It’s a 12V 3A power supply.
It’s important to me, no? If it wasn’t, I would not care if it was disqualified.
First, I have to figure out how to make the probem never happen again. I would not just be doing the same thing again (expecting different results :))
I was saying that before. Here’s how I look at things: figure out the requirements and then figure out how to meet them. One of the requirements (something I complained about a lot) was no more than 5 hours of downtime in 30 days, which also meant no more than 5 hours of continuous downtime. Also, the node sometimes would corrupt its database if shut down uncleanly.
To meet that requirement you do need redundant power supplies, UPSs, a generator and at least two uplinks. Reason being that nobody is in a hurry to fix residential power or internet when it fails.
However, since that particular requirement was relaxed, I no longer think that UPSs, generator and two uplinks are required, since even residential power and internet would be fixed well within 30 days. It would be possible to even buy parts like a power supply if one breaks.
Then maybe nodes should not be disqualified in 4 hours with no notification and no chance to get them back when the OS freezes? Pause the node, make the node stop itself, put it in containment, whatever, just give the operator time to figure out and fix the problem.
My problem with this is the disconnect between the recommendations and the requirements. The recommendations say one thing, but if I think how to meet the requirements, then I get something way above the recommended setup.
The worst thing about this is the required reaction time. Since I have RAID, the data should not be lost or corrupted unless multiple drives fail (or the node software deletes the wrong files), so I should be OK with leaving the server alone for a while. However, it looks like if a software problem or a certain type of hardware problem happens, I only have about 3 hours to react and fix it, otherwise my node would be disqualified without actually losing a single file.
Imagine this: your client wants you to set up and manage a server for him. Instead of buying proper hardware and hosting it in a datacenter somewhere, he gives you an old desktop with a single drive and says “it will be good enough, I won’t buy new hardware”. Well, it’s his choice so you set it up, connect it in his office somewhere and the server runs OK. You monitor the server, apply updates to it etc and he pays you every month for the service. After a while, the hard drive crashes or something else happens. The client is angry and demands compensation for his loss - 90% discount for the next year, then 65%, then 48%, then 12% and after four years he’ll pay you the full price again.
Would you consider such client to be reasonable?
Does that risk depend on me in any way? If not, I don’t care, free money is free money. If it depends on me, then I would rather make sure that the payments did not stop.
Also, if I buy $1000 of hardware, I’ll be able to use it for my needs as well or for something else if Storj as a project fails.
I have long held the view that storj does not state their policies for the benfit of SNO’s.
It has been stated by storj (and by association BrightSilence) that SNO’s are better off to run without redundancy and use two (or more nodes) instead of RAID.
Is this even true anymore with current ingress levels?
As an example, if a SNO has 2 x 8TB (not huge by any means given the standards today) drives they would be looking at multiple years to fill just one on current ingress levels. Have two drives on the same ip and we are now looking at many more years if the traffic is shared across nodes.
As is often said in the forum storj does not pay for available storage - only what is used.
If one drive fails they will start back at square one to run a new replacement node and go through what seems to be now a multi month vetting period. I don’t know about others but from my perspective the data you hold become more and more valuable and there is a desire to protect what you already hold.
Really… Did you even read my post?
This thread’s pretty busy and full of interesting statements!
But that’s not very relevant here. The first step, and what the posted idea is about, is to inform that a node is not responding. Sure, why would be useful, it’s important, but not as important as being notified in the first place that there is an incident that requires attention.
Not what the idea is about. Besides, the satellites already consider failed audits and “just being offline” as different.
If you are worried about malicious nodes, maybe this rule should be changed instead?
You probably have access to more detailed statistics, having access to payment processing and satellite logs, but I find this statement rather difficult to believe in. Right now, for example, I don’t believe I’ll ever earn back from my nodes my usual market rate for all the time I’ve invested in running a node—unless maybe ingress suddenly increases tenfold. I’m doing it mostly for fun, though, so it doesn’t bother me that much.
Agreeing with @BrightSilence here: this would only make sense if MND was hosted on different hardware than the nodes themselves, which might be a little difficult for home users.
I’d feel uneasy with this solution, as it would only suggest a proxy measure to the status of actual service. For example, in case of heavy external IO impacting actual downloads, a separate HTTP service likely wouldn’t be affected, making false negatives. Besides, you seem to have described this scenario with:
Having a separate HTTP listener will result in the same type of problem.
