I had a small “online” problem when my dog chewed the RJ45 cable. Turns out it’s not good for the connection… now I have 2 cables running to my node, and one of them is inside the wall… my dog can chew the wall, but it will take her more time…
Anyway, the offline status lasted for 20 min, or so…
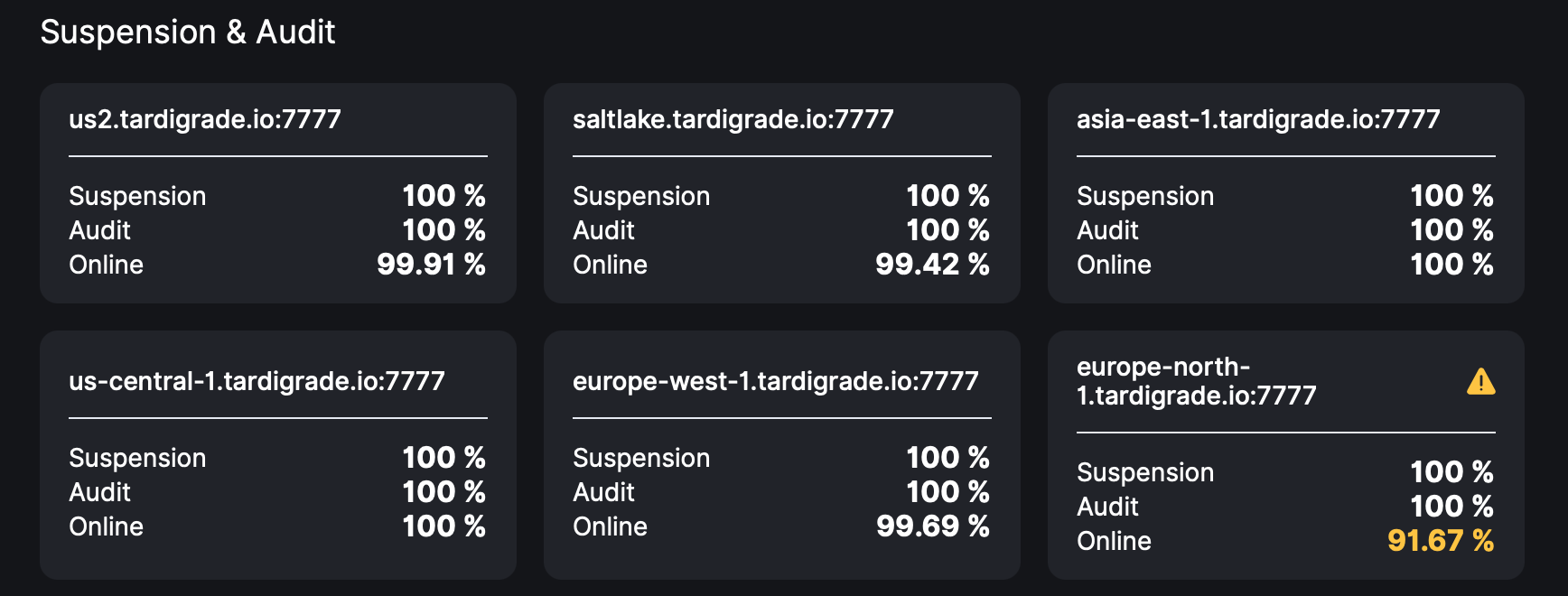
us-central has been uploading more than 20GB per day to my node and doesn’t think I’ve been offline… west europe and us2 may have got it about right…
But europe-north went crazy… what can/should I do besides keeping the node online?
The online score is only affected when you get audits, so in the 20 minutes of downtime, you probably happened to get one or more audit requests from Europe North
ok. So, it’s a statistical “bad luck” with europe-north satellite…
But still, us2 has been constantly uploading to my node. For sure it couldn’t miss the connection going down. You mean, since it was not doing an audit, just uploading, it didn’t count as offline period?
Yes, it should, if you did not have a downtime (even short) again - the window is moved on, but a previous drop still in it and your node now added a little more, thus the average is dropped more. Every downtime will reset the count for the next 30 days online.
The network will rebalance itself. If there would be low usage, we will see greater nodes churn, especially from newbie who do not patient enough (the node would come to the high league only after 9 months in the network).
If demand will increase, Operators would add more nodes.
I’m having the same experience with europe-north too.
Had some downtime a few weeks ago so the online score dropped (to 85% or something) and the following days it rose slowly to 91-92%. Then it fell to 90%, then back up around 1% and down 1% and it’s been doing that ever since, although I’ve not had another downtime.
All and the other sats show >95% online, uptimerobot shows 98.5%.
The Europe-North-1 has not a lot of data, so audits are rare than from other satellites, so the online score is more sensitive than on the satellites with more data.