Guten Abend,
meine onlineprozent im Dashboard fallen bei 2 Satelliten.
Habe beide Skripte laufen lassen für genauere Infos die ausgaben sind folgende:
earning-skript
September 2021 (Version: 10.2.1) [snapshot: 2021-09-11 17:29:36Z]
TYPE PRICE DISK BANDWIDTH PAYOUT
Upload Ingress -not paid- 81.44 GB
Upload Repair Ingress -not paid- 51.71 GB
Download Egress $ 20.00 / TB 51.35 GB $ 1.03
Download Repair Egress $ 10.00 / TB 315.23 MB $ 0.00
Download Audit Egress $ 10.00 / TB 111.36 KB $ 0.00
Disk Current Storage -not paid- 494.65 GB
Disk Average Month Storage $ 1.50 / TBm 150.62 GBm $ 0.23
Disk Usage Storage -not paid- 108.44 TBh
________________________________________________________________________________________________________+
Total 150.62 GBm 184.82 GB $ 1.26
Estimated total by end of month 421.15 GBm 516.79 GB $ 3.51
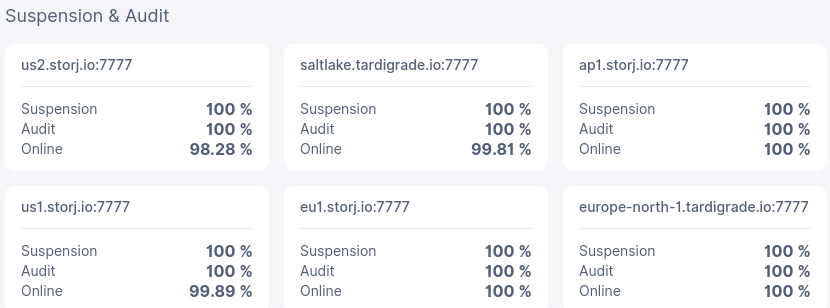
Payout and held amount by satellite:
NODE AGE HELD AMOUNT REPUTATION PAYOUT THIS MONTH
SATELLITE Joined Month Perc Total Disq Susp Down Earned Held Payout
us1.storj.io | 2021-05-30 5 | 50% $ 1.64 | 0.00% 0.00% 0.11% | $ 0.6079 $ 0.3040 $ 0.3040
Status: OK
us2.storj.io | 2021-05-30 5 | 50% $ 0.00 | 0.00% 0.00% 0.00% | $ 0.0024 $ 0.0012 $ 0.0012
Status: OK
eu1.storj.io | 2021-05-30 5 | 50% $ 0.13 | 0.00% 0.00% 0.00% | $ 0.1267 $ 0.0634 $ 0.0634
Status: OK
ap1.storj.io | 2021-05-30 5 | 50% $ 0.01 | 0.00% 0.00% 0.00% | $ 0.0048 $ 0.0024 $ 0.0024
Status: OK
europe-north-1 | 2021-05-30 5 | 50% $ 0.01 | 0.00% 0.00% 0.00% | $ 0.0044 $ 0.0022 $ 0.0022
Status: 79% Vetting progress (38 / 100 Audits)
saltlake | 2021-05-30 5 | 50% $ 1.33 | 0.00% 0.00% 0.19% | $ 0.5098 $ 0.2549 $ 0.2549
Status: OK
_____________________________________________________________________________________________________________________+
TOTAL $ 3.13 $ 1.2561 $ 0.6280 $ 0.6280
POSTPONED PAYOUT PREVIOUS MONTHS $ 2.0358
audit
========== AUDIT ==============
Critically failed: 0
Critical Fail Rate: 0.000%
Recoverable failed: 0
Recoverable Fail Rate: 0.000%
Successful: 15
Success Rate: 100.000%
========== DOWNLOAD ===========
Failed: 136
Fail Rate: 3.697%
Canceled: 9
Cancel Rate: 0.245%
Successful: 3534
Success Rate: 96.059%
========== UPLOAD =============
Rejected: 0
Acceptance Rate: 100.000%
---------- accepted -----------
Failed: 7
Fail Rate: 0.012%
Canceled: 33
Cancel Rate: 0.055%
Successful: 59531
Success Rate: 99.933%
========== REPAIR DOWNLOAD ====
Failed: 0
Fail Rate: 0.000%
Canceled: 0
Cancel Rate: 0.000%
Successful: 7
Success Rate: 100.000%
========== REPAIR UPLOAD ======
Failed: 0
Fail Rate: 0.000%
Canceled: 0
Cancel Rate: 0.000%
Successful: 1734
Success Rate: 100.000%
========== DELETE =============
Failed: 0
Fail Rate: 0.000%
Successful: 7628
Success Rate: 100.000%
Hier kann ich ja sehen, dass die Audits immer gepasst haben oder verstehe ich hier was falsch?