The best kind of monitoring would involve speaking DRPC and requesting correct downloadable pieces, which is exactly what satellite audits already provide.
Well, in case of a service like Storj’s, where it’s easy to just run hundreds of nodes and empirically determine many hidden parameters by sacrificing them one by one, I don’t think the suggested solution actually makes the situation worse. Though, maybe you can suggest a specific example?
Oh, didn’t know. That actually makes the original post’s idea more relevant to me…
My friends hosted a subversion server for a small software company on flash drives, mirrored on 3 or 4 devices for redundancy. The average lifespan was 3 months (-:
What other automated action, not requiring a human operator to be awake at the time of the incident, do you think would be reasonable to save a node from failing too many audits, then?
I recall a statement from some article on scaling up data centers, that as a data center grows and the number of sysadmins working there cannot grow as fast, more and more troubleshooting must be automated. Apparently Google went as far as automatically detecting collisions of MAC addresses of freshly deployed network cards, as at their scale this was a routine incident. When Storj network grows, it will face more and more complex situations occuring frequently.
As long as the prospective node operator is informed of the risks—because taking the risks suggests knowing about them in the first place—sounds right. Right now I don’t think the documentation mentions that a node can be disqualified in 4 hours in the discussed cases.
Setting up an external monitoring system is also raising costs for each node operator. This is why I advocate for the idea presented in this thread’s original post: I believe it will have lower costs (in terms of total human time spent, node operators + Storj engineers) than each node operator setting up their own separate monitoring, potentially incorrectly.
Yes. I did read your post.
You misunderstood my intent. The status page would do a self test of the nodes services. So upload, download, delete a piece. If that times out and the page is still responsive, it will show the timeout error. If the entire system has become unresponsive, the page would show nothing at all. Both of which would trigger uptimerobot (or other solutions) to alert you.
I agree, but that would mean someone has to create a hosted service to do this. I wouldn’t really have a place other than the node machine itself to host it. My suggestion was meant as an intermediate solution.
I’m not sure there is a universal answer to this. Different scenarios require different actions. And in fact the issues with unresponsive nodes wouldn’t even log audit failures, nor would the system be responsive enough to even kill the node. We’re dealing with unknown troubles, I don’t think you can do much more than monitor and report.
Alright then, so you just chose to ignore it. Got it. Very kind of you.
Well, as long as I don’t have to invest any power or hard drive space, sure, let it come! Otherwise it’s just a cost/benefit equation which gets less and less interesting the more I have to invest from my side.
I must admit I totally agree with this.
Even though I get why audits can DQ a node quickly, and I know it’s been discussed before… but it’s still something that I’m afraid of: there is still a chance a node gets DQ for good over night.
I get @BrightSilence’s opinion: it’s just a node, it’s supposed to be only a bonus income, and in my case it is. But still, being DQ so quick without a notice and without a chance to fix the issue feels incredibly unfair, after years of making sure the node runs correclty, updates, recovers from crashes/issues and that it makes slowly, little by little, a decent amount of income per month.
If nodes have a 30 days grace period when offline, I don’t see why we couldn’t suspend a node that failed audits to the point where it reached 60%: suspend it, and put it to the test during a grace period. And… notify the SNO. The node keeps failing audits during the complete containment period (10 days for instance)? Then fine, it’s probably broken and lost data: disqualify it.
But otherwise, give it a chance!
There must be a nice middle ground between killing a node in 4 hours and making it possible to abuse the system. I don’t have a solution to propose to be honest, it’s probably quite hard to find the right balance and where to draw the line, but I think it’s worth trying to give SNOs more time when something goes wrong, before disqualifying their nodes for ever ![]()
This may have gotten lost in the discussion, but I definitely agree with this as well. I do think the “when the OS freezes” part is key here though. I think the faster the better to disqualify nodes that have actually lost data or corrupted data.
This problem does need a solution. And for some reason it’s been popping up on the forum more than it did before. Enough that I think it’s something that needs to be looked into. I just don’t agree with all solutions that have been proposed here. I think there are better ways to fix it.
This has my vote because my father in law was running a node on a rpi4 hes never messed with it I setup everything and he was dqed for unknown reasons, It would be nice to have sometime to find what is going on before it fully gets DQed. We are just humans we arent perfect but it shouldnt mean that we are out to take advantage of storj either.
