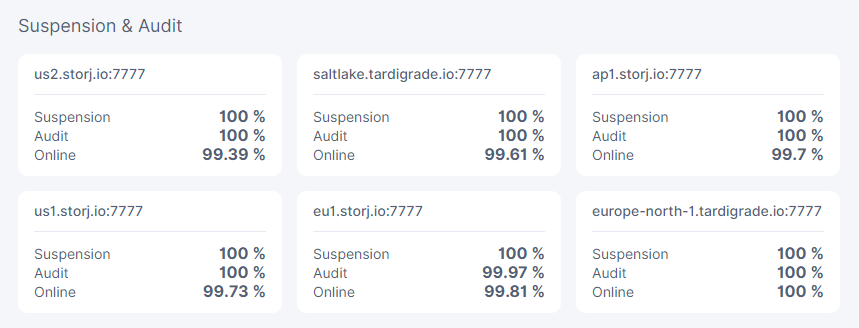
Adding a data point…
- My node updated to v1.42.4
- Uptime 43 hours
- All audits and suspension scores 100% on all satellites
- Online score 100% on most, 99.98% on two US1 and Saltlake
Adding a data point…
Had the same problem with one of my nodes last night. Meanwhile back to 100. Today another node is affected, but is already rising again.
running a scrub, but not zfs errors reported… so most likely related to this signature thing.
will dig into the logs and add what i find about it in a bit.
tho this is a worrying trend when one considers it can take years before audit scores should recover… i mean i got one node where i accidentally deletes a few files with rsync --delete
and it’s been bitching for 6 months now…
now that i think about it tho this error isn’t damage to the files just errors, so i would suppose the audits go back to being all successful when its fixed…
but i digress… LOGS
grep ERROR 2021-11-1*-storagenode* | grep GET_AUDIT | wc -l
0
can’t seem to find the actual cause… even checked like 4 days back… but pretty sure it wasn’t there yesterday.
I checked them manually, and used grep can’t find any failed audits.
even tried my node i know has failing audits and my grep attempts worked fine on that.
ofc now i will have to question my logging script… even tho i don’t think there is any issues with that, has been working fine for a long time…
verified my log, it seems to be functioning correctly atleast over the 11 hours i scanned through for time inconsistencies and only thing i found was a 2minutes and 30 sec pause at one point which must have been either just a case of no traffic or a minute internet outage.
so yeah i duno, how my audit score for eu1 dropped… i’m open for suggestions for how to maybe find the error…
i’m just going to assume it’s related to the signature thing and leave it at that… hope it will be fixed in the near future.
So… the first word in the title of this thread is GET_REPAIR… and you decided to look for GET_AUDIT?
grep ERROR 2021-11-1*-storagenode* | grep GET_REPAIR
2021-11-12-storagenode.log:2021-11-12T09:09:32.908Z ERROR piecestore download failed {"Piece ID": "XIHTZG5HGJCCG4AAZNIRZTDAOXOTDYXIIFE2WGJJECNNGWMS4T2Q", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Action": "GET_REPAIR", "error": "signing: piece key: invalid signature", "errorVerbose": "signing: piece key: invalid signature\n\tstorj.io/common/storj.PiecePublicKey.Verify:67\n\tstorj.io/common/signing.VerifyUplinkOrderSignature:60\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).VerifyOrder:102\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).Download.func6:663\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).Download:674\n\tstorj.io/common/pb.DRPCPiecestoreDescription.Method.func2:228\n\tstorj.io/drpc/drpcmux.(*Mux).HandleRPC:33\n\tstorj.io/common/rpc/rpctracing.(*Handler).HandleRPC:58\n\tstorj.io/drpc/drpcserver.(*Server).handleRPC:104\n\tstorj.io/drpc/drpcserver.(*Server).ServeOne:60\n\tstorj.io/drpc/drpcserver.(*Server).Serve.func2:97\n\tstorj.io/drpc/drpcctx.(*Tracker).track:52"}
only get that hit which is from the 12th, which is before the audit failure.
which i’m confident must have happened during late 13th or 14th
because i’ve been checking the nodes daily to try to gauge if the issue was getting worse.
and i cannot find why it dropped in audit score on eu1.
The audit can be affected by GET_AUDIT and GET_REPAIR in three ways:
The first one is visible in the logs as “file not found”. The second is visible too - you should measure time between “download started” and “downloaded” (see Got Disqualified from saltlake - #97 by Alexey). The third one cannot be visible in the logs (it will be downloaded as usual), but sometimes visible, see [storagenode] pieces error: PieceHeader framing field claims impossible size of XXX bytes · Issue #4194 · storj/storj · GitHub
It is curious that, for my node, both scores went down at the same time and for the same satellite, though audit score went down then back up once, while unknown audit score went down and back up a few times.
While it can be a coincidence, I do not think it is very likely.
