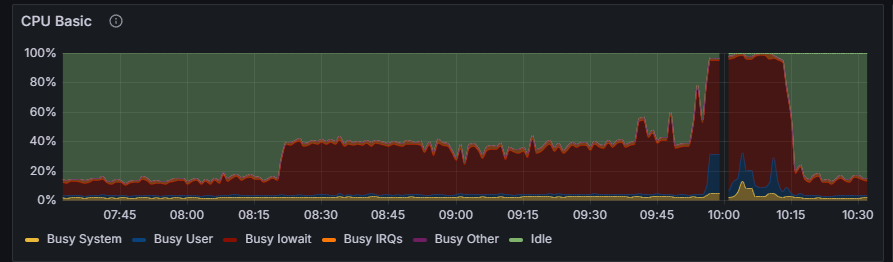
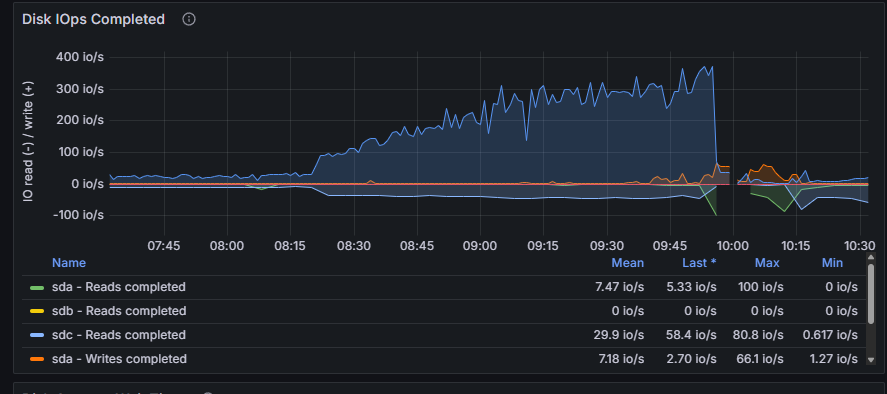
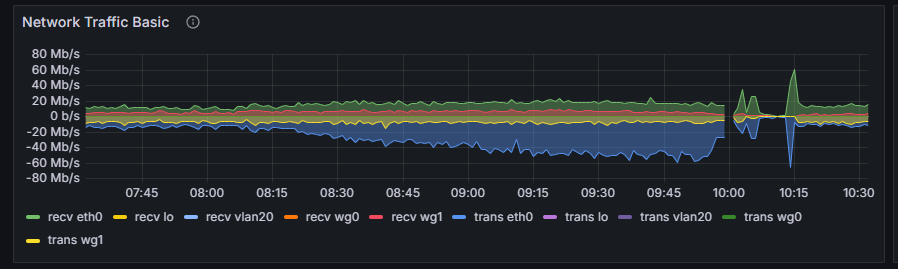
Hi
Noticed my Audit on one of my nodes took a very tiny hit. Not really bothered about that per se, but went looking to see if I could see why. Found the following in my logs:
2025-05-22T23:19:53-07:00 ERROR services unexpected shutdown of a runner {"Process": "storagenode", "name": "piecestore:monitor", "error": "piecestore monitor: timed out after 1m0s while verifying writability of storage directory", "errorVerbose": "piecestore monitor: timed out after 1m0s while verifying writability of storage directory\n\tstorj.io/storj/storagenode/monitor.(*Service).verifyWritability:184\n\tstorj.io/common/sync2.(*Cycle).Run:163\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func2:114\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:78"}
2025-05-22T23:20:09-07:00 WARN servers service takes long to shutdown {"Process": "storagenode", "name": "server"}
2025-05-22T23:20:09-07:00 WARN services service takes long to shutdown {"Process": "storagenode", "name": "gracefulexit:chore"}
2025-05-22T23:20:12-07:00 INFO services slow shutdown {"Process": "storagenode", "stack": "goroutine 1614\n\tstorj.io/storj/private/lifecycle.(*Group).logStackTrace.func1:107\n\tsync.(*Once).doSlow:78\n\tsync.(*Once).Do:69\n\tstorj.io/storj/private/lifecycle.(*Group).logStackTrace:104\n\tstorj.io/storj ** remainder of massive line removed
2025-05-22T23:20:14-07:00 INFO servers slow shutdown {"Process": "storagenode", "stack": "goroutine 1550\n\tstorj.io/storj/private/lifecycle.(*Group).logStackTrace.func1:107\n\tsync.(*Once).doSlow:78\n\tsync.(*Once).Do:69\n\tstorj.io/storj/private/lifecycle.(*Group).logStackTrace:104\n\tstorj.io/storj/private ** remainder of massive line removed
2025-05-22T23:20:23-07:00 ERROR gracefulexit:chore error retrieving satellites. {"Process": "storagenode", "error": "satellitesdb: context canceled", "errorVerbose": "satellitesdb: context canceled\n\tstorj.io/storj/storagenode/storagenodedb.(*satellitesDB).ListGracefulExits.func1:201\n\tstorj.io/storj/storagenode/storagenodedb.(*satellitesDB).ListGracefulExits:213\n\tstorj.io/storj/storagenode/gracefulexit.(*Service).ListPendingExits:59\n\tstorj.io/storj/storagenode/gracefulexit.(*Chore).AddMissing:55\n\tstorj.io/common/sync2.(*Cycle).Run:163\n\tstorj.io/storj/storagenode/gracefulexit.(*Chore).Run:48\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2.1:87\n\truntime/pprof.Do:51\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2:86\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:78"}
2025-05-22T23:20:54-07:00 ERROR failure during run {"Process": "storagenode", "error": "piecestore monitor: timed out after 1m0s while verifying writability of storage directory", "errorVerbose": "piecestore monitor: timed out after 1m0s while verifying writability of storage directory\n\tstorj.io/storj/storagenode/monitor.(*Service).verifyWritability:184\n\tstorj.io/common/sync2.(*Cycle).Run:163\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func2:114\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:78"}
2025-05-22T23:20:54-07:00 FATAL Unrecoverable error {"Process": "storagenode", "error": "piecestore monitor: timed out after 1m0s while verifying writability of storage directory", "errorVerbose": "piecestore monitor: timed out after 1m0s while verifying writability of storage directory\n\tstorj.io/storj/storagenode/monitor.(*Service).verifyWritability:184\n\tstorj.io/common/sync2.(*Cycle).Run:163\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func2:114\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:78"}
