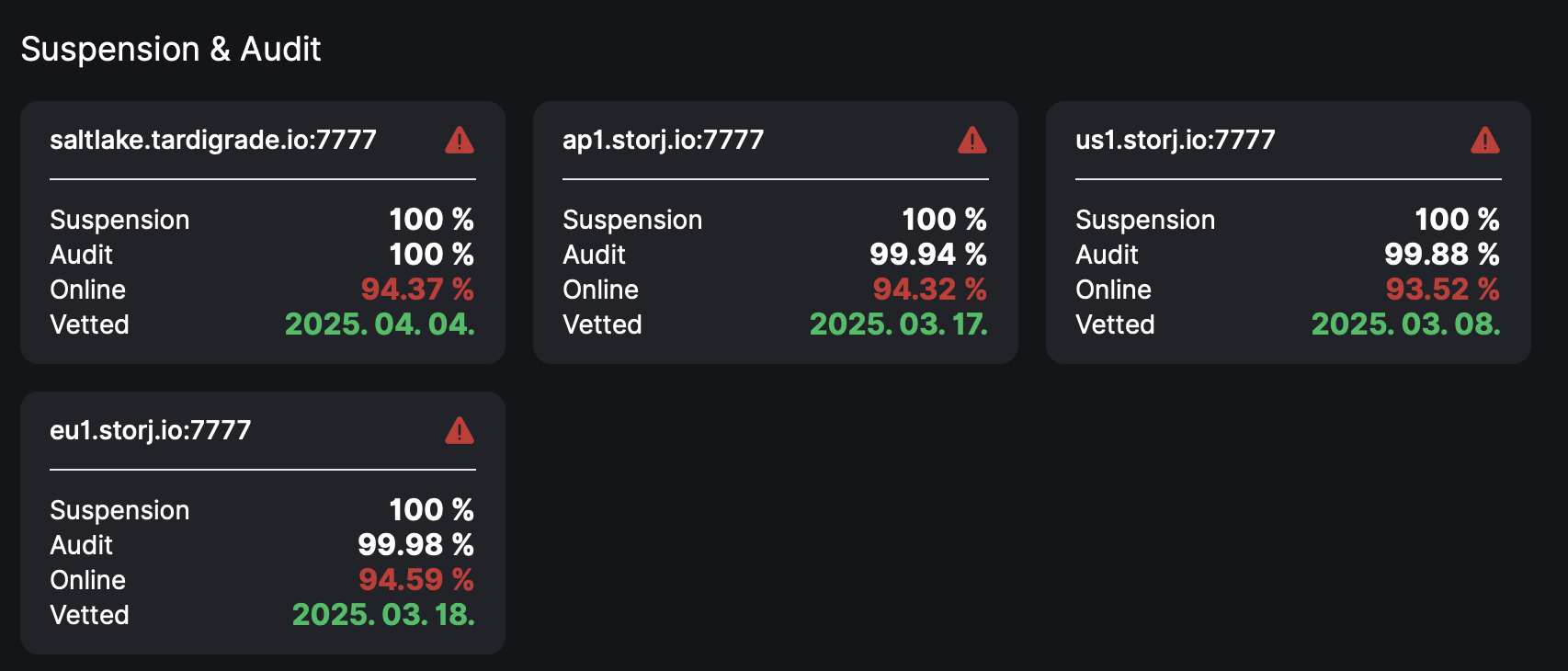
Hopefully you’re only using PrimoCache ONLY for READ acceleration, if you have ANY WRITE cache that would cause corruption for EVERYTHING in that portion of the cache. Thus your current audit stats. Even a 64GB write cache would be: 64/4% = 1,600 GB or 1.56 TBs, and you’d be disqualified in less than an hour after re-boot, as the entire amount of that cache would be gone.
Keep with occasionally defragmenting the MFT.
You have more than enough ram to cache the entirety of the MFT: 3TB @avg 192k blob size would be ~16,777,216 files, thus using 1k records that’s 16GB (5.33 GB/TB).
Go figure out and ensure that your Windows server is using large cache mode.
I also use Windows Servers, among other OSes on a cluster of vSan nodes.
I set my MTF on a pre-constructed SSD image within the NTFS drive itself, while all large record data remains on the HDD. This technique forces all small records to be accessed with full acceleration, and more than DOUBLES the HDD iops. of the NTFS (for any usage pattern whatsoever, as half of every record access NTFS does involves touching the MFT; which resolves near instantly; therefore the HDD head stays where it is and continues to read data contiguously without having the reference the MFT on every next block). Using 4k cluster size, having a max of 16TBs per node/HDD, anything higher for Storj node use would be counter productive, IMO. This manually perforated MFT of 1 meg contiguous segments reaches ~160GB, 86GB (good for 5.375 GB of MFT entries x 16 [TB] = 86 million files) of which denote the actual MFT the remainder supports all files <16k records to reside either within the MFT records themselves (<4k), or to be set within these 1 meg segments in between the contiguous portions of the MFT; thus forcing all > 1meg data segments onto the HDD itself. It’s not actually much different than ZFS as many here use here, just less rigid.
If I ever ever ever need to defragment, it would only be to defrag files less than 16k-32k. As it only would pull and sort data onto the Nvme; from the Nvme area or the HDD area one way - it’s quick and efficient. 4k cluster also chosen to match native 4kn & Nvme, additionally allows the use of compression, which allows a segmented advantage to denote specific directories for further ease of block manipulation when it comes to any fragmentation. In the case of Storj, think trash directory and having advanced control to pre-defrag future trash removal as advanced cleaning/maintenance of main data. Obviously useful for other things too, as you can defrag only files flagged compression only, much like record size.
BTW, it kicks ZFS ass. I also have ZFS servers with all the bells and whistles employed, and it’s certainly useful for everything as well.
Not here to argue, not here to make a guide/tutorial or anything. Just giving a HINT of what’s possible if you actually think outside the box.
Other ideas:
You might consider employing CASS, Intel’s old failed/dead open source cache software, it’s free but very stable. Its a far better choice than trying to get any productivity out of PrimoCache, and much much much safer.
You could also try V-locity, it’s excellent for real time fragmentation prevention and background defragmentation. It’s ounce of prevention is worth a pound of cure. It’s also useful in cluster file systems, as it also configures as a client to and as part of a network server head end, which coordinates various participating nodes.
You could also use REFS, it will provide far less fragmentation for this use case.
After about 4TBs NTFS will have scattered 200 meg segments randomly everywhere, and yes often people must defrag, as the aformentioned record access hdd head movement becomes unbearably slow to access stuff, because you didn’t plan ahead.
Good luck!
25 cents,
Julio