obviously i’m talking about the option that is actually on the list… sorry my mistake for calling it stripe size, and to be fair for all the testing i’ve done on my lsi controller running raid5 and on zfs the best results have been with the larger chunk / record sizes.
had to go check this… but yeah it also seems that on LSI controllers the chunk size is also called stripe size… one is just called virtual stripe size and the other is called disk stripe size.
seems that there is not much agreement on the naming schemes across the different brands.
i’ve had continually poor results when having to resilver or migrate the storagenode data and also when doing tests with other more usual large video files…
in the documentation from LSI we also see the same pattern… they recommend 64k-1mb range for larger files and for small database loads they recommend the smaller sizes…
and since we are dealing with rather large files then having good random io in the smaller ranges doesn’t make great sense… since 90+% of the files are 2200kb running to small chunk / virtual stripe size / recordsizes will just increase the required IO to read each file, everything else will be using the cache anyways… when running write back… tho i did ofc run my tests without the lsi controller caching because i wanted to get the raw disk results and not the controller caching.
with that on using 3 tb drives in a raid 5 i got the optimal results at 256k virtual stripe sizes/chunk / recordsizes… tho this never saw much testing on a storagenode i think… can’t remember it was like 3 years ago now…on V2 so again the result from then might not be nearly as applicable to 10tb drives or raid 6 but no matter how much i dig into it then it has been a persistent thing i’ve run into repeatedly… 128k seems to be the best avg result in virtual stripe size and for storagenode i might even go with 256k… ofc now i’m only on zfs… but funny enough i’m back at next time i migrate my node i will go back to 256k, because my ram utilization is a bit wasteful…
it’s not really that larger virtual stripes sizes makes systems run worse… one generally just runs into cache and ram issues, generally everything runs better except of tiny random io in super large datasets… and still oracle use to run up to 16mb virtual stripe sizes… for good reason… the larger the dataset and storage gets the bigger everything has to go… sadly cache and ram quickly becomes hard limits.
looks like a perfectly good point to set it… 256k should be perfect
i’m running 512k and it does eat a bit to much ram for my liking… but 10tb node not really easy to change it all now … but i might also go 256k if i could switch easily lol… seems that i change it once a month since i started running the node xD
Settings in NTFS format, do not consume RAM memory. We have already told you many times that you cannot compare your configuration which is in Linux with Windows server.
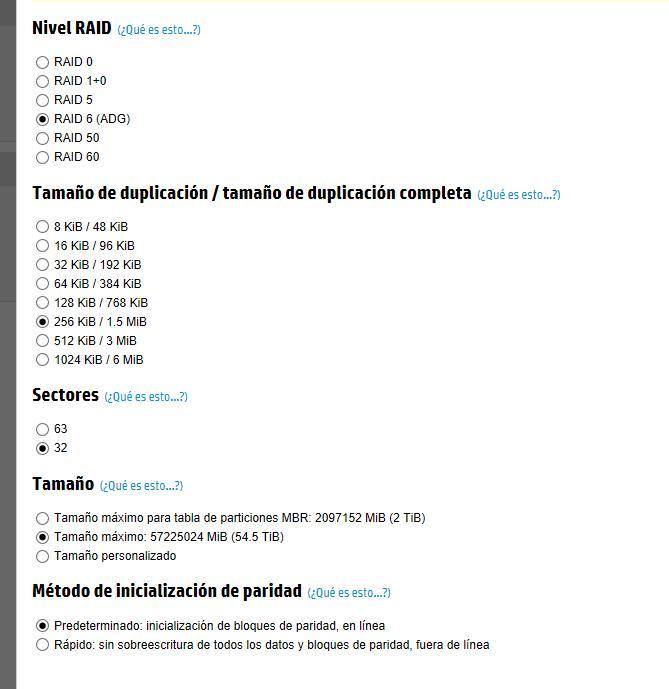
I’m a little surprised by that default. That seems high to me, since it requires files to be at least 1.5MiB to be spread across all disks. Smaller files will see less of a read performance improvement and would basically have the same write performance of 1.5MB files as every write would require recalculating the parity of that entire block. I would go with 64KiB to be honest, maybe 128KiB. But it might be worth doing some googling yourself for advise on similar RAID setups. Keep in mind that especially the db’s get a lot of small db writes which could lead to fairly significant overhead with 256K/1.5M size, unless you have an SSD read/write cache.
