I’ve been tracking my disk usage for some time, and have just recently noticed that one of my nodes is currently at 122.8% disk usage, which equates to being overused by 2.28TB!
Now I can understand some MB, or even a few 10s of GBs, but 2.28TB is quite excessive, and has filled up the buffer I have on the node so it never gets 100% full.
I haven’t changed my configuration for quite some time, and it’s always been 10TB max allocation, but this is a first for me. Some quick browsing reveals that small amounts are fine, but 2.28TB is quite the “over-use”. Not only is it taking up more disk than I’d like, I’m not even sure if I’m getting paid for that disk usage.
Thoughts on where I can find this and prevent this from ever happening again?
My disks are 14TB disks, formatting, resulting in 12.7TB free.
user@raspberrypi:~ $ df
Filesystem 1K-blocks Used Available Use% Mounted on
...
/dev/sdb1 13563485152 12462425408 417424340 97% /mnt/csrpistorj1
and
user@raspberrypi:~ $ df -h
Filesystem Size Used Avail Use% Mounted on
...
/dev/sdb1 13T 12T 399G 97% /mnt/csrpistorj1
12462425408/1024/1024/1024 = 11.6TB, so it’s not 1:1, but I’m not sure what that has to do with the overused disk. Regardless, whether the OS is seeing 10TB, or the storj application is seeing 10TB, it should halt and future ingress.
You need to use --si instead of -h if you want to compare with the dashboard. The Storj software uses SI measure units (as a disk manufacturers), not binary.
12462425408 = 12.46TB
So, looks like the dashboard shows the used space pretty close to what’s reported by the OS. The average used space, if you would peek the last fully reported day likely has something about 7TB of the confirmed used space. So, the difference is about 5.46TB of uncollected garbage (see When will "Uncollected Garbage" be deleted?).
The overused itself is happened likely when you reduced the allocation to 10TB instead of previous likely 12TB, am I correct?
If not, and you are always have had the 10TB as allocated, then I guess that used space reported by the node was way off until the node is restarted and the used-space-filewalker has been calculated the used space and updated the databases, so now the node is aware that it has an overused disk space.
When the database is not matching the actual usage on the disk, the node wouldn’t report to the satellites that it’s full. Thus it can accept traffic and store more than was allocated.
We have a precaution mechanism though - when the node detect that it has less than 5GB on the disk or in the allocation, it will notify the satellites that it’s full and all ingress would stop independently of the databases state.
The only way to correct the databases state is let it finish the used-space-filewalker. It’s started on every restart.
Hi @Alexey , so the command doesn’t really show much different (Since it’s still a “human-readable” format):
user@raspberrypi:~ $ df --si
Filesystem Size Used Avail Use% Mounted on
..
/dev/sdb1 14T 13T 563G 96% /mnt/csrpistorj1
As for the allocation of my node, I never reduced it. It’s always been 10TB, similar to my other node in a similar setup. (They literally share the same config, except for ports and ddns entry.)
Regarding the used-space-filewalker, I’m guessing it’ll take a while, but I’m surprised that the dashboard is reporting the over-used space… isn’t that pulling from the database? If that’s the case, then the database is already up-to-date.
Yes, it is. What I’m tried to say: some time ago the databases were not updated with the actual usage and node reported to the satellites, that it’s still has a free space in the allocation, where it’s not. And when the node was restarted some time ago, the used-space-filewalker is successfully calculated the actual used space and updated the databases. And now it shows the overusage, which was not visible to the node before that.
I’m using this thread as it appear to be exactly the same story as mine.
I believe I’m in the exact same situation. I started with a large allocated drive size and then later, much later, I reduced the size, but Storj Node thinks nothing has changed. I have the capacity right now but maybe not in the future. I started with 3TB allocated, then dropped it down to 1TB. Months pass… Not dropping, still at 2.2TB capacity (1.3TB Overused).
Is there a way to handle this kind of problem once it has happened?
Thanks
EDIT: I changed the capacity as this node is on NVMe and I’m planning to migrate it to a 1TB SSD as I have several of those not being used.
It sounds like it is aiming for 1TB allocated. Are you saying it doesn’t look like you actually have 2.2TB used (or close) when you look at the filesystem?
Reducing the allocation only means it will reject new data: and allow the old data to be deleted if the customer chooses. So it may take a long time to naturally shrink.
If you don’t want to just turn it off, you can graceful-exit and get your withheld coins back. But if you have the time you should see it slowly get smaller: most customers don’t pay to hold their data forever
(P.S. I’ll trade you a 1TB node for your 2.2TB node if you want )
I have not looked at the actual used capacity but I have no reason to doubt it.