At this point, it looks like the node automatically restarted, based on log messages:
2025-05-22T23:22:21-07:00 INFO Configuration loaded {"Process": "storagenode", "Location": "/mnt/storagenode/data/config.yaml"}
2025-05-22T23:22:21-07:00 INFO Anonymized tracing enabled {"Process": "storagenode"}
2025-05-22T23:22:22-07:00 INFO Operator email {"Process": "storagenode", "Address": "you.don't.need.to.know"}
2025-05-22T23:22:22-07:00 INFO Operator wallet {"Process": "storagenode", "Address": "0x................................"}
2025-05-22T23:22:42-07:00 INFO server existing kernel support for server-side tcp fast open detected {"Process": "storagenode"}
2025-05-22T23:22:44-07:00 INFO hashstore hashstore opened successfully {"Process": "storagenode", "satellite": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "open_time": "234.844547ms"}
2025-05-22T23:22:44-07:00 INFO hashstore hashstore opened successfully {"Process": "storagenode", "satellite": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "open_time": "49.344599ms"}
2025-05-22T23:22:48-07:00 INFO Telemetry enabled {"Process": "storagenode", "instance ID": "1R9kwKBqceNdCvY6sDmjNDvsDjsjPXnYkHM8P4qNZmYt4sQeMd"}
2025-05-22T23:22:48-07:00 INFO Event collection enabled {"Process": "storagenode", "instance ID": "1R9kwKBqceNdCvY6sDmjNDvsDjsjPXnYkHM8P4qNZmYt4sQeMd"}
2025-05-22T23:22:48-07:00 INFO db.migration Database Version {"Process": "storagenode", "version": 62}
2025-05-22T23:22:51-07:00 INFO preflight:localtime start checking local system clock with trusted satellites' system clock. {"Process": "storagenode"}
2025-05-22T23:22:51-07:00 INFO preflight:localtime local system clock is in sync with trusted satellites' system clock. {"Process": "storagenode"}
2025-05-22T23:22:51-07:00 INFO trust Scheduling next refresh {"Process": "storagenode", "after": "7h33m8.323930054s"}
2025-05-22T23:22:51-07:00 INFO Node 1R9kwKBqceNdCvY6sDmjNDvsDjsjPXnYkHM8P4qNZmYt4sQeMd started {"Process": "storagenode"}
2025-05-22T23:22:51-07:00 INFO Public server started on [::]:28967 {"Process": "storagenode"}
2025-05-22T23:22:51-07:00 INFO Private server started on 127.0.0.1:7778 {"Process": "storagenode"}
2025-05-22T23:22:51-07:00 INFO bandwidth Persisting bandwidth usage cache to db {"Process": "storagenode"}
2025-05-22T23:22:51-07:00 INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2025-05-22T23:22:51-07:00 INFO pieces:trash emptying trash finished {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "elapsed": "235.996µs"}
2025-05-22T23:22:51-07:00 INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE"}
2025-05-22T23:22:51-07:00 INFO pieces used-space-filewalker started {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S"}
2025-05-22T23:22:51-07:00 INFO piecemigrate:chore all enqueued for migration; will sleep before next pooling {"Process": "storagenode", "active": {}, "interval": "10m0s"}
2025-05-22T23:22:51-07:00 INFO pieces:trash emptying trash finished {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "elapsed": "56.441226ms"}
2025-05-22T23:22:51-07:00 INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2025-05-22T23:22:51-07:00 INFO pieces:trash emptying trash finished {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "elapsed": "119.254µs"}
2025-05-22T23:22:51-07:00 INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S"}
2025-05-22T23:22:51-07:00 INFO pieces:trash emptying trash finished {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "elapsed": "70.654µs"}
2025-05-22T23:23:10-07:00 INFO orders finished {"Process": "storagenode", "satelliteID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "count": 9}