it’s complicated… no the block or stipe/chunk/record sizes doesn’t directly use an extra ram… but if … lets use the database example… if system need to load 500 points of data from the drive… then at say 128k it needs to dedicate 500 x 128k ram for that, while at 256k it will need to dedicate 500x256k so twice the same amount for the same data being loaded into memory…
this is not relevant in all workloads and is often mitigated by caching, but it can be a real problem…
like if i got and check my current ram usage i’m at a sad 44.6% because something have flushed the ram, because it thought it needed space to contain data…
this happens because im running 512k
when i was running 32k my ram utilization would be basically steady at about 75-90%
so yeah it doesn’t technically use ram, but it ends up flushing more ram and using more cache to make the system run right…which can create other issues.
its the only reason my i want to give it one notch closer to 128k…
for my high ram usage is good… windows just lies about it, shows you the ram you have accessible because it contains data that can be discharged instantly.
this has nothing to do with OS, it’s a hardware thing…
aren’t you comparing microsoft file systems with raid now… i don’t think raid distinguishes between different files… it can happily write two files in one stripe.
Where did I say it couldn’t? All I said is that it has to recalculate parity for the entire block, which means reading, calculating and writing the entire block. Of course it can store multiple files in there, that’s not the point. It’ll have a performance impact.
Also, I’m nearly certain the memory argument doesn’t apply at all. 1. This is mostly a ZFS thing. 2. A RAID controller is being used which should use its own RAM to perform these functions.
In the end I put the 64k band size, HP recommends that for RAID5 AND 6 smaller band sizes. I didn’t remember the guide inside the SSA, I read it a long time ago.
“The band size is useful for adjusting the performance of a given logical drive. In harsh environments, try different band sizes and use the one that fits your environment best. In a mixed read/write environment, the given bandwidth size is recommended. In an environment with more reads than writes, larger band sizes are usually better. In an environment with more reads than writes using RAID 0, RAID 1, or RAID 1+0, larger band sizes are recommended. For RAID 5 or RAID 6, smaller band sizes are recommended.”
@BrightSilence It was definitely 64k for the band size, and 64k for the file system. There is very little time left to finish all the parity, to improve the performance of the whole set of discs. Thank you all for participating!
Hi,
Didn’t really catch if you proceeded with the switch or decided to leave it as is.
The simplest steps for it, as I found out here in the forum and outside, is - as long as your node isn’t too big.
This is what I did when my notebook (with windows) was too unstable and I decided to move files to my NAS (linux based) (after test it if STORj works there at all
It took me about 5 hours of transfers through 1Gbit network for ~300GB node.
Your migration could be faster (probably) - with no network transfers
Connect external drive that can handle amount of data (smaller node -easier).
Run Windows Rsync - free tool - (from drive to drive) (with mirror option) - don’t turn off your node - rsync will make a snapshot of file structure and will start the copy process. It may take few hours or days even (my 300GB node over 1GB ethernet took about 5 hours) - your copy could be faster because it will be the same machine, faster disks, etc.
When first Rsync run finishes, start again - it will now make new snapshot with new files and remove files that were deleted. It will take much less time depending how much new data came during the first rsync run.
keep running Rsync until it takes less than a 2-3 mins to finish syncing- it is time to shut down the node. (for me it was 3 or 4 times during the big traffic last month)
Prepare new config.yaml file pointing to the external drive. Backup original file.
Shut down node. (offline timer starts now)
perform last rsync to copy the static image of the node.
Switch the config file - steps 6-8 should take no more than 5 minutes.
Start the node with new config file pointing to external drive (it would take 5 minutes? 10 tops) offline timer stops here
Confirm by watching the logs if everything is ok - no errors - Mine was working for few hours before i started noticing DQ warnings. Use earnings estimator to watch the logs. Restart node frequently (every ~30 minutes) to force dumping the logs - it tends not to update them frequently (at least on linux)
If ok destroy the raid and recreate it with raid6. (this may take some time as I understand) - but your node is running happy from external drive at this time.
When raid is finished. Start Rsync the other way around. steps 2-9 reverting the config file to point to new raid.
Assuming that nothing crashes, and choosing low traffic days (after big tests are done) offline time of the node would be way below 30 minutes ( in total).
The biggest challenge is to be sure that config points to proper folder structure - so your node won’t start from scratch - it may lead to DQ very fast, because satellites have a list of files that should be on your node. If node starts saving files to bad path, you have to correct the path in config file and move new files to proper folder structure (don’t delete them, just move the parent folder to correct parent folder of the old node ).
