Hello guys.
I have little experience working on a backend so I hope you’ll welcome (or at least won’t send away ) my silly questions and thinking. And it’s probably worth mentioning that I have no prior experience working with S3 like storage.
I wanna do a project that implements uploading to and downloading from backend.
As a data storage I’m going to use Storj.
Downloading is somewhat clear to me, I believe you can download from storj directly from a web app.
But I don’t really understand how the uploading data from a web app will work.
You can’t just send something from a web browser to Storj network (can you?).
In order to upload something to Storj this something needs to be on my computer/server that communicates with Storj, so first thing is to upload from web browser to my computer/server.
But it doesn’t feel right, it sounds like an unnecessary intermediary and additional complexity to my backend.
Is there a workaround or this is how it works in most web apps that use Storj? Maybe there’re some tools that reduce (or replace) the need for intermediary storage, making life easier?
And what about performance? I don’t know shit about how it works but I believe I need a damn good server if I want to handle many downloads/uploads.
You could upload data to storj directly from the browser, but that would mean to expose secret information like connection data and encryption key. Since this data is delivered to any connecting users browser, it can be exploited.
So you need something where you can send your data to which accepts your file and forwards it to storj while keeping the storj credentials hidden.
Depending on the programming language and your skills you can proxy the file through your server without storing anything there. It’s not really unneccessary complexity. If you want to connect to a database you have the same problem.
As for performance it depends on how many users you have at the same time. The main issue is internet connection speed. There is also some processing necessary for the encryption process or you can use the public gateway which does the processing for you.
You could use some cloud functions like google cloud functions or aws lamda or vercel to run you server, doesn’t need to be a full fledged hardware server.
If you want full E2E encryption you need a place to store the private key. You could use something like wasm in a browser, but that would expand the maintenance area of the platform. (note: there are wasm sandbox limitations: networking, I/O, etc. - as the standard evolves I’m sure those limitations will change)
If you want uber-control over the behavior of your app - you want to have a business-layer in a lambda or backend service, which is where libuplink comes in. If you want simplicity and speed-to-market, just use the storj S3 endpoints - you get most of the benefits of web3 without the integration effort.
Sometimes I can’t express myself clearly due to language barriers, I apologize.
I’m saying that I made storj uploading/downloading to work but I’ve been stuck for over a week now on how to connect my web client to upload files directly to storj without storing them on the server.
How to transfer files in small chunks client → server → storj as a buffer to be precise.
I want to make things in a best way possible, so I thought to send files through a websocket connection, splitting them into chunks and waiting for chunk to be uploaded.
The main problem is how to send the chunks in a way that websocket would wait for a chunk to be uploaded to Storj before accepting a new one. I’m using a server with limited memory so sending all chunks at once and storing them in buffer on the server is not an option. I need to send a chunk, wait → upload chunk to Storj → call client for another chunk.
Do you still want to help? :))
Given that you’re only dealing with upload and download requests, you actually don’t need a web socket. You should be able to do everything you need with a chunked HTTP request/response (see Transfer-Encoding - HTTP | MDN). This will allow you to send/receive data in parts rather than getting the full request body all at once. For a fuller write-up on HTTP data streaming, see HTTP Streaming (or Chunked vs Store & Forward) · GitHub.
