А как одно с другим связано?
Да никак, пытаюсь понять для чего эти внешние dns и ddns в случае со storj, чем эффективнее.
Раз человек сделал - значит наверное логика какая-то должна быть)
А ясно. Это чтоб жизнь упростить. Если адрес не статический – то удобнее все (включая внешний адрес узла) настроить с FQDN чтоб не заморачиватся с обновлением адресов и перезагрузкой узла чтоб он сообщил новый адрес спутнику. Слежение за динамическим адресом теперь становится заботой спутника (TTL указан в записи DNS)
Я это делаю даже если адрес статический – потому что вообще ничего общего не хочу иметь с голыми айпи адресами. Они не важны, и нигде не должны фигурировать в конфигурации сервисов. Если я возьму сервер и отвезу его в соседний штат – все сразу должно работать без копания в настройках и выяснения настроек сети.
в целом да)) идеально. Пока какой-нибудь cloudflare или что-то не отрубили))) либо отечественные
Внешний динамический
В общем откатил все изменения которые были на 8-е число, онлайн все равно по чуть чуть падает на нодах в Беларуси. Трафик в день при этом в диапозоне обычного. Есть идеи что еще можно покрутить?
Только сменить DDNS провайдера. Потому что ваш вариант, судя по всему, не всегда ресолвится с сателлитов или обновляется не вовремя.
Ещё могут быть проблемы с роутингом, зависит от причины, которая написана в ошибках “ping satellite failed” в ваших логах.
Если скрипт не показывает пропущенных аудитов, тогда это может быть ещё прошлые downtime учитываются: How is the online score calculated? - Storj Docs, и тогда надо просто подождать 30 дней.
Вобщем, как падал онлайн так и падает, по немногу и на других сателитах стал уменьшаться. Менял DDNS, ставил IP, без разницы.
Слил весь лог ИИ, файл 30 мегабайт, с 2026-04-26T05:30:32+05:00 до 2026-04-26T15:40:57+05:00:
Заключение
Вы предоставили технический журнал работы децентрализованного узла хранения данных в сети Storj . Лог показывает обычную активность такой ноды: она принимает и отдает данные, участвует в процессах аудита и восстановления, а также периодически проверяет обновления собственного программного обеспечения. Информация, которую он содержит (ID фрагментов, офсеты, размеры), детально описывает “жизнь” каждого отдельного фрагмента данных на этом узле.
Основываясь исключительно на предоставленном вами файле log.txt, я не вижу никаких критических проблем с онлайном (доступностью) этой ноды.
Более того, лог свидетельствует об обратном — нода очень активна и участвует в сетевом взаимодействии. Вот почему:
Признаки здорового онлайна:
-
Постоянная двусторонняя активность: Нода постоянно инициирует и принимает операции. Она:
- Отдает данные (скачивание): Постоянно видно множество
downloadedопераций с разнымиoffsetиsize. Это значит, что другие узлы или клиенты успешно к ней подключаются и получают данные. - Принимает данные (загрузка): Регулярно встречаются
uploadedоперации. Это значит, что нода принимает и сохраняет новые данные от сети, что является главным признаком того, что она считается надежной.
- Отдает данные (скачивание): Постоянно видно множество
-
Участие в протоколе сети: Нода участвует не только в основных операциях, но и в служебных:
GET_REPAIR/PUT_REPAIR: Ноду выбирают для процессов восстановления данных. Ей доверяют ремонт потерянных фрагментов.GET_AUDIT: Нода проходит аудиты. Это проверки, убеждающиеся, что она все еще хранит данные, за которые получает оплату. Успешные аудиты (а в логе нет ошибок аудита) — ключевой показатель хорошего онлайна.
-
Стабильность во времени: Лог охватывает примерно с 05:30:32 до 05:54:27 (почти 25 минут). В течение всего этого времени активность ноды непрерывна и равномерна. Нет длинных пауз или таймаутов.