You can even start new node (with new identity!) (just for couple of minutes/seconds) for tests to see if it works properly (creates proper folder structure in place where it should be), and then destroy it.
Hope it helps.
The risks that I can think of, are : correct paths. external drive not dying during the process , power outage (but I assume that it is backed with UPS as seen on picture)
i’m running an old rack server, tyan s7012 dual socket xeon L5640 2.13ghz 4core / 8 threads pr cpu
48gb ecc ram, with 2 x LSI HBA’s serving a 12 x 3½" front loaded disk bays backplane.
storage is a zfs pool of 3 raidz1 of 3 drives each, + 1 old MLC (i actually think it’s a first gen consumer ssd) 256gb sata ssd on which run the OS + SLOG and a second more modern QLC 750gb sata ssd which i have solely dedicated for L2ARC and partitioned to 600GB to reduce wear.
(i really should restructure this a bit and do a maybe 200GB mirror boot pool across both ssd, to give the OS an extra level of redundancy.)
(was the best performing easy to manage setup i could handle, if i was recreating the pool today i would have done a 3 x raidz1 of 4 drives… i found out my onboard SATA controller can manage modern disk sizes, or maybe it routes it through the more recent HBA’s not quite sure… most hardware of this age run into a 2TB max drive size, but for whatever reason it doesn’t seem to be a problem.)
have a “small” 2 hdd x 6TB SAS mirror pool for personal usage, but most stuff do end up on the storage pool, because it has the SSD cache.
everything is running Sync always to ensure against data loss on power loss since i doubt my ssd’s have whats it called… PLP (power loss protection) i think it is… and for my amazing electrical safety i got a 10$ power strip xD with surge protection lol
and my entire network is rigged together with old 1gbit routers converted into switches… of which there is 3 - 4 or so… i really should get those replaced, but i was kinda hoping to get some 10gbit in there somewhere…
the server has two onboard 2 nic’s for a total of 4x 1Gbit ports.
the reason i run 3x raidz1 is to triple my zfs pool’s raw iops
because disks in raid run in harmony their IO will be limited to the slowest hdd in the array / raidz and no matter the number of drives the pool / array IO will never exceed what the slowest drive can manage…
i’m running 512k recordsize on the storagenode dataset and else stuff is all the zfs default of 128k records, however zfs records are variable size so the recordsize is the max size, not the size that all records will be… however like mentioned in the previous comment, the RAM allocation can get a bit excessive with 512k recordsizes… because it release ram for a expected number of records or something like that… advanced stuff i don’t know all the details… so if it expects like say 5000 records, then it will dump 5000x 512k memory … so it adds up real quick…
so even if the 5000x records are just 4k records it will still dump the max amount because it wants to be ready for the data or something…
like if i start a scrub it will do like 500000 reads a second ofc most of that in the arc… but that will make the zfs dump most of my arc for no good reason…
but i figured it will take basically forever to switch to 256k now… and it does make my scrubs run incredible… last scrub on the 14 tb of data on the storage pool took 12 hours
and i can most likely shave a couple of hours off that if i delete some old test files i made which are just a few million empty 10byte files
i really like the iops the pool got with this 3x raidz1 setup… the hdd’s alone will do like 4000 reads a second.
all of my drives are a mix of 3tb and 6tb enterprise sata + 2 sas (later found out that i cannot use sas in pools with sata… which gave me a ton of grief and data errors… zfs took it like a champ tho.
never lost a byte… and not for lack of abuse… thus far i’ve removed beyond the redundancy drives while using the pool… (can’t recommend that tho)
had a while i was trying to get gpu passthrough to work… which ended up making the server unstable, and took me a few days to figure it out and solve the issue… meanwhile the server just rebooted at random… must have hard reset the machine 40 times… and still didn’t loose a byte
thats the power of sync always… never had my storagenode have any corruption of the data bases or such damage…
oh yeah i also run patrol scrubs on my memory, ofc there are many more even less relevant things…
i wrote a slightly structured HA setup, if you are interested in the thought process behind trying to integrate basic HA concepts in your system… ofc if the hardware allows…
you can find it in the SNO Flight Manual - here
maybe i should write one for RAID… also… hopefully it will be a bit more structured that this one… tho i have tried to make it better and going through it again… should be worth a read, if you made it this far lol
but yeah my setup is lots of old hardware, the server was mostly just because i really wanted a server so i could run some vm’s and play with enterprise hardware…