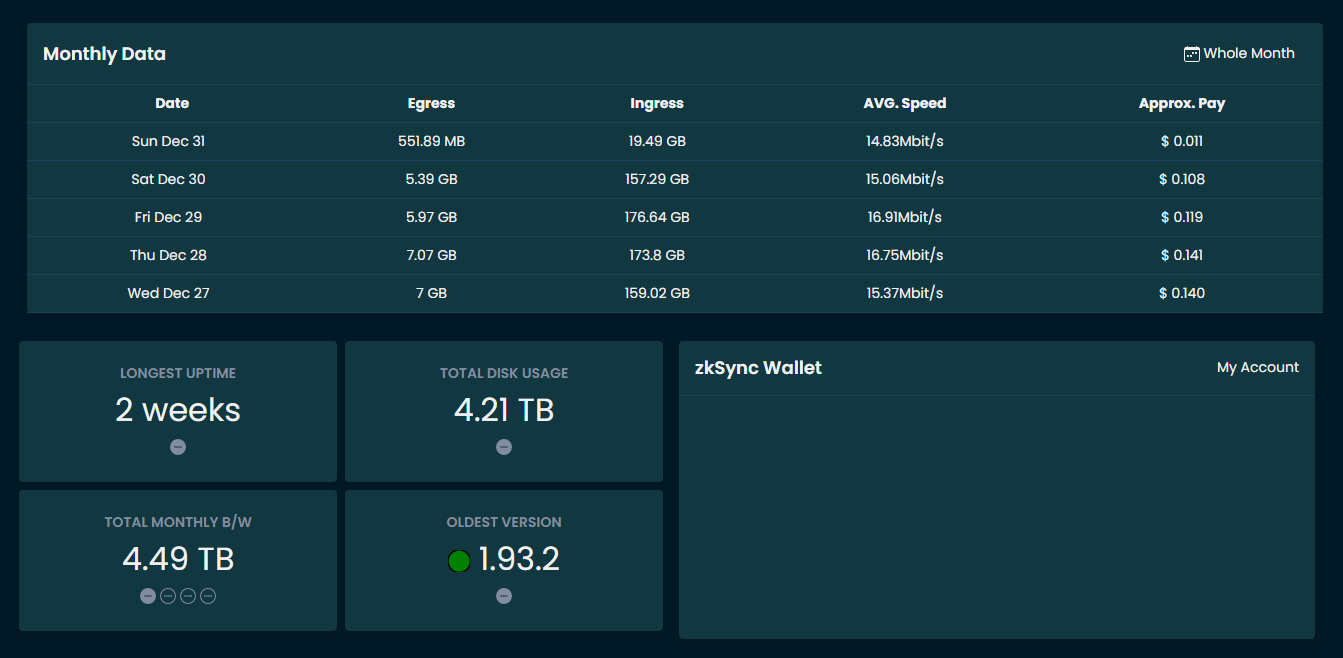
Throwing this out there for those considering becoming a new Node Operator and for existing SNOs to benchmark…
27 months ago, I deployed a new server that I knew was (at the time) over-provisioned on its storage subsystem. I allocated 10TB to Storj and left it running 24x7x365 on a 600/400Mbps unmetered, fiber connection.
Today, after more than two years, I hit 99% usage (or 9.9TB+) in my node’s dashboard. Generally speaking, the node has maintained at least 98.5% monthly availability across all Storj satellites, but I did have one month where I hit 97% due to some hardware issues and an extended power outage in the same month. As many others on the forums and elsewhere have pointed out, running a Storj node is not a “get rich quick” proposition.
For those who are curious, my node is running Ubuntu 22.04 with a modern, 12 core processor and 64GB ram. Storage subsystem is 4x8TB SATA HDDs configured as a ZFS striped mirror with compression enabled and a 256GB SATA SSD read cache; for a while, I was using a NVMe partition as a write-cache, but I removed it from play as I’ve never had much by way of IOWAIT time or other disk bottlenecks (other than during the Storj filewalk on startup or ZFS scrubs). (Again, I have other business use cases that necessitate better disk fault tolerance vs. the 1-disk, 1-node that’s often recommended for Storj nodes.) The server is still underutilized for its original purposes, so Storj is happily consuming much of its resources.
I am curious from other SNO’s–does that metric–10TB in a little over 2 years–seem consistent with your experience? Is my node under-performing? Over-performing?
And kudos to the Storj team! The Storj software has played nicely with the rest of the server’s software, keeps itself updated, and is very, very low maintenance from this SNO’s perspective.
27 months for 10 TB seems excessive. This averages to 0.37 TB/month. Where in the world are you?
