I’m well aware of recent network performance and in fact I have bad news for you. It’ll take more than 6 years if you take deletes into account. For reference check the earnings estimator.
It does, but more recent data seems to be a little more frequently downloaded as well. It’s not all that clean cut. I have some older nodes that have been full for a while and they don’t see a lot of egress.
About $3.80 according to the earnings estimator, but please let me know if any numbers/settings seem off to you.
Vetting ends at different moments on different satellites. Some may take long, but that’s usually because they also see low activity, so the ones that take long to vet are also the ones that have the lowest impact on your payouts. For the rest of this message I will just post a screenshot of what the first 2 years look like.
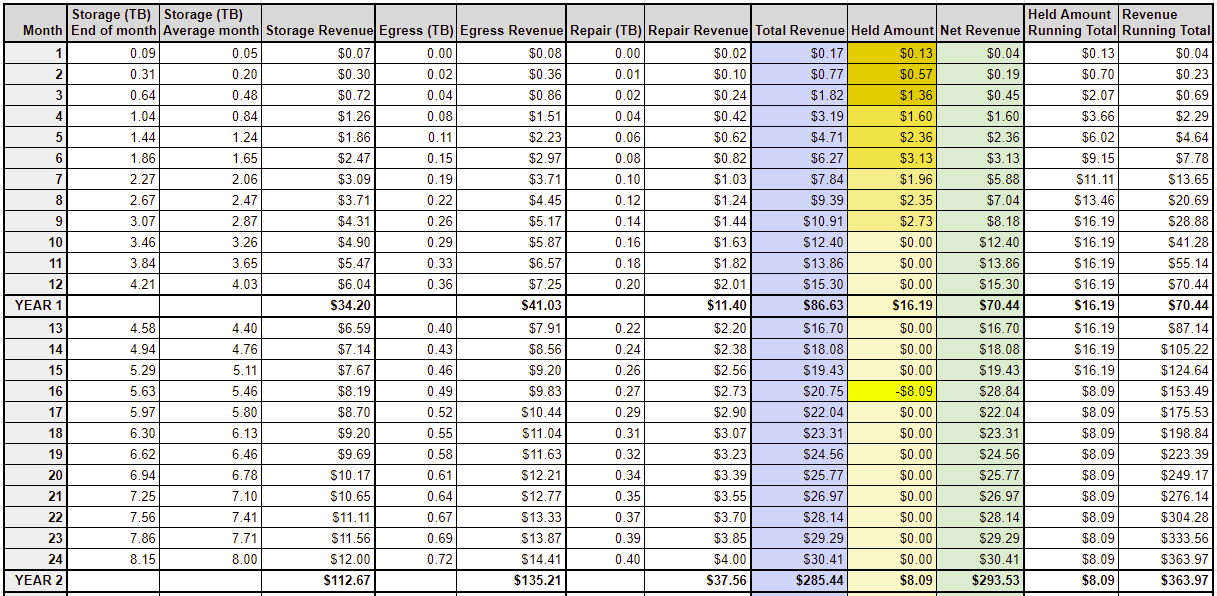
If anyone reads this message more than a few months from now, be sure to check the link I posted earlier. Network behavior may have changed.
Yeah, that slowdown starts to have a significant impact in year 3. By the end of it you will have closer to 11TB actually, not 15TB. The max potential (where deletes match ingress) is currently around 22.5TB. The closer you get to that the slower used space will increase.
So yeah, I mostly agree with your numbers with some refinements. I don’t think that negates the part you quoted though. Rather than making blanket judgements I much prefer providing information like you did as well and leaving the judgement to everyone for themselves.