2025-05-22T23:23:12-07:00 INFO orders finished {"Process": "storagenode", "satelliteID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "count": 1010}
2025-05-22T23:23:12-07:00 INFO orders finished {"Process": "storagenode", "satelliteID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "count": 1312}
2025-05-22T23:23:24-07:00 INFO orders finished {"Process": "storagenode", "satelliteID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "count": 53596}
2025-05-22T23:27:29-07:00 INFO reputation:service node scores updated {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "Total Audits": 5513, "Successful Audits": 5497, "Audit Score": 1, "Online Score": 0.9938142770719903, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": 0, "Suspension Score Delta": 0}
2025-05-22T23:27:29-07:00 INFO reputation:service node scores updated {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "Total Audits": 41470, "Successful Audits": 41407, "Audit Score": 1, "Online Score": 0.9988376844503829, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": 0, "Suspension Score Delta": 0}
2025-05-22T23:27:30-07:00 INFO reputation:service node scores updated {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Total Audits": 55688, "Successful Audits": 55642, "Audit Score": 1, "Online Score": 0.9995757646082547, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": 0, "Suspension Score Delta": 0}
2025-05-22T23:27:30-07:00 INFO reputation:service node scores updated {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Total Audits": 5832, "Successful Audits": 5820, "Audit Score": 1, "Online Score": 0.9985889479905438, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": 0, "Suspension Score Delta": 0}
2025-05-22T23:32:51-07:00 INFO piecemigrate:chore all enqueued for migration; will sleep before next pooling {"Process": "storagenode", "active": {}, "interval": "10m0s"}
2025-05-22T23:42:51-07:00 INFO piecemigrate:chore all enqueued for migration; will sleep before next pooling {"Process": "storagenode", "active": {}, "interval": "10m0s"}
2025-05-22T23:52:51-07:00 INFO piecemigrate:chore all enqueued for migration; will sleep before next pooling {"Process": "storagenode", "active": {}, "interval": "10m0s"}
2025-05-22T23:57:01-07:00 ERROR services unexpected shutdown of a runner {"Process": "storagenode", "name": "piecestore:monitor", "error": "piecestore monitor: timed out after 1m0s while verifying readability of storage directory", "errorVerbose": "piecestore monitor: timed out after 1m0s while verifying readability of storage directory\n\tstorj.io/storj/storagenode/monitor.(*Service).verifyStorageDir:157\n\tstorj.io/common/sync2.(*Cycle).Run:163\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func1:111\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:78"}
2025-05-22T23:57:11-07:00 ERROR filewalker failed to store the last batch of prefixes {"Process": "storagenode", "error": "filewalker: context canceled", "errorVerbose": "filewalker: context canceled\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkSatellitePieces:78\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatelliteWithWalkFunc:129\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatellite:83\n\tstorj.io/storj/storagenode/pieces.(*Store).WalkAndComputeSpaceUsedBySatellite:783\n\tstorj.io/storj/storagenode/pieces.(*CacheService).Run.func1:85\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:78"}
