i have no clue why i got disqualified, i have checked the log and come up with only 6 failures to upload a file
get-content “C:\program files\Storj\Storage Node\storagenode.log” -tail 1000 | Select-String -Pattern “failed”


Because of this
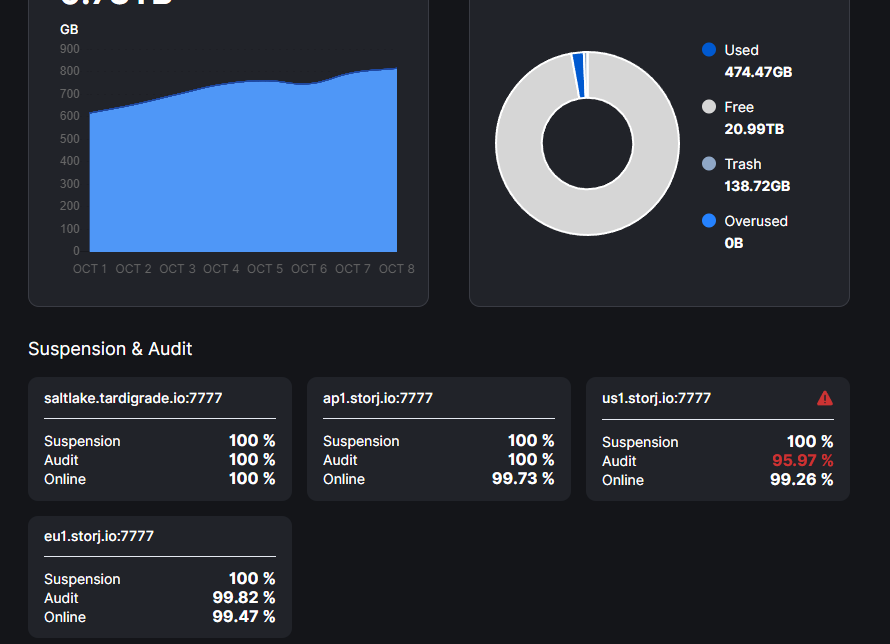
Audit
95.97 %
Your nod lost data.
but how can i find where i lost the data, this log is 6GB its crazy hard to parse?
also at this point what do i need to do delete the entire install and start a brand new node?
i may have my own answer… i have noticed that the server running this with 32GB of memory has been running at like 99% memory utilization. in other threads it sounds like this memory bleed can occur if the drive holding the database is not fast enough to keep up. if i was under this much memory pressure is it possible that that things could have just gone pear shaped over night ?
I’ve read somewhere that besides actually losing data and failing audits, audit score can drop if the node does not process repair requests in time. What you describe might as well be explained by that.
You woudl need to grep for audit failures, and then search for the corresponding bit. But based on what you are saying, the problem is likely failed repairs – you have data, but did not respond in time.
You are only disqualified on one satellite, albeit on the one with most traffic. If you just start a new node and change nothing else - it will face the same fate.
Perhaps it’s a silver lining here - now that your node is not going to receive US1 traffic, it will be able to handle remaining traffic.
But you plan to fix hardware configuration for it to be able to handle the kind of IO pressure storagenode requires (the is massive number of discussion on this forum) – then yes, I would start a new node.
So I read only one disk is needed so storage pressure shouldn’t be wild but a million tiny files is expensive on io. Any video the performance reqiments? All the docs indicate hardware reqs are tiny tiny but doesn’t seem it
A large contributor to performance is amount of available ram for metadata caching, how you configure the mount, whether you disable sync and atime updates, and other system configurations to support his high IO usecase. Then HDD absolutely can sustain current storagenode workload.
Moving databases to an SSD can further offload the IO from the disks.