same problem!

as this seems to be corrected now, what was the cause? As the egress and ingress data has been unchanged how can the Disk space have been changed, for a particular satellite? Who is lying here?
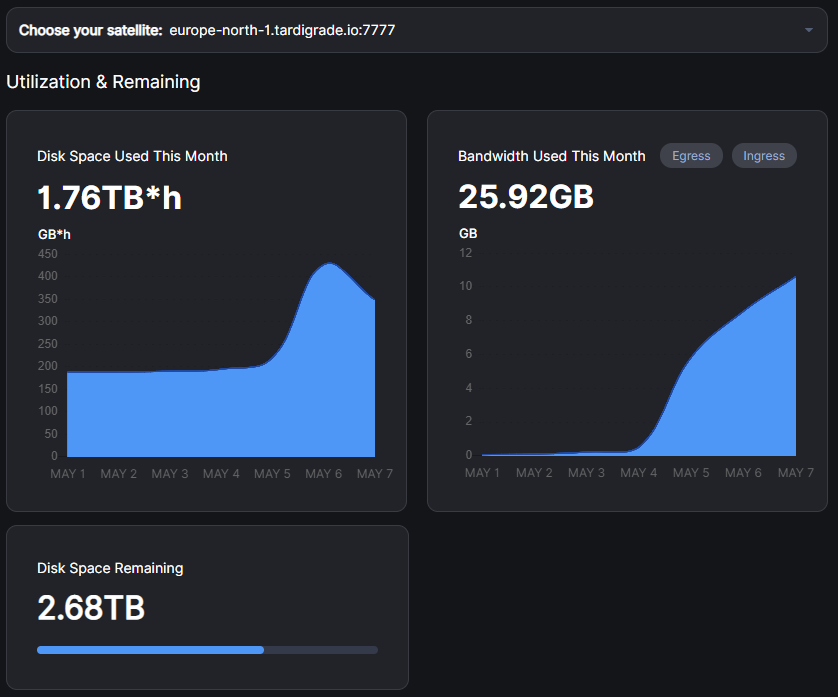
The underlying cause was that some additional limits we put into place for iterating over the database caused the iteration take more than a day. I.e. slowness in the accounting system. This meant that some of the calculation snapshots that usually happen regularly didn’t.
The storage-node dashboard seems to also be affected by not having that data-point. It seems that when storage-node or satellite doesn’t have a data-point it ends up drawing it as 0 instead of what’s the latest known value (or not showing the value at all).
did look very odd, and all the deletions afterwards didn’t help…
now i’ve setup so the space taken up by the storagenode is being logged daily along with the storagenode logs, keeping a track of how many files are coming in, how many files are being deleted and how much space is actually being used.
might not be 100% accurate, but it’s accurate enough for my needs, just so i can verify the numbers i get if i feel like it.
The filter is applied only to IPs. If they from the same /24 subnet, they will be filtered.
No, actually I see its was more relative on european satelitte. For some reasons, the activity is huge on the second, and quite idle on the first. So I guess this is just hazardous the second node is actually getting way more data than the first one since one week. Saltlake traffic seems actually similar at this time. So I guess its okay. IPs from belgian FAIs (Edpnet & Proximus) have their own reserved addresses groups, so they are correctly different (begin by 79, and 87 for the second) so it would be fine filter side.
Saltlake:
N1:

N2:

Europe North:
N1:
N2:

All:
N1:

N2:

No suspension email or on dashboard, so I guess I’m fine Alexey. I just confused the traffic between Saltlake and Europe North, because its like if the european north sat. was sending the test traffic instead, and Salt’ stopped the activity here until now as we can see. And I was wondering if the Storj sat. could see with lag or something my first node as “full” because when it was almost full, I moved my own files to free the space I had defined for my nodes (2x allocated 8tb, but I moved 2,5tb of my own data using the disk since I allocated the node, so I carefully moved them on the another 12tb disk to maintain the 8tb space for the node with no change/interruption) and the node restarted one week ago after a general power outage (with safe power off, pc and routers on UPS), then the Storj update three days ago. So I was wondering if the sat. see my node now with 2,5tb remaining (like reported locally) or assuming its almost full (~100gb remaining if the sat. still kept the old capacity) since the last week (in any case, first node is 12o8Hec8H7UFJF9xdLHei4q6uQQpmdV2DqSmmhCJ83MYSTu5KCs).