My first node started in Aug 2022 now has 9.0TB stored (averaging 0.6TB/month)
Another node started in Dec 22 now has 6.5TB (0.6 TB/month)
The third one started in July 23 has 2.3TB (0.5TB/month).
All three are on the US West coast, in California (first two) and Arizona (last one). all run on variety of old servers. Mostly super micro x9.
There were a bunch of large deletions in the past, so that may skew the results.
I think the recommendation is that if you want to run three nodes, your array shall have at least three disks, to share expected IO load. Otherwise it makes no sense.
+1. Literally money printing machine. I did have to create an updater for freebsd, because the original one is broken, but that’s the extent of my invasion into its internal working.
I have 24 nodes actually, for end of this month i create other 6 nodes . i have 5 location of the nodes are position in Italy with 2 pubblic ip for every location. obviously not all the nodes are currently on 42 months but the nodes have been created gradually over the years. the youngest today is 4 months old and the oldest is 42 months old, everyone else is in between
I just got back into storj a few weeks ago and have filled just over 10% of the 10TB allocated drive already and that was with some supposed quic configuration issues which didn’t exist it was somewhere after my isp and resolved itself eventually, but why do I hear people taking so long to fill these drives? Granted I have it running on a secondary desktop thats not doing anything else really unless I VNC into it to access tor or something but 99% of the time it has 64gb of ram and 16 cores to facilitate the i/o.
I am just trying to understand it more because I want to now create a VM on my enterprise grade server and dedicate it to storj and am trying to figure out the best way to configure it. I want to limit the nodes to around 20-24TB each it seems right? So would it be best to have a VM for each of them or do a container for each or what? And what does everyone else use for caching when they are trying to scale the operation on here is it best to just use primo cache or something and allocate a certain amount of super fast storage from my ssd raid for each drive to ensure there is never any bottlenecking caused by limited read write speeds of the Hard Drives? What is the limiting factor that makes it take so long to fill each node? If use multiple broadband connections instead of running all on one external IP would that say double the rate the nodes fill if I used two different connections with 2 external IP addresses vs 1 or is there something else limiting the rate? Computing power and ram are not an issue I have 88 cores and 1tb ddr4 to allocate and plenty of fast storage to cache with if need be. I want to utilize all my drives I was using for chia before and start filling them and earning with storj but there doesn’t seem to be a lot of information or guides for doing this on a large scale like there always were for chia and fil and others. Seems like everyone is just quessing and trying different things with no real documentation from the developers to actually steer people in the right direction.
You have 10 public IP addresses? Did you work that out with a company that provided you with a fiber connection or something? Or are you just creating these different public IPs virtually on different VMs using externally hosted servers that you tunnel them to?
If your node is new, you will get extra data for a while during vetting. This is supposed to change at some point, as I understand it, but for now it is still a thing. So, the initial data flow on a new node is going to be more than an established node but only for a little while.
There is also a bit of potential if your node happens to be “near” a heavy uploader. Assuming your node is winning most of the races because of low latency, you could expect a higher intake of data. But this is uncontrolled luck.
Lastly, some older nodes lose data as new data is added. So, their net growth is smaller than a new node that is gaining without losing. Some of that loss may be related to Storj purging old test data, but I don’t know how active they have been with that recently. I’ll make a note to ask about it in our next meeting.
Hardware doesn’t really matter, you may check the resources usage for your first node.
The limiting factor is customers, the usage depends on them not on your configuration.
Of course the inefficient configuration may affect the usage, like using network filesystems, SMR drives or slow filesystems like BTRFS or zfs without caching device, or use exFAT with its gigantic cluster size, or using NTFS under Linux.
By the way, VM may slow down disk operations as well, the host’s cache likely will not be used for VM’s operations and you may start to have a problem with discrepancy between confirmed used space and actual used space because of failed filewalker due the high latency.
I have 5 Nodes in 2 Locations, the oldest node is about 1,5 Month old.
Location 1: Storj99_1, Storj99_2 and Storj000
Location 2: Storj100 and Storj101
Storj99_1 and 2 are running both on one Pi 2 (2x 500GB Drives)
Storj000, 100, 101 are running each on a own Pi3b (Storj000 6TB Drive, Storj100 1TB Drive, Storj101 2TB Drive)
Hi, I have 5 fiber connections with a local provider in Italy that provides multiple public IPs on different subnets on the same fiber connection. In fact, 1 week ago I requested 4 more IPs which will be assigned to me shortly. The cost of this service is truly trivial, €3 per month for each IP which pays off abundantly with medium/large sized nodes. Obviously the 5 fiber connections located not only serve the nodes but also provide other services for my work. Today I am already at 120TB shared with around 100Tb already filled. By next month I will move to around 200TB with the migration to new HDs that are arriving.