Sure, as long as there are no false positives. However, IMO it would be difficult to make sure the node has lost data. Probably, the most likely indicator is file corruption, but even that could happen because non-ECC RAM had a bit flip. “File not found” and timeouts can easily happen because of some problems that make the data temporarily inaccessible, but not actually lost.
When the node doesn’t reply to an audit with valid data after 5 minutes, what if the satellite was interpreting that as if the node was offline instead of failing the audit? Would that solve the problem as the only way to fail an audit would be to actually reply with invalid data or a “file not found” reply?
A node that lost too much data would still get disqualified fast, but nodes that can’t keep up for some reason would be considered offline until they either recover from whatever was overloading them, or until they go below 60% of online score, at which point it would get suspended and the SNO (hopefully) would get notified something is going wrong?
The only downside I see here, is that someone could tweak the node software so it does not reply when the satellite asks for a data it’s not holding anymore. But that would simply slowdown its inevitable disqualification for a few days… right? 
did some math on it a while back, takes about 2 to 3 years until a storagenode really starts earning optimal amounts.
takes close to a year to vet these days and the recommendation is to use a single hdd which isn’t really reliable enough for many nodes to even reach the optimal earnings.
and really nearly a year to vet and just a bad sata cable causing issues and the node is DQ in like 4 hours… seems very unbalanced… people should have a chance to fix issues.
i don’t see why this has to be so controversial, its about as clear an issue as a bullet to the head.
That sounds a lot like you did some opinion, not math. A general statement like this makes no sense as it doesn’t mention upfront costs, recurring costs or specify what optimal amounts are. Honestly I have no clue how to interpret this.
That part isn’t controversial. Everyone agrees on that. We’re just debating different ways to allow that and weighing in other aspects like opening up the system to abuse. I haven’t seen anyone mention that people should not be allowed time to fix temporary issues.
This year, my node (and probably every other vetted node) received, on average, 425GB/month ingress. Assuming no files are deleted, this works out to 5.1TB/year. So, it would take ~3.6 years for my node to get back to storing 18TB of data.
Due to transaction costs, there were times when my node did not make enough to get a payment every month. it usually makes $50-60. About half of this is for storage ($1.5/TB * 18TB = $27) and the rest is for egress (looks almost equal amounts of repair egress and download egress).
I do not know if newer or older files are accessed more for egress, but I would think egress would also depend on how much data the node has (a node with 9TB of data probably gets about half of the egress my node gets). I would say a node earns ~$3.3 for TB stored.
So, a year after the new node is vetted, it would have about 5TB and up to that point would have earned $76, starting from zero and getting $14 on the 12th month. I do not know what transaction costs are now, but the node would probably only get one or two payments.
After 3 years, it would be 15TB and ~$50/month which is approaching the max amount (because files are deleted, the node would not expand by 425GB every month forever, it would slow down).
I’m well aware of recent network performance and in fact I have bad news for you. It’ll take more than 6 years if you take deletes into account. For reference check the earnings estimator.
It does, but more recent data seems to be a little more frequently downloaded as well. It’s not all that clean cut. I have some older nodes that have been full for a while and they don’t see a lot of egress.
About $3.80 according to the earnings estimator, but please let me know if any numbers/settings seem off to you.
Vetting ends at different moments on different satellites. Some may take long, but that’s usually because they also see low activity, so the ones that take long to vet are also the ones that have the lowest impact on your payouts. For the rest of this message I will just post a screenshot of what the first 2 years look like.
