I have got two emails that says my storage node is suspended. I have just installed the node 2 days ago on linux ubuntu server 20.04.
Email: “Your Storage Node on the saltlake Satellite was suspended. You were suspended on 2020-05-19 at 00:43 UTC. You won’t receive any new data on this Satellite until you resolve the issue causing audit failures on your node.”
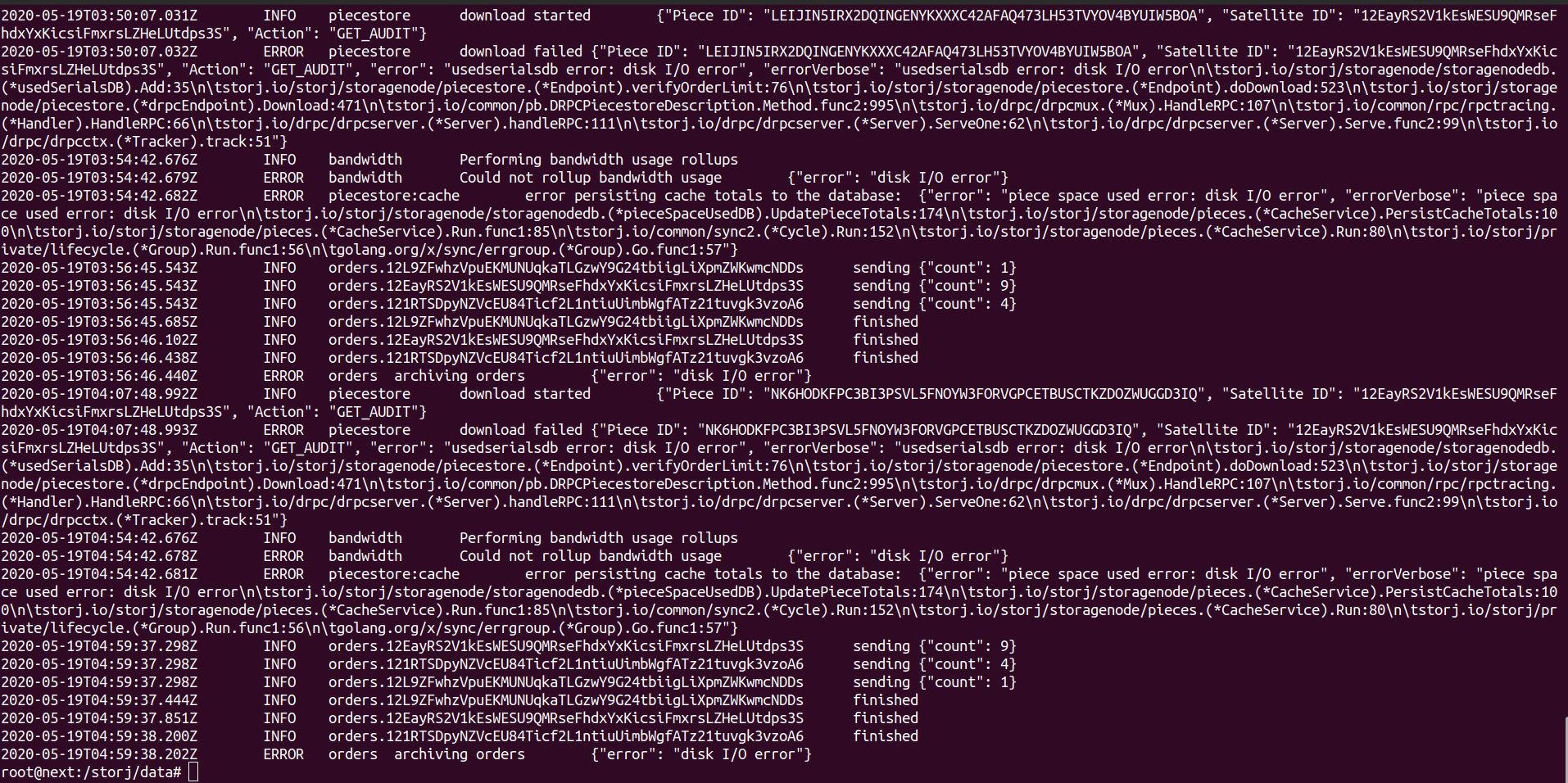
LOG:
2020-05-19T03:56:46.440Z ERROR orders archiving orders {“error”: “disk I/O error”}
2020-05-19T04:07:48.992Z INFO piecestore download started {“Piece ID”: “NK6HODKFPC3BI3PSVL5FNOYW3FORVGPCETBUSCTKZDOZWUGGD3IQ”, “Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “GET_AUDIT”}
2020-05-19T04:07:48.993Z ERROR piecestore download failed {“Piece ID”: “NK6HODKFPC3BI3PSVL5FNOYW3FORVGPCETBUSCTKZDOZWUGGD3IQ”, “Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “GET_AUDIT”, “error”: “usedserialsdb error: disk I/O error”, “errorVerbose”: “usedserialsdb error: disk I/O error\n\tstorj. io/storj/storagenode/storagenodedb.(*usedSerialsDB).Add:35\n\tstorj. io/storj/storagenode/piecestore.(*Endpoint).verifyOrderLimit:76\n\tstorj. io/storj/storagenode/piecestore.(*Endpoint).doDownload:523\n\tstorj. io/storj/storagenode/piecestore.(*drpcEndpoint).Download:471\n\tstorj. io/common/pb.DRPCPiecestoreDescription.Method.func2:995\n\tstorj. io/drpc/drpcmux.(*Mux).HandleRPC:107\n\tstorj. io/common/rpc/rpctracing.(*Handler).HandleRPC:66\n\tstorj. io/drpc/drpcserver.(*Server).handleRPC:111\n\tstorj. io/drpc/drpcserver.(*Server).ServeOne:62\n\tstorj. io/drpc/drpcserver.(*Server).Serve.func2:99\n\tstorj. io/drpc/drpcctx.(*Tracker).track:51”}
2020-05-19T04:54:42.676Z INFO bandwidth Performing bandwidth usage rollups