It can be difficult to provide guidance without seeing the code that you’re working with specifically, but I’ve taken some time to write up a sample server. It only supports receiving and passing on an upload without any intermediary buffers/storage. I’ve also tried to annotate the code based on steps in the uplink-nodejs library readme.
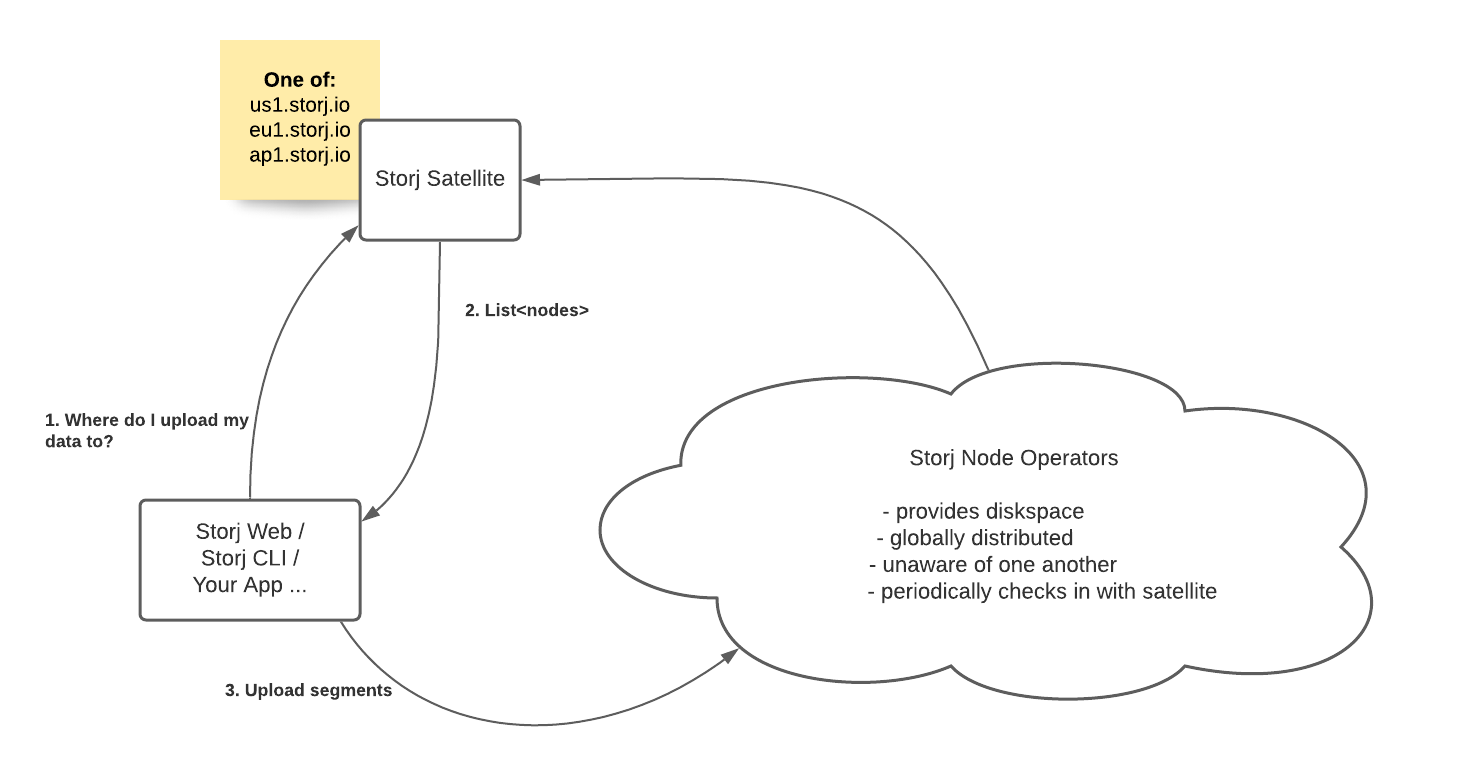
In terms of a general reference architecture, there are three key actors:
Storj Satellites - the “control plane” - instructs where data should be placed and handles administrative tasks. These are generally run by a provider like Storj.
Storj Nodes - the “data plane” - persists encrypted reed-solomon segments to disk. Globally distributed. Unaware of one another. These periodically check in with a single satellite.
Your application - the “client” - imports uplink library for language. Provides the business logic to your end-users. Can be coded in the browser or a server-side application.
To try and provide some additional context, I’ve assembled the diagram below to illustrate the basic exchange of information within the system. There’s obviously a whole lot more that goes on, but this conveys the general idea.
For the most part, exchanges between your application and satellites will be for metadata while requests for object contents will require reaching out to the Nodes.
I think you don’t have to split everything into chunks yourself, the network transport layer will do that for you. Here is an example I found from Stackoverflow.
On the server instead of writing everything to a file in the filesystem you proxy it through to storj.
import { PassThrough} from 'stream';
const proxy = new PassThrough();
// taken from the stackoverflow
const dataFromClient = deserialize(wsMessage, {promoteBuffers: true});
// dataFromClient.file should be a stream
dataFromClient.file.pipe(proxy);
Then you initialize the upload to storj. Here in the example the connection to storj is initialized and then a buffer is created to send data to storj. Instead of opening a readstream to a local file you use the proxy stream.
PS: I wrote until here yesterday and didn’t know how to continue with the storj part. Thanks to @mya it is now clear.
You can do the initialization like @mya said and update L32 so use proxy instead of request. Probably should work without proxy, but with dataFromClient.file directly.
I want to upload through a websocket because I want to learn how to use websockets.
But it seems websockets are complex as hell and I’m hitting one wall after another with no visible progress.
I’ll try uploading through http if I will be stuck for another week. Thank you for suggestions and help =)
Hey. Thanks for your reply.
I’m not sure network would split large file into chunks… I couldn’t find any information on it.
But example you provided is exactly what I was looking for.
I think I can achieve what I want with BSON library.
Will come back later with code example =)
If you use a plain html file input you can also sent large files. Why should it not be the same with something else. It’s just a stream of data. Packets are sent until the stream is finished.
Ok, I didn’t know that. I don’t use Websockets very often. Especially not to send files . I would always start with the simplest solution (HTTP file input) and then get more complex. Starting with the most complex solution leads to more frustration.
In the example of @myaL33 upload.write(chunk, chunk.length) returns a Promise. You can add a then callback and use it to send back a confirmation via websocket to your client to upload the next chunk.
When everything is uploaded you have to send a message from the client, that all chunks have been sent to call the upload.commit to finalize everything with storj (I think).
 ) my silly questions and thinking. And it’s probably worth mentioning that I have no prior experience working with S3 like storage.
) my silly questions and thinking. And it’s probably worth mentioning that I have no prior experience working with S3 like storage.