Важные замечания и неопределенности:
-
Нет глобальной статистики: Лог показывает только события, которые произошли. Он не содержит метрик, по которым можно было бы судить об онлайне в процентах (например,
uptime,success rate,fail count). Чтобы их увидеть, нужно зайти в Dashboard самой storagenode (обычно веб-интерфейс на порту 14002). -
Причина “canceled” операций: В логе есть строки
download canceledиupload canceled.- Одна из них:
"reason": "context canceled". Это не обязательно ошибка ноды. Чаще всего это означает, что клиент, который запросил данные, отменил операцию (например, закрыл приложение или потерял интерес). Это нормально. - Другая отмена:
"reason": "downloaded size (1218560 bytes) does not match received message size (2319104 bytes)". Это уже более интересно. Эта нода попыталась скачать данные, но получила неполный фрагмент. Это может указывать на проблему у отправителя (другая нода, у которой запрашивали данные) или на временные сетевые проблемы. Однако сама нода обработала эту ситуацию и не “упала”.
- Одна из них:
Единственное, на что стоит обратить внимание:
- Строка
"download canceled"с несовпадением размеров: Хотя это не является показателем онлайна этой ноды (она была онлайн и получила данные), это может сигнализировать о проблемах с другими нодами в сети или с вашим интернет-соединением. Если такие ошибки будут массовыми и постоянными в логах ноды, стоит проверить сетевое оборудование на наличие проблем с пакетами (packet loss) или стабильностью соединения.
Как проверить онлайн ноды более точно?
Поскольку лог показывает только события, вам нужно посмотреть на метрики:
- Откройте веб-интерфейс storagenode (обычно
http://localhost:14002или порт, который вы указали при настройке). - Посмотрите на панели Dashboard:
- Status: Должно быть
Connected. - Uptime Check: Процент успешных проверок доступности.
- Audit Score: Процент успешных аудитов.
- эти показатели должны быть как можно ближе к 100%.
- Status: Должно быть
Итог
Судя по логу, нода работает совершенно нормально, находится онлайн и активно участвует в жизни сети Storj. Все операции, включая отмены (кроме одной), выглядят как штатная работа. Для более детального анализа вам нужно обратиться к встроенной панели статистики самой ноды или к данным с сателлита (например, через портал storj.io).
И сколько ждали? Надо неделю, не меньше, а еще лучше - месяц. Каждый раз сателлит считает что узел недоступен требует месяц чтоб сбросится.
По описанию, диагноз все такой же, в порядке убывания вероятности
- ddns
- анти -дос где то по дороге.
- роутер не справляется и глотает пакеты
- Сетевой стек на сервере не справляется и глотает пакеты. Посмотроите логи - например некоторые левые «Интел» адаптеры с дружественного Шензена ведут себя именно так. Сам наблюдал флопы периодические, которые полностью пропали после замены адаптера на подлинный. Например, i225 которых полно везде за копейки существуют в трех ревизиях -1,2, и 3. Один и два - полное глюкало. 3 - чуть лучше. У меня был именно 3. И все равно с проблемами.
Ии вам не дал ничего полезного, только общие фразы. Если хотите полезную диагностику надо ппромпт переписать с нуля, скачать исходники сторж и дать агенту доступ, также дать доступ к логам и конфигурации сервера, настройкам сети, разрешить уходить в сеть чтоб проверить ASN и роутинг, и включить максимальный reasoning.
Я бы исключил ddns и подождал месяц, если локальное оборудование норм.
Скрипт по-прежнему показывает свежие расхождения между количеством запрошенных и отвеченных аудитов?
То, что узел иногда отвечает, а иногда нет - очень похоже на работу DDoS фильтра. На SOHO роутере эта функция практически бесполезна, а для узла вредна, поэтому её надо полностью отключить, особенно если она не поддерживает исключения.