2025-05-22T23:57:11-07:00 ERROR pieces used-space-filewalker failed {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Lazy File Walker": false, "error": "filewalker: filewalker: context canceled; used_space_per_prefix_db: context canceled", "errorVerbose": "filewalker: filewalker: context canceled; used_space_per_prefix_db: context canceled\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatelliteWithWalkFunc:181\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatellite:83\n\tstorj.io/storj/storagenode/pieces.(*Store).WalkAndComputeSpaceUsedBySatellite:783\n\tstorj.io/storj/storagenode/pieces.(*CacheService).Run.func1:85\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:78"}
2025-05-22T23:57:11-07:00 ERROR piecestore:cache encountered error while computing space used by satellite {"Process": "storagenode", "error": "filewalker: filewalker: context canceled; used_space_per_prefix_db: context canceled", "errorVerbose": "filewalker: filewalker: context canceled; used_space_per_prefix_db: context canceled\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatelliteWithWalkFunc:181\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatellite:83\n\tstorj.io/storj/storagenode/pieces.(*Store).WalkAndComputeSpaceUsedBySatellite:783\n\tstorj.io/storj/storagenode/pieces.(*CacheService).Run.func1:85\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:78", "SatelliteID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S"}
2025-05-22T23:57:11-07:00 INFO pieces used-space-filewalker started {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2025-05-22T23:57:11-07:00 ERROR pieces used-space-filewalker failed {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Lazy File Walker": false, "error": "filewalker: used_space_per_prefix_db: context canceled", "errorVerbose": "filewalker: used_space_per_prefix_db: context canceled\n\tstorj.io/storj/storagenode/storagenodedb.(*usedSpacePerPrefixDB).Get:81\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatelliteWithWalkFunc:96\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatellite:83\n\tstorj.io/storj/storagenode/pieces.(*Store).WalkAndComputeSpaceUsedBySatellite:783\n\tstorj.io/storj/storagenode/pieces.(*CacheService).Run.func1:85\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:78"}
2025-05-22T23:57:11-07:00 ERROR piecestore:cache encountered error while computing space used by satellite {"Process": "storagenode", "error": "filewalker: used_space_per_prefix_db: context canceled", "errorVerbose": "filewalker: used_space_per_prefix_db: context canceled\n\tstorj.io/storj/storagenode/storagenodedb.(*usedSpacePerPrefixDB).Get:81\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatelliteWithWalkFunc:96\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatellite:83\n\tstorj.io/storj/storagenode/pieces.(*Store).WalkAndComputeSpaceUsedBySatellite:783\n\tstorj.io/storj/storagenode/pieces.(*CacheService).Run.func1:85\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:78", "SatelliteID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2025-05-22T23:57:11-07:00 INFO pieces used-space-filewalker started {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2025-05-22T23:57:11-07:00 ERROR pieces used-space-filewalker failed {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "Lazy File Walker": false, "error": "filewalker: used_space_per_prefix_db: context canceled", "errorVerbose": "filewalker: used_space_per_prefix_db: context canceled\n\tstorj.io/storj/storagenode/storagenodedb.(*usedSpacePerPrefixDB).Get:81\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatelliteWithWalkFunc:96\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatellite:83\n\tstorj.io/storj/storagenode/pieces.(*Store).WalkAndComputeSpaceUsedBySatellite:783\n\tstorj.io/storj/storagenode/pieces.(*CacheService).Run.func1:85\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:78"}