They are independent scores. And they can fall both, but should be for different error events. One of them is known, the second one is unknown.
Can you (or someone else) check it from the satellite side? It is very strange that both went down at the same time. My node ID is 12AuK25mZf7VEM67gtNea7ZU2QVqvcZF4cQVN1JoCaBn3mfoRRp.
This usually takes a lot of time. Notified the team
It’s better to check your logs for GET_AUDIT or GET_REPAIR errors (and time intervals between successful downloads).
If you do not have logs at least for 12 hours prior the event - it would not help.
cat docker.00065.log | grep 12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs | grep AUDIT | grep 'download started' | wc -l
1032
cat docker.00065.log | grep 12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs | grep AUDIT | grep 'downloaded' | wc -l
1032
cat docker.00065.log | grep 12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs | grep GET_REPAIR | grep 'download started' | wc -l
5063
cat docker.00065.log | grep 12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs | grep GET_REPAIR | grep 'downloaded' | wc -l
5060
cat docker.00065.log | grep 12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs | grep GET_REPAIR | grep 'download failed' | wc -l
4
The GET_REPAIR download failures are in my first post:
2021-11-12T08:23:11.814Z ERROR piecestore download failed {"Piece ID": "3AUGAI7MMFTKWGQOWMBO5TMPGC6ZYPHR7F466JXJOITAZ5CBI5JA", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Action": "GET_REPAIR", "error": "signing: piece key: invalid signature", "errorVerbose": "signing: piece key: invalid signature\n\tstorj.io/common/storj.PiecePublicKey.Verify:67\n\tstorj.io/common/signing.VerifyUplinkOrderSignature:60\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).VerifyOrder:102\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).Download.func6:663\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).Download:674\n\tstorj.io/common/pb.DRPCPiecestoreDescription.Method.func2:228\n\tstorj.io/drpc/drpcmux.(*Mux).HandleRPC:33\n\tstorj.io/common/rpc/rpctracing.(*Handler).HandleRPC:58\n\tstorj.io/drpc/drpcserver.(*Server).handleRPC:104\n\tstorj.io/drpc/drpcserver.(*Server).ServeOne:60\n\tstorj.io/drpc/drpcserver.(*Server).Serve.func2:97\n\tstorj.io/drpc/drpcctx.(*Tracker).track:52"}
2021-11-12T08:23:11.897Z ERROR piecestore download failed {"Piece ID": "ZSYW6HKR2WZ7GZI7I3MXU42HH45LNJU6L7COGCSBH2WOJGLI5XHQ", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Action": "GET_REPAIR", "error": "untrusted: invalid order limit signature: signature verification: signature is not valid", "errorVerbose": "untrusted: invalid order limit signature: signature verification: signature is not valid\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).VerifyOrderLimitSignature:145\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).verifyOrderLimit:62\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).Download:490\n\tstorj.io/common/pb.DRPCPiecestoreDescription.Method.func2:228\n\tstorj.io/drpc/drpcmux.(*Mux).HandleRPC:33\n\tstorj.io/common/rpc/rpctracing.(*Handler).HandleRPC:58\n\tstorj.io/drpc/drpcserver.(*Server).handleRPC:104\n\tstorj.io/drpc/drpcserver.(*Server).ServeOne:60\n\tstorj.io/drpc/drpcserver.(*Server).Serve.func2:97\n\tstorj.io/drpc/drpcctx.(*Tracker).track:52"}
2021-11-12T08:50:00.313Z ERROR piecestore download failed {"Piece ID": "4SGNT6DEUVKQTDAQ5D7KRM5TZS4HAHHXV3OSAM3C4WHZTRY25VIQ", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Action": "GET_REPAIR", "error": "untrusted: invalid order limit signature: signature verification: signature is not valid", "errorVerbose": "untrusted: invalid order limit signature: signature verification: signature is not valid\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).VerifyOrderLimitSignature:145\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).verifyOrderLimit:62\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).Download:490\n\tstorj.io/common/pb.DRPCPiecestoreDescription.Method.func2:228\n\tstorj.io/drpc/drpcmux.(*Mux).HandleRPC:33\n\tstorj.io/common/rpc/rpctracing.(*Handler).HandleRPC:58\n\tstorj.io/drpc/drpcserver.(*Server).handleRPC:104\n\tstorj.io/drpc/drpcserver.(*Server).ServeOne:60\n\tstorj.io/drpc/drpcserver.(*Server).Serve.func2:97\n\tstorj.io/drpc/drpcctx.(*Tracker).track:52"}
2021-11-12T09:06:15.098Z ERROR piecestore download failed {"Piece ID": "RCXFOOKE2QDD5TF4HDOGZ2JI4HIEYNHP7ETWBSKIHNHDFROVMUWA", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Action": "GET_REPAIR", "error": "untrusted: invalid order limit signature: signature verification: signature is not valid", "errorVerbose": "untrusted: invalid order limit signature: signature verification: signature is not valid\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).VerifyOrderLimitSignature:145\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).verifyOrderLimit:62\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).Download:490\n\tstorj.io/common/pb.DRPCPiecestoreDescription.Method.func2:228\n\tstorj.io/drpc/drpcmux.(*Mux).HandleRPC:33\n\tstorj.io/common/rpc/rpctracing.(*Handler).HandleRPC:58\n\tstorj.io/drpc/drpcserver.(*Server).handleRPC:104\n\tstorj.io/drpc/drpcserver.(*Server).ServeOne:60\n\tstorj.io/drpc/drpcserver.(*Server).Serve.func2:97\n\tstorj.io/drpc/drpcctx.(*Tracker).track:52"}
I modified one of my monitoring scripts to check the times, I get that the longest GET_AUDIT time is 1.57 seconds and longest GET_REPAIR time is 4.44 seconds.
