verification check fails, log a warning instead of killing the node that gives an option to log a warning instead of killing the node would be good idea.
1 Like
Alright. I had this issue on 1 windows node. Now I have the windows node with the same issue. Node running on synology has no issues.
So I suspect this issue is somehow related to windows client. As I really suspicious on both machines to have some hardware issue to cause this error.
1 Like
you have more information ? what did you do to fix it first time? what have you tried from this topic already? hardware/how full is the node? version?
1 Like
Hi, I am experiencing the same issue on a node. It crashes after a couple of days with the following error:
2023-09-23T10:29:01+02:00 ERROR services unexpected shutdown of a runner {“process”: “storagenode”, “name”: “piecestore:monitor”, “error”: “piecestore monitor: timed out after 1m0s while verifying writability of storage directory”, “errorVerbose”: “piecestore monitor: timed out after 1m0s while verifying writability of storage directory\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func2.1:176\n\tstorj.io/common/sync2.(*Cycle).Run:160\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func2:165\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75”}
I have noticed that there is a large amount of data in the trash on this node. For months (yes, months) there has been almost exactly 2.69TB in trash. This was after the data deletion from the 2 satellites recently. So it looks to me that the filerunner gets stuck on some files somehow and can’t delete the data from trash? The data on this node have been once transfered from one HDD to another, so could it be a permission issue on old data?
I’m running the node in a docker container on Unraid. I copied the database files to a SSD, but that didn’t solve the issue. Other than this crash, the node runs fine and sends and receives data, as well as deletion of other data. It is the 2.69TB of trash thats not deleted. The node also doesn’t fail audits (all 100%)
Logs
2023-09-23T10:28:50+02:00 INFO piecestore download started {“process”: “storagenode”, “Piece ID”: “7YUQ7MZECWV6OPZCOCF2WIH4625OBDEFI3T6KI5T3ABG6UUC2G3A”, “Satellite ID”: “12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs”, “Action”: “GET_AUDIT”, “Offset”: 1258496, “Size”: 256, “Remote Address”: “34.142.104.80:51850”}
2023-09-23T10:29:01+02:00 ERROR services unexpected shutdown of a runner {“process”: “storagenode”, “name”: “piecestore:monitor”, “error”: “piecestore monitor: timed out after 1m0s while verifying writability of storage directory”, “errorVerbose”: “piecestore monitor: timed out after 1m0s while verifying writability of storage directory\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func2.1:176\n\tstorj.io/common/sync2.(*Cycle).Run:160\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func2:165\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75”}
2023-09-23T10:29:01+02:00 INFO lazyfilewalker.used-space-filewalker subprocess exited with status {“process”: “storagenode”, “satelliteID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “status”: -1, “error”: “signal: killed”}
2023-09-23T10:29:01+02:00 ERROR pieces failed to lazywalk space used by satellite {“process”: “storagenode”, “error”: “lazyfilewalker: signal: killed”, “errorVerbose”: “lazyfilewalker: signal: killed\n\tstorj.io/storj/storagenode/pieces/lazyfilewalker.(*process).run:83\n\tstorj.io/storj/storagenode/pieces/lazyfilewalker.(*Supervisor).WalkAndComputeSpaceUsedBySatellite:105\n\tstorj.io/storj/storagenode/pieces.(*Store).SpaceUsedTotalAndBySatellite:707\n\tstorj.io/storj/storagenode/pieces.(*CacheService).Run:57\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2.1:87\n\truntime/pprof.Do:44\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2:86\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75”, “Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”}
2023-09-23T10:29:01+02:00 INFO lazyfilewalker.used-space-filewalker starting subprocess {“process”: “storagenode”, “satelliteID”: “12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs”}
2023-09-23T10:29:01+02:00 ERROR lazyfilewalker.used-space-filewalker failed to start subprocess {“process”: “storagenode”, “satelliteID”: “12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs”, “error”: “context canceled”}
2023-09-23T10:29:01+02:00 ERROR pieces failed to lazywalk space used by satellite {“process”: “storagenode”, “error”: “lazyfilewalker: context canceled”, “errorVerbose”: “lazyfilewalker: context canceled\n\tstorj.io/storj/storagenode/pieces/lazyfilewalker.(*process).run:71\n\tstorj.io/storj/storagenode/pieces/lazyfilewalker.(*Supervisor).WalkAndComputeSpaceUsedBySatellite:105\n\tstorj.io/storj/storagenode/pieces.(*Store).SpaceUsedTotalAndBySatellite:707\n\tstorj.io/storj/storagenode/pieces.(*CacheService).Run:57\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2.1:87\n\truntime/pprof.Do:44\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2:86\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75”, “Satellite ID”: “12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs”}