2020-05-19T04:54:42.678Z ERROR bandwidth Could not rollup bandwidth usage {“error”: “disk I/O error”}
2020-05-19T04:54:42.681Z ERROR piecestore:cache error persisting cache totals to the database: {“error”: “piece space used error: disk I/O error”, “errorVerbose”: “piece space used error: disk I/O error\n\tstorj. io/storj/storagenode/storagenodedb.(*pieceSpaceUsedDB).UpdatePieceTotals:174\n\tstorj. io/storj/storagenode/pieces. (*CacheService).PersistCacheTotals:100\n\tstorj. io/storj/storagenode/pieces. (*CacheService).Run.func1:85\n\tstorj. io/common/sync2. (*Cycle).Run:152\n\tstorj. io/storj/storagenode/pieces. (*CacheService).Run:80\n\tstorj. io/storj/private/lifecycle. (*Group).Run.func1:56\n\tgolang. org/x/sync/errgroup.(*Group).Go.func1:57”}
2020-05-19T04:59:37.298Z INFO orders.12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S sending {“count”: 9}
2020-05-19T04:59:37.298Z INFO orders.121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6 sending {“count”: 4}
2020-05-19T04:59:37.298Z INFO orders.12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs sending {“count”: 1}
2020-05-19T04:59:37.444Z INFO orders.12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs finished
2020-05-19T04:59:37.851Z INFO orders.12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S finished
2020-05-19T04:59:38.200Z INFO orders.121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6 finished
2020-05-19T04:59:38.202Z ERROR orders archiving orders {“error”: “disk I/O error”}
MY DATA FODER:
root@next:/storj/data# ls -l
total 40
-rw------- 1 root root 7701 May 17 17:46 config.yaml
-rw------- 1 root root 32768 May 17 17:54 revocations.db
drwx------ 6 root root 4096 May 17 17:54 storage
-rw------- 1 root root 1430 May 18 06:34 trust-cache.json