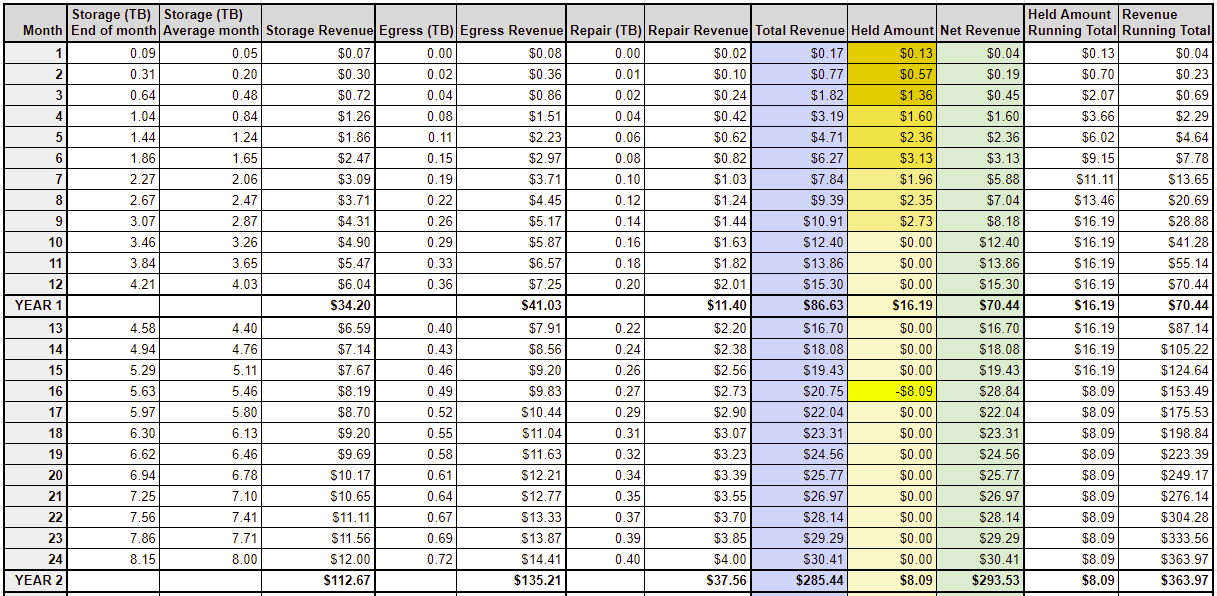
If anyone reads this message more than a few months from now, be sure to check the link I posted earlier. Network behavior may have changed.
Yeah, that slowdown starts to have a significant impact in year 3. By the end of it you will have closer to 11TB actually, not 15TB. The max potential (where deletes match ingress) is currently around 22.5TB. The closer you get to that the slower used space will increase.
So yeah, I mostly agree with your numbers with some refinements. I don’t think that negates the part you quoted though. Rather than making blanket judgements I much prefer providing information like you did as well and leaving the judgement to everyone for themselves.
I was not really trying to get the numbers completely exact and just used the performance of my node for this - I also did not account for held amount. Cool that I got it almost correct.
So, my node currently gets about $60/month and, according to your estimator (default values) it would take 63 months for a new node to get to that level. My node would earn $3780 in that time and a new node would earn $2226. This means that getting disqualified and restarting results in $1554 of lost income. That is a bit harsh punishment for being away from the server for 4 hours (probably less than that if the USB cable fell out of the recommended setup) and also why I recommend using what I consider a proper setup.
From the network-as-a-whole perspective, that should also trigger repairs at some point. If a node with 15TB goes down, that might potentially be quite a lot of data to repair. So there actually is an incentive to Storj to work on a good trade-off, so that in case of a transient problem large nodes don’t disappear in 4 hours.
Also, an important thing here is that Storj whitepaper math ignores the problem of correlation of failures, and it might be exacerbated by common transient problems—like the recent bug that resulted in many nodes suddenly failing audits for pieces the satellite mistakenly thought should be there.
Both of these would really benefit from defining exactly what kind of adversary is being considered when doing failed audits disqualification, because—as I believe—a different trade-off from the current status quo might be necessary.
Yeah we have no argument on that front. And if there is a way that can be prevented without allowing abuse of more lenient rules, I’m all for it. And I think there are some ways that could be done.
Sure, but you didn’t factor in the chance of that happening. For an up to 5 year old HDD there is about a 2% chance per year of failure. It’s really impossible for me to calculate the chance of this system freeze issue happening, but let’s say there is a 10% chance each year that your node gets lost that would have been preventable with the kinds of setups you are suggesting. That means you would have at best a budget of $155 to break even and less to make a profit on that investment. And that’s assuming you already have a node with 18TB of data. For new node operators that number would be much closer to 0. So maybe at some point that investment makes sense. But for new SNOs starting out, I simply can’t justify large upfront costs. For all they know Storj has failed and disappeared before you ever earn that money back. I’m still very happy with my “whatever I already had” setup. The only thing I ever bought was more HDDs to add more storage space. And I only did that when I could pay for it with my Storj tokens. That’s 3 nodes running for 2.5 years now. And my nodes perform and earn exactly the same as yours do. So so far I’m definitely at a larger net profit. (Assuming you spend any kind of money on the kind of resilient setup you’re talking about).