Alexey
September 11, 2021, 5:51pm
2
Guten Abend,
Überprüfen Sie das Protokoll auf Verbindungsfehler von Satelliten (“ping satellite failed”).
Mit den folgenden Skripten können Sie sehen, wann Ihr Knoten nicht verfügbar war:
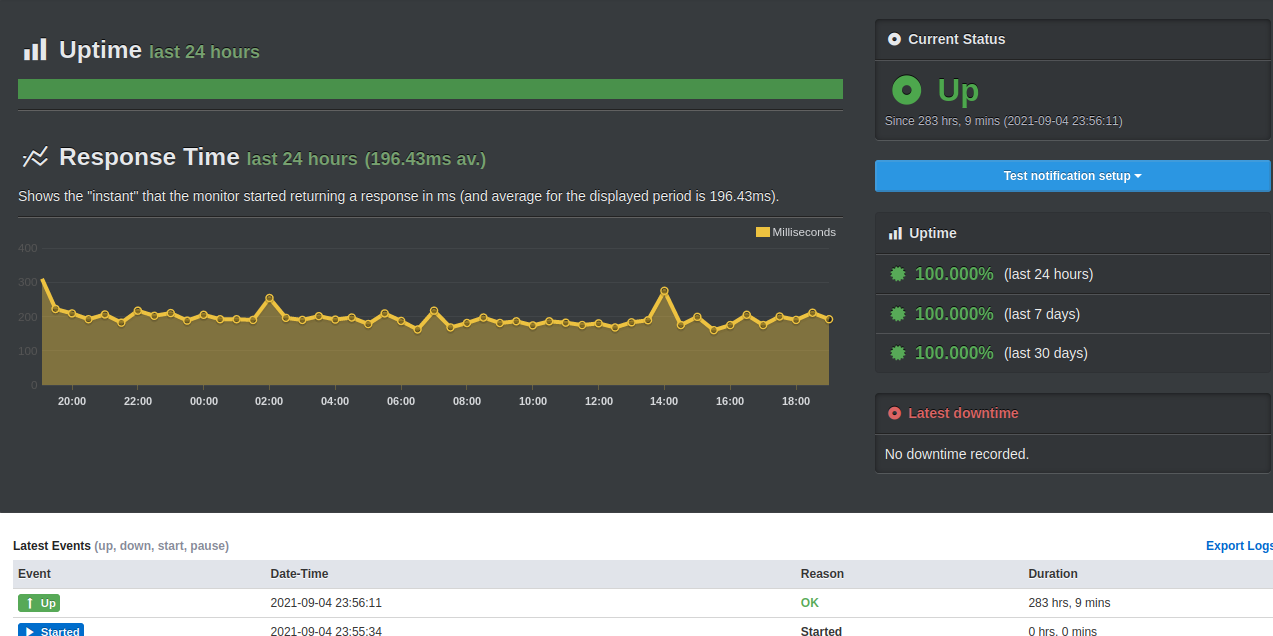
Would you mind to provide dashboard from the uptimerobot?