2023-09-23T10:29:01+02:00 ERROR piecestore:cache error getting current used space: {“process”: “storagenode”, “error”: “filewalker: context canceled; filewalker: context canceled”, “errorVerbose”: “group:\n— filewalker: context canceled\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkSatellitePieces:69\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatellite:74\n\tstorj.io/storj/storagenode/pieces.(*Store).SpaceUsedTotalAndBySatellite:716\n\tstorj.io/storj/storagenode/pieces.(*CacheService).Run:57\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2.1:87\n\truntime/pprof.Do:44\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2:86\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75\n— filewalker: context canceled\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkSatellitePieces:69\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatellite:74\n\tstorj.io/storj/storagenode/pieces.(*Store).SpaceUsedTotalAndBySatellite:716\n\tstorj.io/storj/storagenode/pieces.(*CacheService).Run:57\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2.1:87\n\truntime/pprof.Do:44\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2:86\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75”}
2023-09-23T10:29:16+02:00 WARN services service takes long to shutdown {“process”: “storagenode”, “name”: “trust”}
2023-09-23T10:29:16+02:00 WARN servers service takes long to shutdown {“process”: “storagenode”, “name”: “server”}
2023-09-23T10:29:16+02:00 INFO servers slow shutdown {“process”: “storagenode”, a very long message deleted due to maximum characters
2023-09-23T10:32:00+02:00 INFO piecestore downloaded {“process”: “storagenode”, “Piece ID”: “IHQQUDBD7GOX7EN4ZBUNZCHVLDW2ENNSY6ZLN2AQDFQZFLZ2XN3A”, “Satellite ID”: “12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs”, “Action”: “GET_AUDIT”, “Offset”: 622080, “Size”: 256, “Remote Address”: “34.142.104.80:46024”}
2023-09-23T10:32:00+02:00 INFO piecestore download canceled {“process”: “storagenode”, “Piece ID”: “CVPPSL5UHS3WCYQL7DE3XIVLDDFBZXEODOMUYV7EF3MQMIDJXL3A”, “Satellite ID”: “12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs”, “Action”: “GET”, “Offset”: 123904, “Size”: 0, “Remote Address”: “184.104.224.98:36974”}
2023-09-23T10:32:00+02:00 INFO piecestore download canceled {“process”: “storagenode”, “Piece ID”: “JLFMUXEN7LD5JWTTA6B4RKOKXGE5VZXSAR37MVUBL7YSN7JUCXXQ”, “Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “GET”, “Offset”: 1159424, “Size”: 0, “Remote Address”: “5.161.56.161:51074”}
2023-09-23T10:32:00+02:00 INFO piecestore download canceled {“process”: “storagenode”, “Piece ID”: “QNBVXQN2AFPWFEKCAQRACNOJE3CCIFBMQZJMG27FGK66GK4P3Z5Q”, “Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “GET_REPAIR”, “Offset”: 0, “Size”: 0, “Remote Address”: “199.102.71.14:46412”}
2023-09-23T10:32:00+02:00 INFO piecestore download canceled {“process”: “storagenode”, “Piece ID”: “K3DQSZC2D4PQVTUZTVZRVRBNZTQHFOT5XFHZSDMME4OCUMSXGKVQ”, “Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “GET”, “Offset”: 289792, “Size”: 0, “Remote Address”: “5.161.192.160:37876”}
2023-09-23T10:32:00+02:00 INFO piecestore download canceled {“process”: “storagenode”, “Piece ID”: “7YUQ7MZECWV6OPZCOCF2WIH4625OBDEFI3T6KI5T3ABG6UUC2G3A”, “Satellite ID”: “12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs”, “Action”: “GET_AUDIT”, “Offset”: 1258496, “Size”: 0, “Remote Address”: “34.142.104.80:51850”}
2023-09-23T10:32:00+02:00 INFO piecestore download canceled {“process”: “storagenode”, “Piece ID”: “JLFMUXEN7LD5JWTTA6B4RKOKXGE5VZXSAR37MVUBL7YSN7JUCXXQ”, “Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “GET”, “Offset”: 1449216, “Size”: 0, “Remote Address”: “5.161.213.246:49932”}
Error: piecestore monitor: timed out after 1m0s while verifying writability of storage directory
2023-09-23 10:32:05,849 INFO exited: storagenode (exit status 1; not expected)
2023-09-23 10:32:06,856 INFO spawned: ‘storagenode’ with pid 6347
2023-09-23 10:32:06,861 WARN received SIGQUIT indicating exit request
2023-09-23 10:32:06,865 INFO waiting for storagenode, processes-exit-eventlistener, storagenode-updater to die
2023-09-23T10:32:06+02:00 INFO Got a signal from the OS: “terminated” {“Process”: “storagenode-updater”}
2023-09-23 10:32:06,903 INFO stopped: storagenode-updater (exit status 0)
2023-09-23 10:32:06,907 INFO stopped: storagenode (terminated by SIGTERM)
2023-09-23 10:32:06,909 INFO stopped: processes-exit-eventlistener (terminated by SIGTERM)
The fixes are the same:
- stop and remove the container
- check and fix errors on the disk
- run the node
If it’s still stop because of timeout, you may increase it with 30s step. If you have a writeability timeout, you need to increase a writeable timeout
If you have a readability timeout, you need to increase a readable timeout and readable interval:
Sorry, forgot to add that I also already changed to config to increase the timeout. I’m not sure though if I increased the writable or readable interval. I will check that. I will also look into disk errors, but so far logging had no errors
SMART is also fine on that disk and it gives no other issues in my machine
Edit: saw that I also tried to increase the writable timeout, but didn’t type it correctly. I change that now to see if that works
Hello
After the last upgrade to 1.89.5, the service of my node keep stopping. I am running a Windows node. At the moment i am running a big chkdsk scan of the drive.
I have a new log file which is 1 day old. So if you tell me how to upload it here, probably someone of the GURUs can check it and help me out.
Thank you in advance!
for me it looks like you have some problems with hdd, it very slow. Try to check hdd with windows check tool, may be you have some ntfs broken.
thank you
i am doing just that
it shows, that it should complete in 24h, so i will share some updates tomorrow.