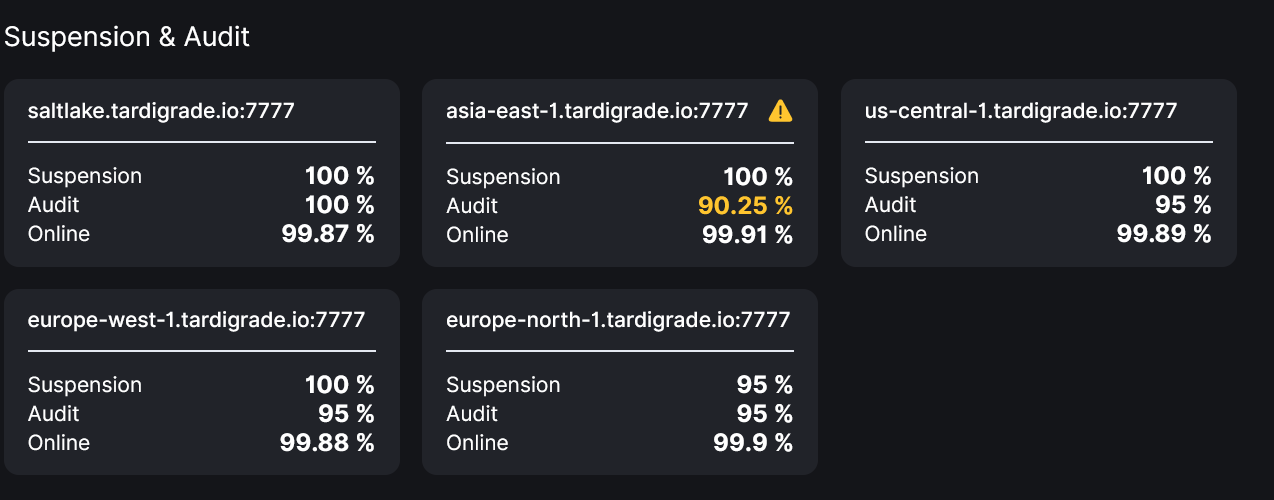
My node hanged itself completely due to the update last night and crashed my entire RaspberryPi. Storj no longer had access to the hard drive, but the node was online, so I missed a lot of audits. 4 hours … All other nodes with version 1.16.1 continued to run without problems.
I’m curious if that happens on my other nodes too …
Oh my, that’s seriously concerning, considering that this situation should never happen again since one of the latest versions: Now, when the disk becomes unreachable, the node should shut down itself with an error, to avoid audit failures!
Are you sure your node had no longer access to it? Because if the disk was actually still reachable but unresponsive (which is different), then that could explain a few audits to fail if the disk took more than 5 minutes to seek audited files.
But even if it’s every few minutes: my nodes don’t even get one audit per hour (and per sat’), one would be unlucky to fail 1 audit during a few minutes window.
A score of 90% suggests that @LinuxNet’s node failed 2 audits on the same sat’, I reckon. They say the problem lasted for 4 hours, that’s why I’m suggesting the disk wasn’t not entirely disconnected… the node should have shut down way earlier otherwise.
I may be missing something but it feels to me like we’re not completely clear yet on what happened exactly
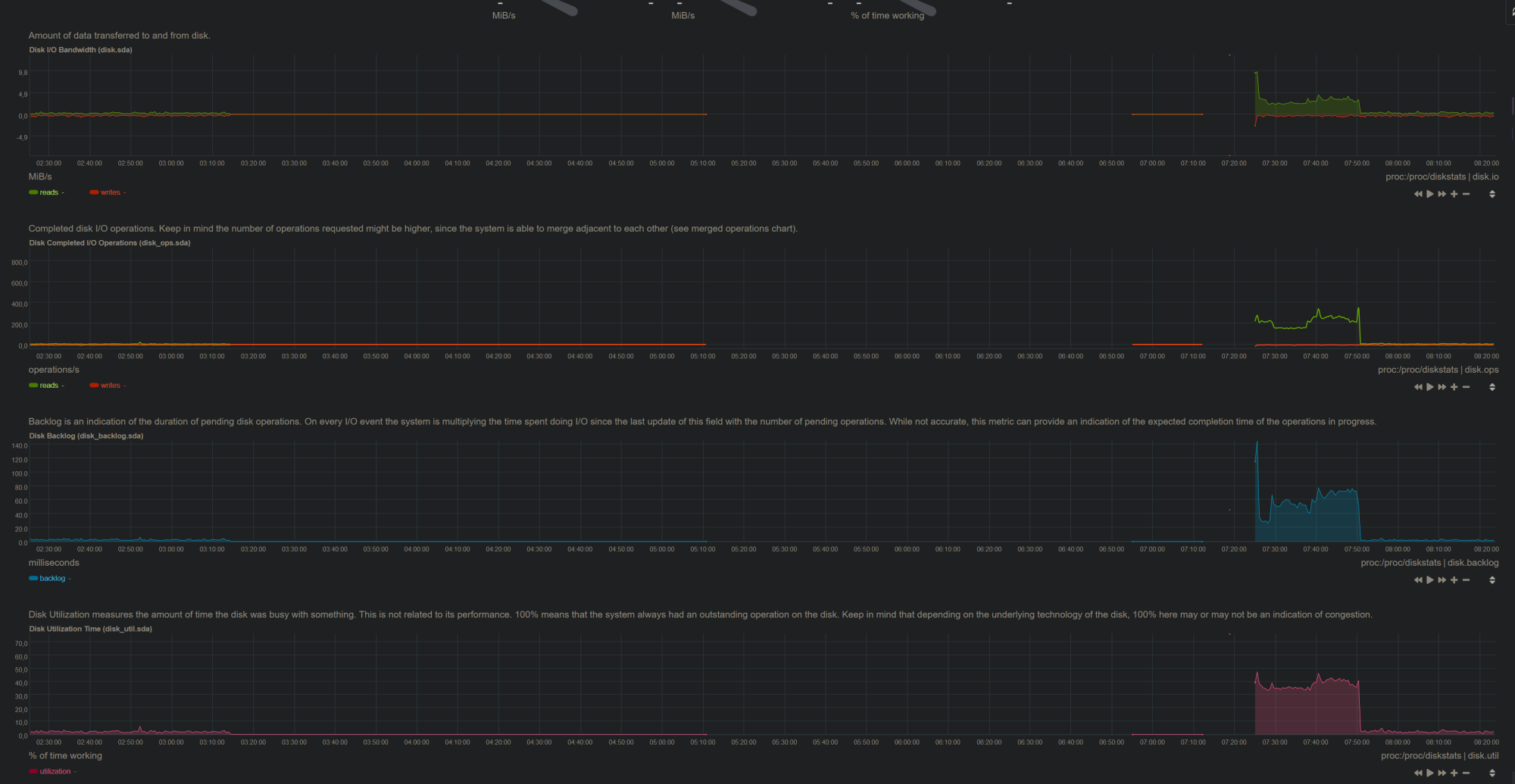
I can only say that the nodelog ends with the update and only started again when I completely restarted the server. InfluxDB was also unable to write any data to the hard drive during this time. I think that the hard drive was still “there”, but was no longer writable or readable. I just find a bunch of logs that applications could no longer read or write to the hard drive. The hard drive has no errors.
Looks like the hard drive was still accessible but not usable. Afterwards it doesn’t have to be available anymore. The node continued to run until the server restarted.
Okay and while I was writing that another node was updated without any problems. Doesn’t seem to be an update problem… @Alexey can you move the posts to a separate thread? Thank you.