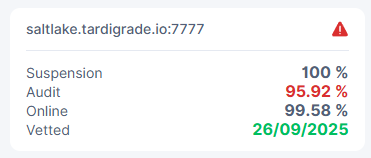
On Saltlake Satellite Node: 12ngDut57JmeSMhpLQiGCXaA3uMtcMGvf4YcoudmUsVPqBPKUDr OR 1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE. Received both Node numbers??
I have been disqualified.
Works fine on another Node.
Can it be re-instated as all the other figure appear to be fine.
Being disqualified is irreversible, and will happen if you fall under an audit score of 96%
Audit’s will be failed if the node is challenged for a piece that it does not have. If the node is not online, it cannot be challenged for a piece, and will take a hit to the online score instead.
Saltlake is the testing satelite, and currently houses ~5GB worth of data on all of my nodes, so I would not care too much about it.
But I would care that I’m having audit issues in the first place. Having audit issues means you have missing pieces, which could indicate bit rot, damaged files, missing files or something completely different.
I’ve been disqualified on a few nodes after migrating from one disk to another, and not doing it properly. This was my fault, and that’s OK. If audit score drops without you immediately being able to say “oh, that’s why”, you should investigate the underlying issue.
If this is a general purpose NAS, the issue could be affecting your other files as well.
You can use this guide to troubleshoot a reason for audit failures:
If you used an USB connection, then I would like to suggest to check the cable, the external power supply and the enclosure or better to make an external drive to be internal.
Please stop the node and check the disk for errors and fix them. If check disk utility would find errors and fix them, you need to run it again, until all errors are gone.
Unfortunately, @arrogantrabbit is right, there is no glitch, it’s a data loss/corruption and it may affect all other satellites on that node as well.
So, it’s better to figure out a reason and try to fix it.
I had a similar issue with salt lake a month or so ago after changing hardware on one node. Saltlake decided it didn’t like this particular node - and similarly as with your situation, all the other satellites were and still are fine, having no issue.