Hello,
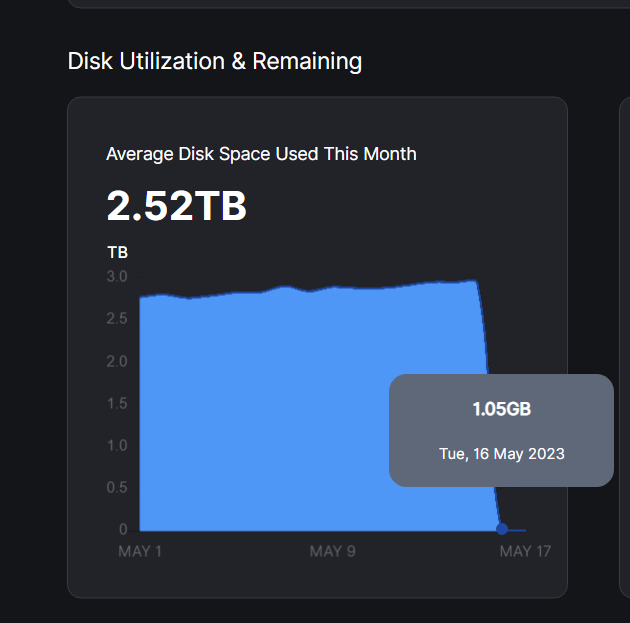
i am currently running 6 Nodes. 5 are on one machine and 1 on a different location. I use the Multinode Dashboard to show all together. Since yesterday the graph “Disk Space Used This Month” show very little.
My Question is if i have to worry about that. What got me wondering is, that it affects all nodes at the same time despite the physical and network seperation. (One in a Datacenter and one at home)
What could cause that?
I checkt log and everything looks normal. I Checkt the node specific Dashboards and there is the same problem (So no Multinode-Dashboard Problem)
We’ve seen similar issues be resolved automatically on the next reports from the satellites, but this is kind of messing with what the nodes currently show. (Also in my earnings calculator)
Same here for all 6 nodes, also ingress suddenly went to half of the average daily, egress repair went to zero.
They are probably doing stuff on the satellites, lets hope they can fix it soon.
It hasn’t had an impact on segment availability on customer facing satellites at least. Minimum availability across segments on all customer satellites is 51 pieces. Well above the 29 minimum required. However, test satellites look weird… though this is almost certainly a reporting issue and not actual loss of pieces. It’s possible they stopped/paused repair due to something related to this.
I can’t promise that. All I can say is that it’s not something wrong with your node specifically. And these kinds of errors have resolved itself in the past. Only Storj Labs can confirm whether that would happen now as well.
I am running two nodes in two different locations and I noticed that from yesterday the “Average Disk Space used This Month” became “0 Bytes” on both of them.
Could someone explain why is that happening and how could I possibly fix it?
Thanks a lot in advance for your prompt attention to this matter.
At my place it has been fixed now.
If you check out per satellite, you can see that not every satellite has already reported back. Don’t worry, it probably will be ok!