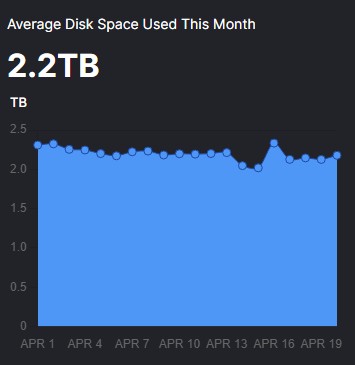
Here is a screen capture, notice the storage dips and then goes back up. I started April out with 2.31TB and I am down to 2.1TB but it goes up a little, it goes down a little.
My 2.2TB node sits on five 4TB NVMe drives. Those cost a bit more these days.
As we can see the “new” storj is much more short living but there is still some data for long term storage uploaded. Reducing used space to 50% by just stopping uploads would likely take years for this node.
While it is true that I did not buy it for storj, it also is not old used hardware, however since running the storj node it has been running, running very well, but I noticed my Percent Used on the NVMe drives appears to be dropping. I don’t think it is only due to storj node, but I know it is impacting the drives some. And since the storage price surge, I’d rather just ease up in the allocated drive space.
Are these true statements?
The reduction in the capacity being lowered to 1TB, will shrink over time as data is removed.
The node should not be recording new data since I’m over the allocated space.
If this is correct then I’m okay letting the data stay. And I was not doing the storj node for the big money I could make. I was hoping it would offset the cost of e storing my data on StorJ as a customer, yea, don’t laugh. I have a second node using two 6TB drives mirrored. I have just over 1TB of storj data, and i hope the drives fill up someday soon but it is extremely slow, looks stagnant. Eh, no biggie.
You mean increasing? You are worried that storj is wearing out your SSD?
Few comments about it:
I would strongly suggest checking sector size and ashift/whetever your fielesytem correposning records size is, and ensuring it’s 4k or larger, and if you use partitions, they are not crossing the 4k boundaries, i.e. aligned properly. Because if you notice wear from storj - you are likely have some crazy write amplification going on.
If you have idle SSD capacity, the best financial move is to sell the unoccupied SSD. There is no reason to keep it powered if you don’t need to. If it’s’ already part of the array and you can’t remove it – then fair.
I have never managed to wear out an SSD in my whole life. I have one very old one – consumer grade 120GB Intel, that shows 0 life remaining for about 7 years now, and I keep abusing it. No bad sectors, everything works. Enterprise disks – forget it. They will become obsolete way way before they even begin approaching exhaustion.
The true statement here is that it will definitely stop growing, and maybe shrink a little, if the files, pieces of which you happen to store, happen to get eventually deleted by the customer. Not guaranteed at all.
The best approach, if you want to get that storage back at some point, is to launch several nodes, so you can nuke them one by one to reclaim the space. Instead of one large node that cannot be shrunk for all intents and purposes.
Also maybe. if data will keep being deleted, the hashstore compaction will still be rewriting the logs. You will still get writes heading to disks.
I’m not going to laugh, I’ll just point out that we as a society have already invented money, to avoid the need to barter – so you can use that money to offer literally anythign else, like a cup of coffee and a croissant on the first Monday of the month, if you are into that sort of things :), does not have to be storage. I know a couple of folks who bought enough AT&T stock, so that dividends pay for their AT&T wireless service. Possible, by why connect independent transactions?..
But this is the correct approach – let it run, offset the cost of keeping the server online. Anecdotally, provided that I keep money in the mattress, I mean dont’ trust banks, sorry, insert old man screaming at the cloud meme, manage my data myself – three self-sufficient servers self-replicating snapshots to each outher is my way to not dealing with incompetence of storage providers – and storj helps make this less expensive.
I’m quite aware of these things and my partitions are properly lined up, but that is a great point to bring up. A lot of people are just not aware that this is a problem.
I have a few of those as well. The 1TB SSD I want to relocate the node to, that would be a good place for it.
I don’t have AT&T stocks but I do have stocks and they were averaging just over 15% annually, until Trumps war happened. But I have money if I need it. i am very happy to say the the stressing out for the pat 5+ years over “Will I have Enough Retirement” question was answered last month with a huge Yes.
But if I can save a few bucks and to help offset the storage cost of my own data, well I would want to do that.
I never thought about creating several small nodes, that is a good idea and I will have to think about it.
Well time to get back to script writing, maybe I’ll be productive tonight.
If you really want to clean up used space more aggressively, you can try a dangerous workaround: you can shut down your node for more than 12 hours or until you receive a suspension notification, and then bring it back online. After a week, garbage collection will remove some of the data from your node, as offline pieces have been restored to other online nodes.
Of course, due to the reputation impact, your egress will likely also be limited (your node will be chosen less often by clients and for downloads) until your reputation recovers (recovery requires 30 days online).
Thanks for the advice. I will keep it in mind and if the stored data size remains the same for a few more months, I will likely give that a try. I hope it starts to drop a bit before then but it is at least an alternative solution.
Interesting idea, thanks @Julio
I do have almost 3TB of unused space on that 6TB mirror.
Now time to look up how to migrate the data correctly. I’ve got some work ahead of me.