2025-05-22T23:57:11-07:00 ERROR piecestore:cache encountered error while computing space used by satellite {"Process": "storagenode", "error": "filewalker: used_space_per_prefix_db: context canceled", "errorVerbose": "filewalker: used_space_per_prefix_db: context canceled\n\tstorj.io/storj/storagenode/storagenodedb.(*usedSpacePerPrefixDB).Get:81\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatelliteWithWalkFunc:96\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatellite:83\n\tstorj.io/storj/storagenode/pieces.(*Store).WalkAndComputeSpaceUsedBySatellite:783\n\tstorj.io/storj/storagenode/pieces.(*CacheService).Run.func1:85\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:78", "SatelliteID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2025-05-22T23:57:11-07:00 INFO pieces used-space-filewalker started {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE"}
2025-05-22T23:57:11-07:00 ERROR pieces used-space-filewalker failed {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "Lazy File Walker": false, "error": "filewalker: used_space_per_prefix_db: context canceled", "errorVerbose": "filewalker: used_space_per_prefix_db: context canceled\n\tstorj.io/storj/storagenode/storagenodedb.(*usedSpacePerPrefixDB).Get:81\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatelliteWithWalkFunc:96\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatellite:83\n\tstorj.io/storj/storagenode/pieces.(*Store).WalkAndComputeSpaceUsedBySatellite:783\n\tstorj.io/storj/storagenode/pieces.(*CacheService).Run.func1:85\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:78"}
2025-05-22T23:57:11-07:00 ERROR piecestore:cache encountered error while computing space used by satellite {"Process": "storagenode", "error": "filewalker: used_space_per_prefix_db: context canceled", "errorVerbose": "filewalker: used_space_per_prefix_db: context canceled\n\tstorj.io/storj/storagenode/storagenodedb.(*usedSpacePerPrefixDB).Get:81\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatelliteWithWalkFunc:96\n\tstorj.io/storj/storagenode/pieces.(*FileWalker).WalkAndComputeSpaceUsedBySatellite:83\n\tstorj.io/storj/storagenode/pieces.(*Store).WalkAndComputeSpaceUsedBySatellite:783\n\tstorj.io/storj/storagenode/pieces.(*CacheService).Run.func1:85\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:78", "SatelliteID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE"}
2025-05-22T23:57:11-07:00 ERROR piecestore:cache error getting current used space for trash: {"Process": "storagenode", "error": "filestore error: failed to walk trash namespace af2c42003efc826ab4361f73f9d890942146fe0ebe806786f8e7190800000000: context canceled", "errorVerbose": "filestore error: failed to walk trash namespace af2c42003efc826ab4361f73f9d890942146fe0ebe806786f8e7190800000000: context canceled\n\tstorj.io/storj/storagenode/blobstore/filestore.(*blobStore).SpaceUsedForTrash:302\n\tstorj.io/storj/storagenode/pieces.(*CacheService).Run.func1:104\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:78"}
2025-05-22T23:57:12-07:00 ERROR failure during run {"Process": "storagenode", "error": "piecestore monitor: timed out after 1m0s while verifying readability of storage directory", "errorVerbose": "piecestore monitor: timed out after 1m0s while verifying readability of storage directory\n\tstorj.io/storj/storagenode/monitor.(*Service).verifyStorageDir:157\n\tstorj.io/common/sync2.(*Cycle).Run:163\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func1:111\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:78"}