One of them affected your audit score, three others - suspension score.
For the timeouts check I would recommend to use this script: Got Disqualified from saltlake - #97 by Alexey
new node also dropping in audit score for eu1
the first one is back up to 100% on audit score atleast…
so still no real danger signs.
cat /bitpool/storjlogs/2021-11-15-storagenode.log | grep 1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE | grep -E "GET_AUDIT" | jq -R '. | split("\t") | (.[4] | fromjson) as $body | {SatelliteID: $body."Satellite ID", ($body."Piece ID"): {(.[0]): .[3]}}' | jq -s 'reduce .[] as $item ({}; . * $item)'
{
"SatelliteID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE",
"PULWACE3UUDCXPBJNGWYEV64VATEZZU7GNGRB7QA2ZGV4POEOOXA": {
"2021-11-15T00:00:53.712Z": "download started",
"2021-11-15T00:00:53.937Z": "downloaded"
},
"MT6GCPXJ6VNOYMZPUPWBDZHXOCLUI75BMP5EYPJZT2I2WYPHEUFA": {
"2021-11-15T00:33:05.325Z": "download started",
"2021-11-15T00:33:05.605Z": "downloaded"
},
"T3U3EPEDQ4FYCYFKNWJEDYML6ISVFT655TCWJZNEM65OY444KFIA": {
"2021-11-15T02:56:10.081Z": "download started",
"2021-11-15T02:56:10.272Z": "downloaded"
},
"DLEIYQTHAY3LSBSMQVPINASHX4MYJREKYIEI26NTUBMUK5FH2I4Q": {
"2021-11-15T03:09:30.984Z": "download started",
"2021-11-15T03:09:31.150Z": "downloaded"
},
"KBM5DNDP33AOKTWWULTCTPWDAPJNM5DLKU5IEJXBBBQHTVJPSV5Q": {
"2021-11-15T03:22:15.833Z": "download started",
"2021-11-15T03:22:16.047Z": "downloaded"
},
"QK7AC6U33APXHECEH553XOPEF5AJG3VI2XJWDC2EH7TBZPZ6DW7Q": {
"2021-11-15T04:03:31.885Z": "download started",
"2021-11-15T04:03:32.067Z": "downloaded"
},
"APYHRA4PIUYFLFHRA75YHGNC5FUVYRHDW6KA6FZ54TDLGVK3DQWA": {
"2021-11-15T04:22:37.088Z": "download started",
"2021-11-15T04:22:37.279Z": "downloaded"
},
"5ZP57KS2VEEIEX5U4KBKMPUEJZDJLSGPYYTVV7HN4YVQWMGISEXA": {
"2021-11-15T04:38:25.097Z": "download started",
"2021-11-15T04:38:25.293Z": "downloaded"
},
"C5UATBEH2UD6EIP7Y5C7ASZTF4H3M33EQGSXWJFYUCB64YRVTQTQ": {
"2021-11-15T04:50:48.513Z": "download started",
"2021-11-15T04:50:48.723Z": "downloaded"
},
"DOFH6K6AXAZJFMGWESPMV3RIHRX4ZFPNLKPJC65LHDEE3RJTTEWQ": {
"2021-11-15T06:18:54.255Z": "download started",
"2021-11-15T06:18:54.452Z": "downloaded"
},
"BKJ4YXVGCYQBU6CFF74CCGTQTKFBNANXFCAQA5YN2AV5CAGU4FKA": {
"2021-11-15T08:19:41.720Z": "download started",
"2021-11-15T08:19:41.976Z": "downloaded"
},
"23EAZTXXRXVD2DE7T3JERX3SJHQYA52K5L5D2P5MDQ6AS6H6PDUQ": {
"2021-11-15T10:21:57.418Z": "download started",
"2021-11-15T10:21:57.617Z": "downloaded"
},
"OSLCNMLYPPHC5BVC5FBTXOD7MOUV2GD4VTBBWZAZSAG4QBEIVY4A": {
"2021-11-15T10:30:56.733Z": "download started",
"2021-11-15T10:30:56.901Z": "downloaded"
},
"OVKNAKNGUQFQIXSHIYW5KJ3RUT7ZWJYTVJGIKROUQ7DZASYZQN2A": {
"2021-11-15T10:48:05.138Z": "download started",
"2021-11-15T10:48:05.349Z": "downloaded"
}
}
BOOM looks like something in the ranges of 200-300ms from start to completion.
