The controller does support RAID 6 but the architecutre and storage protocols of ML110 Gen9 Server will not allow RAID 6 configuration irrespective of the controller being used.
Not sure what they mean there, it seems illogical, but then I have pretty much no experience with hardware RAID. So I’ll leave that discussion to others from here on out.
Yes, it seems illogical. I’ve been asking what group of telegrams we have around servers, and they don’t see much logic in it either.
I wanted to ask you if the bandwidth that storj uses can be configured, or right now it is automatically configured so that it can use all the bandwidth that the network has.
It can’t be configured. If you want some control I recommend using QoS to prioritize traffic rather than limiting bandwidth, but there are third party solutions for either approach.
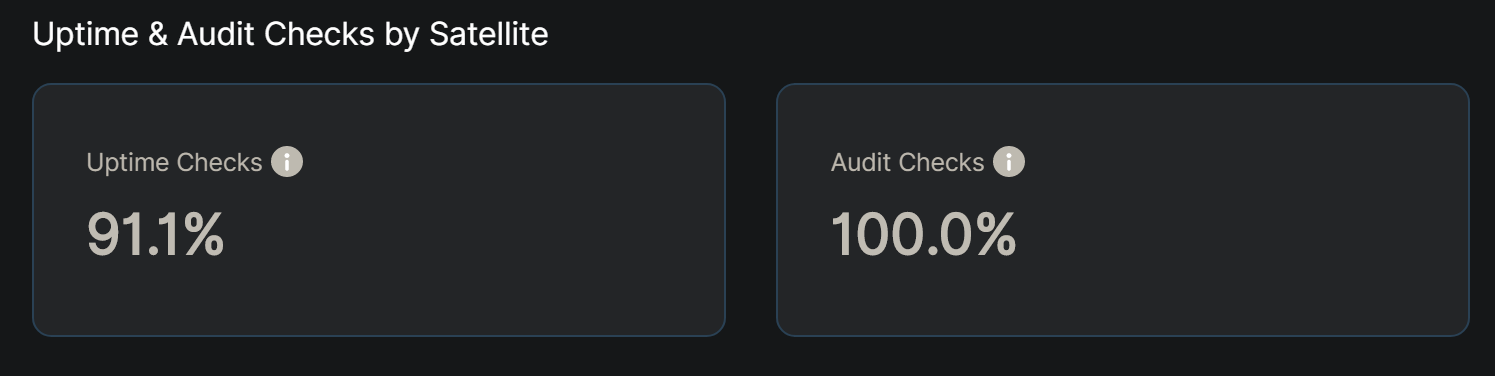
This data, after installing the new knot and having 70 hours, indicates that it is good, bad or I am going to be a millionaire? (Please make it the millionaire option)
You’re not going to be a millionaire. At least, not because of Storj, I won’t pretend to know your personal life.
Uptime checks are a bit low, they suggest you had some down time. This is not yet an issue, just keep your node online from now on and that will recover.
Has it been online ever since you first started it? As soon as the node contacts the satellite for the first time, it will get uptime checks. If you were still messing with the setup, you may have missed some uptime checks while doing that. Keep an eye on that number just to be sure. It should only go up from here. If not, something may be wrong.
Yes yes, it has been running since I created the node, and the configuration is completely default and I have never touched anything. I created the node and it’s been there until now. But I’m telling you, that number’s going up every day bit by bit.
If I send an email to get a new token, how long can this token go unused?
As for storage, when I installed storj I told him to save 15 TB. You know I have a RAID configuration, if I decide to expand or decrease this space, how should I proceed? I don’t have to add any disks, just tell storj to expand or shrink. Would this affect my node which is doing the month of testing right now? Thank you.
Note that you can shrink the node’s capacity below what is stored. However, this will not immediately migrate data away from your node. Instead, your node will simply stop accepting new uploads until enough data is deleted by customers that the storage usage falls below the capacity you specified.
again with the multinode situation you were discussing earlier…
from what I´ve read in other threads, multi node scenario on the same IP it´s very bad since the nodes will be competing for data and vetting, and doing so they will last much longer to fill. So I´ve assumed the only profitable way to do this is get one node, wait for it to be filled (months?) and then escalate +1 nodes. Loop this growth mechanism until millionaire scenario
but seems to me that you are talking about multinode-all-of-the-sudden scenario.
The only point here that really matters is vetting. If you have 10x1TB nodes or 1x10TB node doesn’t much matter. The same amount of traffic will be split between the 10 nodes as would be given to a single node, so the nodes will fill just as fast. If some nodes are full, they will not participate in the “splitting” – if you have 9 full nodes then the 10th node will be getting the full traffic as though you were running a single node. Note this only applies to ingress traffic – egress traffic is not limited and only depends on how often the customer wants to retrieve their data.
Points in favor of using RAID/ZFS/btrfs/etc. with redundancy:
Simpler management; no need to create new identities when a disk fails, and monitoring is easier since you don’t have to keep your eye on so many nodes.
More consistent revenue; since you won’t have the occasional node failure, your income will be more predictable, though over the long term it will be lower since some storage capacity is lost to provide redundancy.
Points in favor of running one node per HDD:
Higher revenue in the long term since capacity is not used to provide redundancy, though income will vary more since the occasional disk failure will reduce revenue for some months.
You can use disks of different sizes without complex multi-RAID setups.
Human error causing disqualification is not a catastrophe – you lost one node, but it’s one of many. If human error causes disqualification with a big RAID node then you lose everything and have to start over from zero.
if i got it right, since the egress traffic is the main factor in revenue, it will be more profitable larger nodes. Since it has more data, it will have more probabilities of data retrieval from the users . Isn´t so?
In the earnings estimator, there is not much difference if you use 2TB or 10TB. I´m a little confused about what strategy to use: a cheaper and smaller disk, or larger ones? (which will be more difficult to monetize)
but… I´m getting the sense that this earning estimator is very deceiving??
i´m in “not putting all the eggs on the same basket” filosofy
Yes, however there is no difference in this regard between one 10TB node and 10 1TB nodes. The egress revenue potential in both scenarios is identical.
In the case of reducing or increasing the size of the node, first I stop the service, then in the config.yaml file I modify the number of terabytes I initially put to the one I want, I close the file and then I start the service again. That would be the procedure?
The modification is about a RAID, I don’t intend to add any disk or remove any disk, it’s just to modify the assigned space. Thanks again.