2025-05-22T23:57:12-07:00 FATAL Unrecoverable error {"Process": "storagenode", "error": "piecestore monitor: timed out after 1m0s while verifying readability of storage directory", "errorVerbose": "piecestore monitor: timed out after 1m0s while verifying readability of storage directory\n\tstorj.io/storj/storagenode/monitor.(*Service).verifyStorageDir:157\n\tstorj.io/common/sync2.(*Cycle).Run:163\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func1:111\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:78"}
Again, it appears the node restarted itself, but this time there were no more errors thrown:
2025-05-22T23:57:16-07:00 INFO Configuration loaded {"Process": "storagenode", "Location": "/mnt/storagenode/data/config.yaml"}
2025-05-22T23:57:16-07:00 INFO Anonymized tracing enabled {"Process": "storagenode"}
2025-05-22T23:57:16-07:00 INFO Operator email {"Process": "storagenode", "Address": "you.don't.need.to.know"}
2025-05-22T23:57:16-07:00 INFO Operator wallet {"Process": "storagenode", "Address": "0x................................"}
2025-05-22T23:57:19-07:00 INFO server existing kernel support for server-side tcp fast open detected {"Process": "storagenode"}
2025-05-22T23:57:20-07:00 INFO hashstore hashstore opened successfully {"Process": "storagenode", "satellite": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "open_time": "115.352969ms"}
2025-05-22T23:57:20-07:00 INFO hashstore hashstore opened successfully {"Process": "storagenode", "satellite": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "open_time": "54.173687ms"}
2025-05-22T23:57:21-07:00 INFO Telemetry enabled {"Process": "storagenode", "instance ID": "1R9kwKBqceNdCvY6sDmjNDvsDjsjPXnYkHM8P4qNZmYt4sQeMd"}
2025-05-22T23:57:21-07:00 INFO Event collection enabled {"Process": "storagenode", "instance ID": "1R9kwKBqceNdCvY6sDmjNDvsDjsjPXnYkHM8P4qNZmYt4sQeMd"}
2025-05-22T23:57:21-07:00 INFO db.migration Database Version {"Process": "storagenode", "version": 62}
2025-05-22T23:57:22-07:00 INFO preflight:localtime start checking local system clock with trusted satellites' system clock. {"Process": "storagenode"}
2025-05-22T23:57:22-07:00 INFO preflight:localtime local system clock is in sync with trusted satellites' system clock. {"Process": "storagenode"}
2025-05-22T23:57:22-07:00 INFO trust Scheduling next refresh {"Process": "storagenode", "after": "6h47m26.34787941s"}
2025-05-22T23:57:22-07:00 INFO Node 1R9kwKBqceNdCvY6sDmjNDvsDjsjPXnYkHM8P4qNZmYt4sQeMd started {"Process": "storagenode"}
2025-05-22T23:57:22-07:00 INFO Public server started on [::]:28967 {"Process": "storagenode"}
2025-05-22T23:57:22-07:00 INFO Private server started on 127.0.0.1:7778 {"Process": "storagenode"}
2025-05-22T23:57:22-07:00 INFO bandwidth Persisting bandwidth usage cache to db {"Process": "storagenode"}
2025-05-22T23:57:22-07:00 INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2025-05-22T23:57:22-07:00 INFO pieces used-space-filewalker started {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S"}
2025-05-22T23:57:22-07:00 INFO piecemigrate:chore all enqueued for migration; will sleep before next pooling {"Process": "storagenode", "active": {}, "interval": "10m0s"}
2025-05-22T23:57:22-07:00 INFO pieces:trash emptying trash finished {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "elapsed": "26.84673ms"}
2025-05-22T23:57:22-07:00 INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2025-05-22T23:57:22-07:00 INFO pieces:trash emptying trash finished {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "elapsed": "156.963µs"}
2025-05-22T23:57:22-07:00 INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE"}
