Just a shower thought.
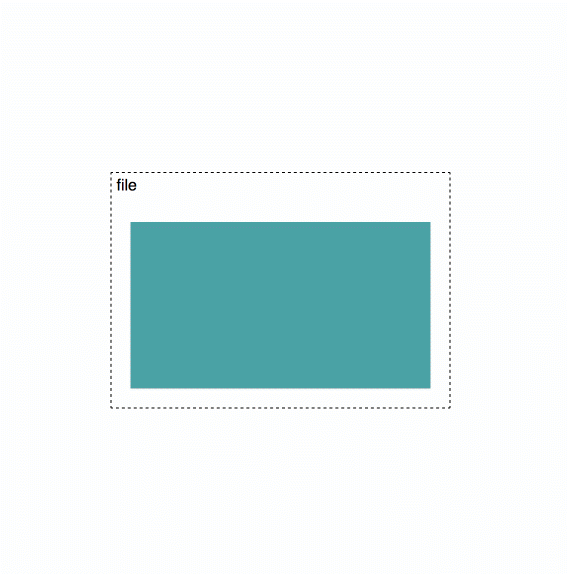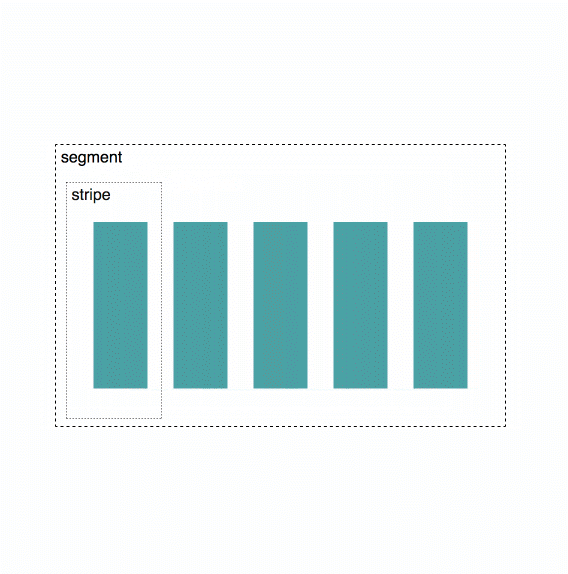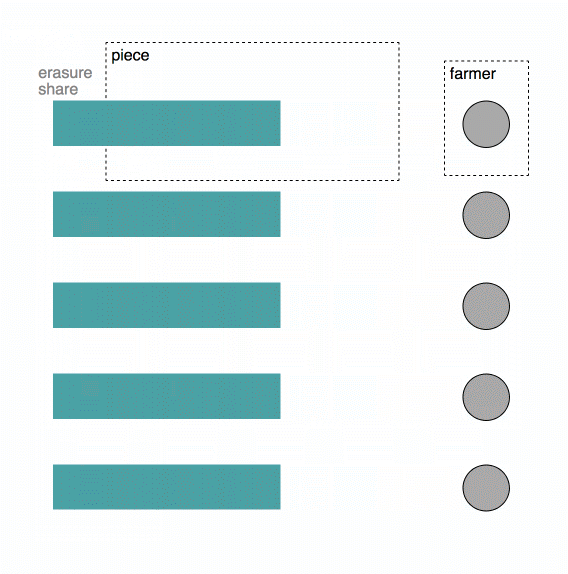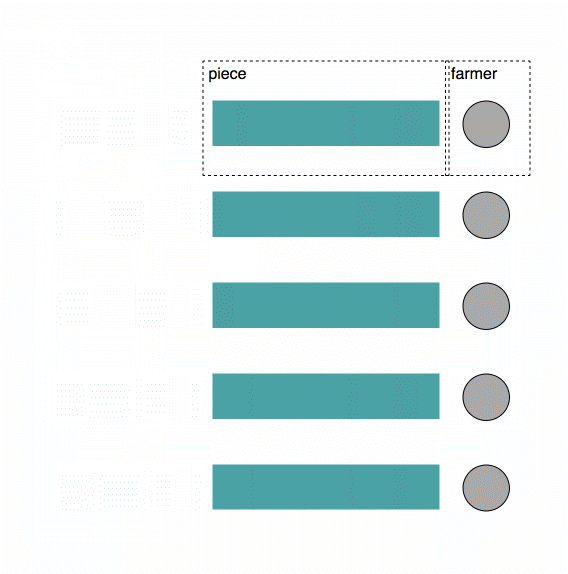
Per whitepaper, erasure coding happens at stripe blocks, and a single segment consists of many stripe blocks. If I understand the code correctly, right now each piece contains data for stripes in the same order, and that’s also the order in which they are then sent over the network:
Assume RS k=3.
-------------------------------time---------------------------------------------->
Node 1: «stripe 1» «stripe 2» «stripe 3» «stripe 4»
Node 2: «stripe 1» «stripe 2» «stripe 3» | «stripe 4»
Node 3: «stripe 1» «stripe 2» «stripe 3» «stripe 4» |
Node 4: «stripe 1» «stripe 2» «stripe 3» «stripe 4» |
Node 5: «stripe 1» «stripe 2» «stripe 3» «stripe 4»
-------------------------------time-------------------------------|-------------->
download finishes here
So, download ends when the last stripe has data from 3 pieces.
But we could try to (deterministically) randomize the order of stripes received. Here I’m not changing the delays, just the order of stripes:
-------------------------------time---------------------------------------------->
Node 1: «stripe 4» «stripe 3» «stripe 2» «stripe 1»
Node 2: «stripe 1» «stripe 3» «stripe 2» «stripe 4»
Node 3: «stripe 2» «stripe 1» «stripe 4» «stripe 3»
Node 4: «stripe 4» «stripe 1» «stripe 3» «stripe 2»
Node 5: «stripe 1» «stripe 2» «stripe 4» «stripe 3»
-------------------------------time----------------|----------------------------->
download finishes here
Here, the download can end earlier, because we can leverage stripe 1 data from nodes 2, 3, and 4; stripe 2 from nodes 1, 2, and 5; stripe 3 from nodes 1, 2, and 4; and stripe 4 from nodes 1, 3, and 5.
This way we would get faster downloads, possibly less bandwidth overhead from not wasting data received from slower nodes at the cost of uh, a bit of complexity between the node and uplink, plus teensy-weensy more complex accounting.
Also, time-to-first-byte would be worse, so this shuffle could be an opt-in.
What do you think?