Sorry for the strange title, didn’t know how to best describe it.
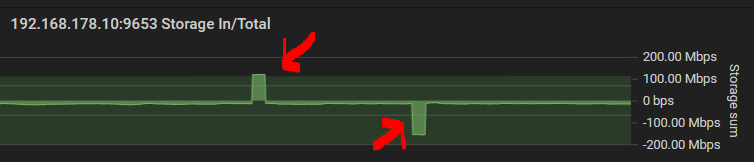
I’m occasionally seeing on my nodes that after a long time of high disk activity (probably checking the pieces and moving some to trash) some space gets freed for the node but a short while later, that amount (or mabye slightly different) gets added to the used space again:
Could this be expected behaviour with a “too eager bloom filter” and then the data has to be moved back from trash or could this be a different problem?
I do, of course, not have any proof as to what is going on. My assumption about files being moved to/from trash might be completely wrong.
i think the guess with it being moved from one folder to another might be spot on, and the odd result is when the monitoring software detects the “removal of the files” and then a delay before it gets around to checking all the folders for new entries…
no matter still looks like an artifact of how the not monitoring software keeps track of the data
its nearly impossible to live update big datasets… its actually stuff like that atime in zfs is for… but duno if that function is applicable or worth it for the performance costs…
how do i get that up and running ?
zabbix? or what is it