2025-05-22T23:57:22-07:00 INFO pieces:trash emptying trash finished {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "elapsed": "57.282µs"}
2025-05-22T23:57:22-07:00 INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S"}
2025-05-22T23:57:22-07:00 INFO pieces:trash emptying trash finished {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "elapsed": "68.309µs"}
2025-05-23T00:00:48-07:00 INFO reputation:service node scores updated {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "Total Audits": 5513, "Successful Audits": 5497, "Audit Score": 1, "Online Score": 0.9938142770719903, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": 0, "Suspension Score Delta": 0}
2025-05-23T00:00:49-07:00 INFO reputation:service node scores updated {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "Total Audits": 41470, "Successful Audits": 41407, "Audit Score": 1, "Online Score": 0.9988376844503829, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": 0, "Suspension Score Delta": 0}
2025-05-23T00:00:49-07:00 INFO reputation:service node scores updated {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Total Audits": 55787, "Successful Audits": 55736, "Audit Score": 1, "Online Score": 0.9995757646082547, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": 0, "Suspension Score Delta": 0}
2025-05-23T00:00:49-07:00 INFO reputation:service node scores updated {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Total Audits": 5840, "Successful Audits": 5828, "Audit Score": 1, "Online Score": 0.9985889479905438, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": 0, "Suspension Score Delta": 0}
2025-05-23T00:07:22-07:00 INFO piecemigrate:chore all enqueued for migration; will sleep before next pooling {"Process": "storagenode", "active": {}, "interval": "10m0s"}
2025-05-23T00:15:03-07:00 INFO pieces used-space-filewalker completed {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Lazy File Walker": false, "Total Pieces Size": 3864819676762, "Total Pieces Content Size": 3857872854618, "Total Pieces Count": 13568012, "Duration": "17m41.12852924s"}
2025-05-23T00:15:03-07:00 INFO pieces used-space-filewalker started {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2025-05-23T00:17:22-07:00 INFO piecemigrate:chore all enqueued for migration; will sleep before next pooling {"Process": "storagenode", "active": {}, "interval": "10m0s"}
2025-05-23T00:18:31-07:00 INFO pieces used-space-filewalker completed {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Lazy File Walker": false, "Total Pieces Size": 76142548992, "Total Pieces Content Size": 76046517248, "Total Pieces Count": 187562, "Duration": "3m27.191898822s"}
2025-05-23T00:18:31-07:00 INFO pieces used-space-filewalker started {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2025-05-23T00:23:21-07:00 INFO pieces used-space-filewalker completed {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "Lazy File Walker": false, "Total Pieces Size": 225347145472, "Total Pieces Content Size": 224998125824, "Total Pieces Count": 681679, "Duration": "4m50.210442834s"}
2025-05-23T00:23:21-07:00 INFO pieces used-space-filewalker started {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE"}
2025-05-23T00:24:12-07:00 INFO pieces used-space-filewalker completed {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "Lazy File Walker": false, "Total Pieces Size": 1853449216, "Total Pieces Content Size": 1844134912, "Total Pieces Count": 18192, "Duration": "50.825243664s"}
Is there anything else I need to do at this point, or was everything cleaned up correctly.
Cheers.