And also, please, provide result of the command:
Danke für die schnelle Antwort, es wurde bei der Firewall seit Inbetriebnahme nichts umgestellt.
output from your script
./check-online-score.sh
{
"id": "12tRQrMTWUWwzwGh18i7Fqs67kmdhH9t6aToeiwbo5mfS2rUmo",
"auditHistory": []
}
{
"id": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE",
"auditHistory": [
{
"windowStart": "2021-08-30T00:00:00Z",
"totalCount": 9,
"onlineCount": 8
}
]
}
{
"id": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6",
"auditHistory": []
}
{
"id": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S",
"auditHistory": [
{
"windowStart": "2021-09-09T00:00:00Z",
"totalCount": 15,
"onlineCount": 14
}
]
}
{
"id": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs",
"auditHistory": []
}
{
"id": "12rfG3sh9NCWiX3ivPjq2HtdLmbqCrvHVEzJubnzFzosMuawymB",
"auditHistory": []
}
output from faild audits
`docker logs storj 2>&1 | grep GET_AUDIT | grep failed | grep open -c
0`
Count of recoverable failed audits
docker logs storj 2>&1 | grep GET_AUDIT | grep failed | grep -v open -c 0
Alexey
September 11, 2021, 6:42pm
4
Ihr Knoten hat eine Prüfung von jedem der betroffenen Satelliten verpasst. Da der Online-Score über 30-Tage-Fenster berechnet wird, ist die Änderung gering.How is the online score calculated? - Node Operator
Verpasste Audits != Fehlgeschlagene Audits.
Danke für die Antwort, ich werde es nun die nächsten 30 Tage weiter beobachten, ob die % noch weiter nach unten gehen.
Heute in der früh, sah ich wie jeden Tag auf mein Dashboard und musste feststellen, dass der nächste onlinescore gefallen ist.
Habe extre den Uptimerobot nochmal neu angelegt kein einziger Ausfall:
Danke für die Antwort die Ausgabe ist folgende:
{
"id": "12tRQrMTWUWwzwGh18i7Fqs67kmdhH9t6aToeiwbo5mfS2rUmo",
"auditHistory": [
{
"windowStart": "2021-09-15T00:00:00Z",
"totalCount": 1,
"onlineCount": 0
}
]
}
{
"id": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE",
"auditHistory": [
{
"windowStart": "2021-08-30T00:00:00Z",
"totalCount": 9,
"onlineCount": 8
}
]
}
{
"id": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6",
"auditHistory": []
}
{
"id": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S",
"auditHistory": [
{
"windowStart": "2021-09-09T00:00:00Z",
"totalCount": 15,
"onlineCount": 14
}
]
}
{
"id": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs",
"auditHistory": []
}
{
"id": "12rfG3sh9NCWiX3ivPjq2HtdLmbqCrvHVEzJubnzFzosMuawymB",
"auditHistory": []
}
Alexey
September 17, 2021, 3:56am
9
gerne geschehen!
wie meinst du zu beschädigt?
Die Firewall wurde komplett deaktiviert weiß nicht wo ich weiter machen soll bei der Fehlersuche.
Alexey
September 17, 2021, 4:33am
11
Manchmal hängt der Knotendienst aufgrund von Hardwareproblemen teilweise auf – antwortet nicht auf Anfragen oder antwortet immer noch, liefert aber nicht die angeforderten Informationen.
Betrieben wird alles auf einer Synology DS920+. Man sieht keine erhöten Ressourcenbelastung. Festplatte ist eine: Seagate 4 TB IronWolf 3,5 Zoll interne Festplatte für 1-8 Bay NAS-Systeme (5900 U/min, 64 MB Cache, 180 TB/Jahr Arbeitslast, bis zu 180 MB/s), Silbe verbaut.
Alexey
September 17, 2021, 5:59am
13
Hauptsache, es ist kein SMR.
Recently there have been several reports of SNOs running into massive CPU wait issues. It seems the common thread has been the use of HDD’s in which manufacturers have quietly started using SMR technology.
[2003549104]
Because of these overlapping tracks, when data is written to the disk, the drive has to rewrite several additional tracks. This obviously leads to much slower writes. These HDD’s usually deal with that using large caches and rewriting the shingles tracks during quiet times. How…
Bisher ist die Zahl unbeantworteter Audits gering. Hoffen wir, dass ihre Zahl nicht wächst.
Ich würde vorschlagen, auf Englisch zu fragen, vielleicht können Ihnen andere Synology-Besitzer helfen.
Danke dann werde ich mal auf Englisch nachfragen, falls es noch schlimmer wird.