My node lost its iSCSI lun due to QNAP bug plaguing the latest rushed update due to the ransomware recently.
What’s the prognosis? Will it recover keeping it online? Or is the trust done? All it takes is 5 min? All data is still in tact, it just lost the LUN and sent the container into a continual reboot cycle for a few mins.
The storagenode has availability check of special file storage/storage-dir-verification and should crash if it’s not readable or doesn’t match the connected identity or storage/blobs is not writeable.
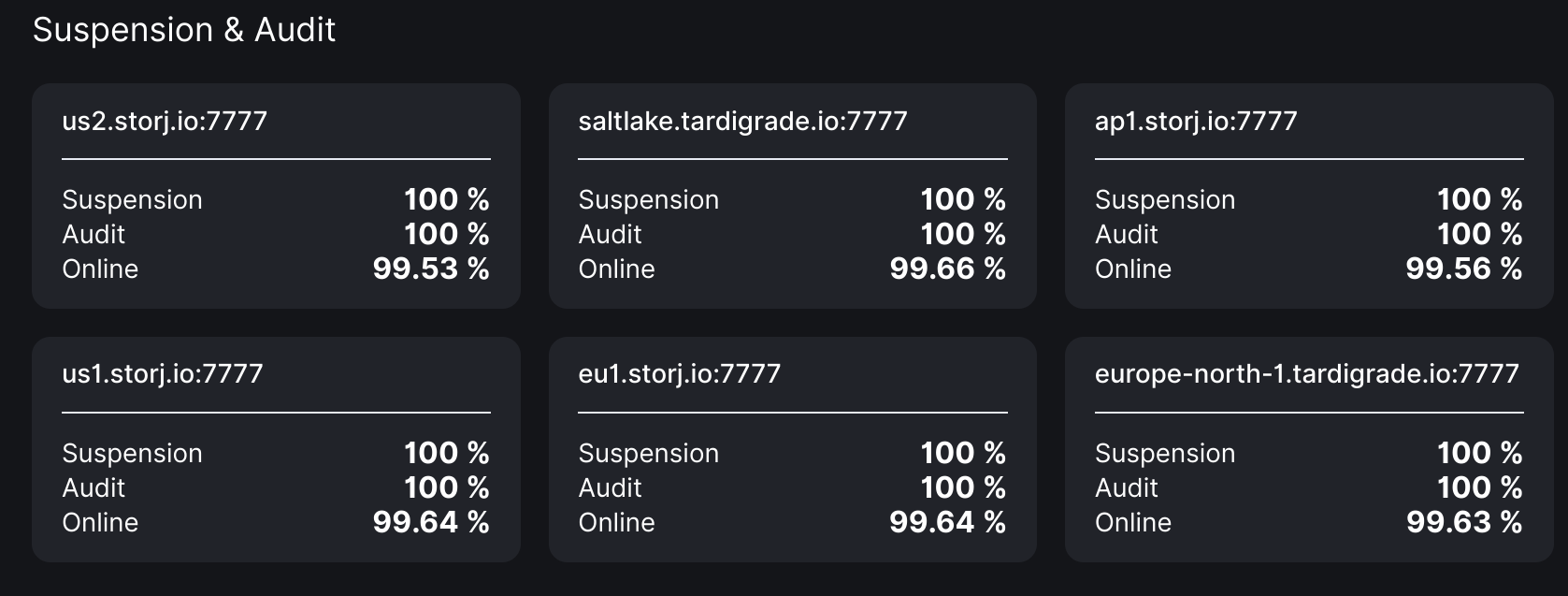
The low suspension score tells that it has had many unknown errors during audits. But your audit score is not yet affected. The suspension score will recover with each successful audit.
So, you just need to wait.
Do you know if there’s a limit on timeout for accessing the file? The container was constantly stopping, then restarting. I turned off the run command for “unless-stopped” for restart behavior to prevent this again.
It should stop if this happens in my case until i can take care of it.
The LUN may have actually been up at times, being EXTREMELY slow, and then disconnecting as well. I did a ls on the dir when i was bringing things down and it took a long time to populate.
The bug with QNAP was that you must specify the network interface that it uses, otherwise i think it starts round-robin’ing and disconnecting.
I would not recommend to use a network protocols for attaching storage at all
See also
PS > & 'C:\Program Files\Storj\Storage Node\storagenode.exe' setup --help | sls verify
--storage2.monitor.verify-dir-readable-interval duration how frequently to verify the location and readability of the storage directory (default 1m0s)
--storage2.monitor.verify-dir-writable-interval duration how frequently to verify writability of storage directory (default 5m0s)
i see it checks every 1m /5m respectively. This doesn’t explain how long it gives before the request fails. with high IO load for example, maybe it waits 1m before either error-ing, or restarting the attempt, meaning the intended result wouldn’t happen in this state.
maybe that’s what devDefault:“30s” does? I would expect it to be something like grace allowed, or expire, time allowed before error, etc,
I agree with no NAS, QNAP NAS anyway… They have already well exceeded my last straw.
TrueNAS scale is next on the list - i really want to secure my data. A single drive is too risky for me. It takes too long to get data back, and you may never see that legacy data again for years and years, if ever.
I mean not devices are not desirable, I mean the network protocols for attaching storage are not desirable, including iSCSI in your case, because your setup is clearly not reliable.
Corrected my response to be more clear.
There is no specific timeout, it depends on underlaying OS.
This is exactly an issue, mentioned here:
My setup has been reliable for 4 years on this NAS. Historically i would disagree. But lately yes, i agree. QNAP has been making some errors with updates. It doesn’t help that this model is EOL either, so they’re probably not paying it much attention.
The risk of trying another iSCSI solution probably carries much more risk than a single drive initially, but it’s the longer term win i’m after.
That’s a good looking issue, thank you for entering it to have Devs look at. In the meantime the iSCSI watchdog is back on.