Does it mean we have lost some customer data?
That would be a disaster. ![]()
![]()
It’s possible … as many SNO have multiple IPV4 so would get lot of pieces then if those went offline altogether then it can’t rebuild/repair ? Possibly
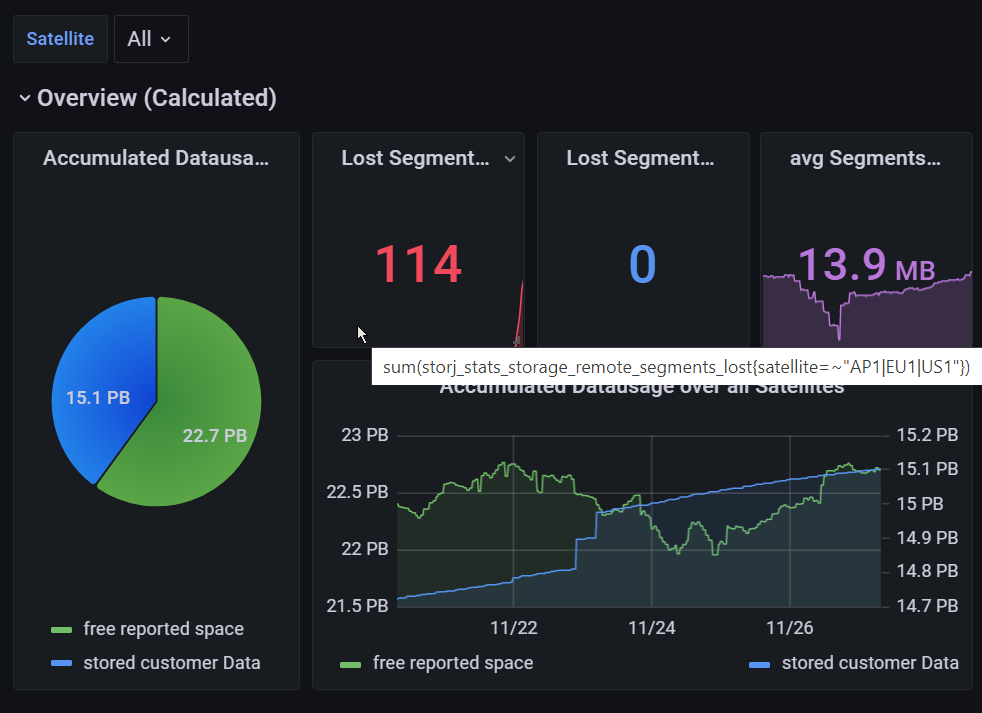
“Lost segments” as shown on that dashboard is misleading. It shows segments that the repair checker thought did not have enough healthy pieces to be restored at a particular moment in time, usually because the satellite itself had network issues and thought nodes were offline when in fact they were not .
And as you can see, it’s recovering.

Thank you for clarifying, @Alexey
I would imagine there are a lot of senior engineers and executives at Storj Labs looking at what’s going on with great interest.
Any chance you could give us some information once you guys get to the bottom of this? Not that it affects me as a Node Operator but I find it quite interesting.
We enabled GC recently, and it is started to send bloom filters to nodes, nodes deletes data at high rate and if they cannot keep up - they going offline until GC will finish its work.
It’s especially affect nodes which uses slow disks or stored data from several nodes on the same disk/array (this is one of the reason, why we asks Operators to do not do so).
Usually when GC is enabled all the time, the number of deletions shouldn’t affect even these weak nodes, but this time it was disabled longer than expected.
To amplify what Alexey is saying: this is a false alarm, and no data has ever been lost. There might be an official statement about this particular statistic on Monday, as far as I’m aware.
The better metric here should be the minimum segment health also shown on the dashboard. In the meantime please use that.
I believe that statement must be wrong. From the perspective of the repair checker, the network issue must be at least 4 hours long before the repair checker will make the assumption that too many storage nodes are unavailable. I would expect a lot of other problems if that ever happens. More likely the metric is coming from the repair worker itself. The outcome of a repair attempt will change if the nodes can’t be reached for a short moment or are overloaded in a way that the repair download will timeout. This time garbage collection might have impacted too many nodes at the same time. I believe that has caused the metric to panic.
To solve that we could add a third outcome. At the moment the repair worker is successful or fails. We should split these failed outcomes into 2 groups. A temporäry failure because of the download timeout vs a failure because of other reasons. The download timeout still means the node has the piece and was just not able to deliver it. Retry will most likely be successful here.
If I understand correctly, if the repair worker was unable to collect the necessary number of pieces for a stripe, a regular customer’s uplink client wouldn’t either, resulting in transient inability to fetch data?
Possible but not necessary. The repair worker might also have a short network blip while the customer is not impacted.
It could also be that one out of many files is taking longer to download. The customer might not notice that because of concurrent download requests that still max out the available bandwidth on his end. The repair worker has a strict timeout that will terminate the connection even if it the transfer is close to finishing.
Last but not least we don’t call this a lost segment even if the customer is temporäry unable to download it. A lost segment would count against durability but we are talking about availability here (worst case only if the customer is impacted). So either way it is a different story.
Why isn’t the GC on permanently?
The lost count in the repair list has finally returned to zero after having spent a few days at 1
Could “lost” be reworded to “repairs needing re-tries”
Yes I see it is back to zero.
Wording seems to be misleading.
Maybe also an additional counter can be implemented showing the all time lost segments. This counter should be 0 at all times then.
I’m still of the mind there isn’t much real customer data even in the network yet.
You have no way of knowing, so I guess you’d have to trust the people who do…
All data on the customer facing satellites EU1, US1 and AP1 are exclusively customer data. We only upload test data to the test satellites. So it is pretty easy to see how much customer data there is being up and downloaded.
The statistics are published at https://stats.storjshare.io/ and available in graphic display at https://storjstats.info/ (dashboard provided by a forum member). So yes, there is a way of knowing.
Ah, fair enough. I hadn’t looked at those pages and didn’t realise there was a discrimination between “real” and test data. ![]()