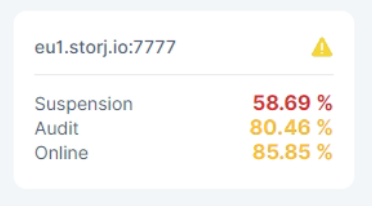
Hello, my node was offline for 6 days, I turned it on again, it’s been 2 weeks, but the percentage of audit and suspended with one of the satellites will not return to normal, it “jumps” all the time. And the message “Your node has been suspended on 12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs. If you have any questions regarding this please check our Node Operators thread on Storj forum” came twice already. I checked the bases with them, everything is fine. There were errors in the logs only when the node was started, and then there were no errors
ERROR collector unable to delete piece {“Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Piece ID”: “2XN6YAQ4WP34R5IAHHAS5VAHCJEWWLJPIDQ67W372GZUBJODBRUQ”, “error”: “pieces error: filestore error: file does not exist”, “errorVerbose”: “pieces error: filestore error: file does not exist\n\tstorj.io/storj/storage/filestore.(*blobStore).Stat:103\n\tstorj.io/storj/storagenode/pieces.(*BlobsUsageCache).pieceSizes:239\n\tstorj.io/storj/storagenode/pieces.(*BlobsUsageCache).Delete:220\n\tstorj.io/storj/storagenode/pieces.(*Store).Delete:299\n\tstorj.io/storj/storagenode/collector.(*Service).Collect:97\n\tstorj.io/storj/storagenode/collector.(*Service).Run.func1:57\n\tstorj.io/common/sync2.(*Cycle).Run:92\n\tstorj.io/storj/storagenode/collector.(*Service).Run:53\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2.1:87\n\truntime/pprof.Do:40\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2:86\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:57”}
How do I fix these percentage spikes, or do I just have to wait for the online to go back to 100%?
Hi @dvortsov,
Assuming no ERROR’s other than ‘ERROR collector unable to delete piece’ are in the node logs then you just need to wait it out. Due to your offline time the percentages will jump around a bit as older successful days fall out of the 30 day window and newer days account for more.
You can also use the node API to check the current state of successful and non-successful audits.
I was transferring data from disk to disk, and towards the end the light went out, I assume that somewhere around 40 GB were not transferred. Then there were problems with electricity, which added to the downtime. If any data was lost due to migration, what can I do now to ensure the audits are successful?
Sometimes such an error still appears:
ERROR piecestore download failed {“Piece ID”: “YFGR7WMHA5ME7FD2YTKUOWJ6Z2WOTNQVFVA3SESGKL7GWUAOGUYQ”, “Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “GET_REPAIR”, “error”: “file does not exist”, “errorVerbose”: “file does not exist\n\tstorj.io/common/rpc/rpcstatus.Wrap:73\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).Download:546\n\tstorj.io/common/pb.DRPCPiecestoreDescription.Method.func2:228\n\tstorj.io/drpc/drpcmux.(*Mux).HandleRPC:33\n\tstorj.io/common/rpc/rpctracing.(*Handler).HandleRPC:58\n\tstorj.io/drpc/drpcserver.(*Server).handleRPC:122\n\tstorj.io/drpc/drpcserver.(*Server).ServeOne:66\n\tstorj.io/drpc/drpcserver.(*Server).Serve.func2:112\n\tstorj.io/drpc/drpcctx.(*Tracker).track:52”}
2 weeks have already passed, about 200GB of new data has been added. Is there any way to find out which folder is responsible for a particular satellite?
You should stop the node, and copy any missing data from the old disk. Don’t overwrite or delete any data on the new disk, only bring across missing files. No wonder audits are failing.
@Stob is right. You might copy over some files that have since been deleted. Don’t worry too much about that, because garbage collection will clean those up eventually anyway. It’s best to make sure that anything that should be there is there. There is no way to avoid audit failures if data is lost. So better have a little too much data there than too little.
audits repeat for ages after files are lost, whatever you can recover will help.
took over a year for a node of mine to be stable at 100% audits.
i accidentally deleted a few files for it…
audits are random, so you cannot tell which files will be audited.
restore the data you got and suffer through the rest…
depending on the size of the storagenode, losing 40GB of data can be lethal for the first 6 months to a year on a new node…
but when it gets to a few TB its usually fine… to improve its chances for survival the best thing is to give it plenty of room to grow, so that the % lost will become less of the whole.
if you cannot restore the files…
just remember not to overwrite / delete the newly uploaded files
i did a rsync --delete which did exactly that