while doing a scrub 
i really doubt these drop i audit scores on eu1 are random chance, seems like we have two data points me and pentium100 + i think it was jammerdan which also had an audit drop on eu1, duno if that was related or not tho…
i got 2 nodes independently with the drop and no other satellite seems affected, also my scrub is doing fine (zfs reports no data errors, only 40% done and will take a few days more)
and my system is operating as close to flawlessly as i can hope for.
on top of that everything has redundancy.
That’s what I was thinking before - one type of error affected the audit score, while the other - suspension score.
Your script looks good, though I then would either have to use another script to calculate the differences or try not to miss one with my eyes. Still, it will be a good way to double check my script.
You can improve this script and it could help others.
8 posts were split to a new topic: Script to count time for downloads (uploads) pieces
this seems to be getting worse or the impact over time is cumulative
i’m now up to like 5 nodes having audit issues on EU1 this is the worst affected today…
Of course. The more errors affecting the audit score, the faster this audit score declines.
What GET_AUDIT / GET_REPAIR errors do you have at this time?
Interesting, for my node, audit score went down (then back up) only once. For now, only suspension score is going up and down.
@SGC what errors do you get in the logs?
none it seems.
grep ERROR 2021-11-1*-sn0023* | grep GET_AUDIT
returns nothing.
grep ERROR 2021-11-1*-sn0023* | grep GET_REPAIR
also returns nothing.
so did a successrate… which also returns nothing.
./successrate.sh 2021-11-1*-sn0023*
========== AUDIT ==============
Critically failed: 0
Critical Fail Rate: 0.000%
Recoverable failed: 0
Recoverable Fail Rate: 0.000%
Successful: 1342
Success Rate: 100.000%
========== DOWNLOAD ===========
Failed: 661
Fail Rate: 1.621%
Canceled: 683
Cancel Rate: 1.675%
Successful: 39423
Success Rate: 96.703%
========== UPLOAD =============
Rejected: 0
Acceptance Rate: 100.000%
---------- accepted -----------
Failed: 58
Fail Rate: 0.030%
Canceled: 924
Cancel Rate: 0.480%
Successful: 191336
Success Rate: 99.489%
========== REPAIR DOWNLOAD ====
Failed: 0
Fail Rate: 0.000%
Canceled: 0
Cancel Rate: 0.000%
Successful: 2006
Success Rate: 100.000%
========== REPAIR UPLOAD ======
Failed: 4
Fail Rate: 0.018%
Canceled: 11
Cancel Rate: 0.050%
Successful: 21982
Success Rate: 99.932%
========== DELETE =============
Failed: 0
Fail Rate: 0.000%
Successful: 0
Success Rate: 0.000%
so yeah i duno, why it drops with no errors
grep ERROR 2021-11-16-sn00* | grep GET_REPAIR
2021-11-16-sn0001.log:2021-11-16T07:11:24.289Z ERROR piecestore download failed {"Piece ID": "7W22ELF3HTYZFILT53XQVWNDJTSS7XUQAJ4PDNGKNLWVW5B2EWWA", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Action": "GET_REPAIR", "error": "file does not exist", "errorVerbose": "file does not exist\n\tstorj.io/common/rpc/rpcstatus.Wrap:73\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).Download:534\n\tstorj.io/common/pb.DRPCPiecestoreDescription.Method.func2:228\n\tstorj.io/drpc/drpcmux.(*Mux).HandleRPC:33\n\tstorj.io/common/rpc/rpctracing.(*Handler).HandleRPC:58\n\tstorj.io/drpc/drpcserver.(*Server).handleRPC:104\n\tstorj.io/drpc/drpcserver.(*Server).ServeOne:60\n\tstorj.io/drpc/drpcserver.(*Server).Serve.func2:97\n\tstorj.io/drpc/drpcctx.(*Tracker).track:52"}
only error i can find is this one… also a node which dropped a bit in audit score for EU1
still no ZFS data errors recorded and my scrub is 78% done so the pool is looking fine.
never had more than one node drop i audit score before, and i know exactly why that happened because of a bad rsync -delete during a migration some 6 + months ago, so i excluded that one.
but i got 4 nodes showing drops in audit score for EU1 but doesn’t seem to show any errors for either of them.