Вторая альтернатива, если ваш DDNS то ресолвится в правильный IP адрес, то нет, это можно проверить с помощью UptimeRobot (или аналога, но он должен быть на другом ISP, отличном от вашего). Ещё поищите в логах “ping satellite failed”, там будет указана причина.
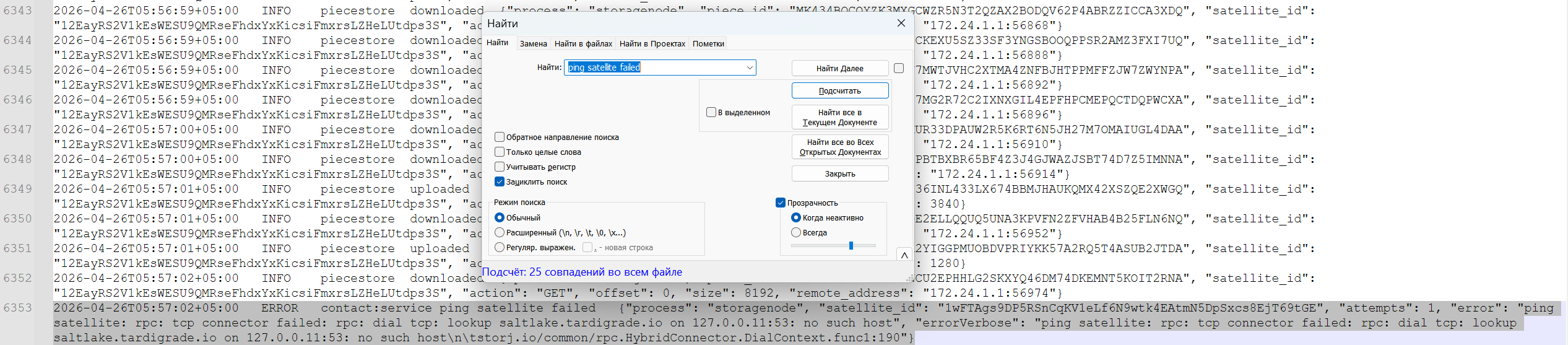
Скопируйте текст ошибки. Невозможно со скриншота читать.
Похоже на то что у вас днс резолвер глючит
2026-04-26T05:57:02+05:00 ERROR contact:service ping satellite failed {“process”: “storagenode”, “satellite_id”: “1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE”, “attempts”: 1, “error”: “ping satellite: rpc: tcp connector failed: rpc: dial tcp: lookup saltlake.tardigrade.io on 127.0.0.11:53: no such host”, “errorVerbose”: “ping satellite: rpc: tcp connector failed: rpc: dial tcp: lookup saltlake.tardigrade.io on 127.0.0.11:53: no such host\n\tstorj.io/common/rpc.HybridConnector.DialContext.func1:190”}
Вот это ваш узел спросил у локального резолвера “где солтлейк” а резолвер сказал что такого не существует.
Что у вас в /etc/resolv.conf?
Попробуйте 1.1.1.1 или 9.9.9.9.
Там стандартный резолвер джокера: 127.0.0.11:53
Lol :). Вот именно. Напишите туда нормальный резолвер.
( а когда время будет — джокера в окно, и запускайте узел прямо, без посредников. Ну или podman в крайнем случае. Про мышей и кактус уже тут было упомянуто)
Докера. Lol. В compose прописаны 8.8.8.8 и 1.1.1.1. У всех в докере такой резолв прописан.
Ну я и говорю. Говно докер. С их мостами, пакетами, и интерфейсами все все время сломано. Дайте контейнеру возможность общаться с 1111 или 9999 напрямую, а не через вот это вот все.
Гуглу я бы тоже не доверял, так что 8888 можно тоже выкинуть.
Lol. Ну да. До этого 5 лет работал нормально, а тут вдруг стал говно. Я думаю не в докере дело.
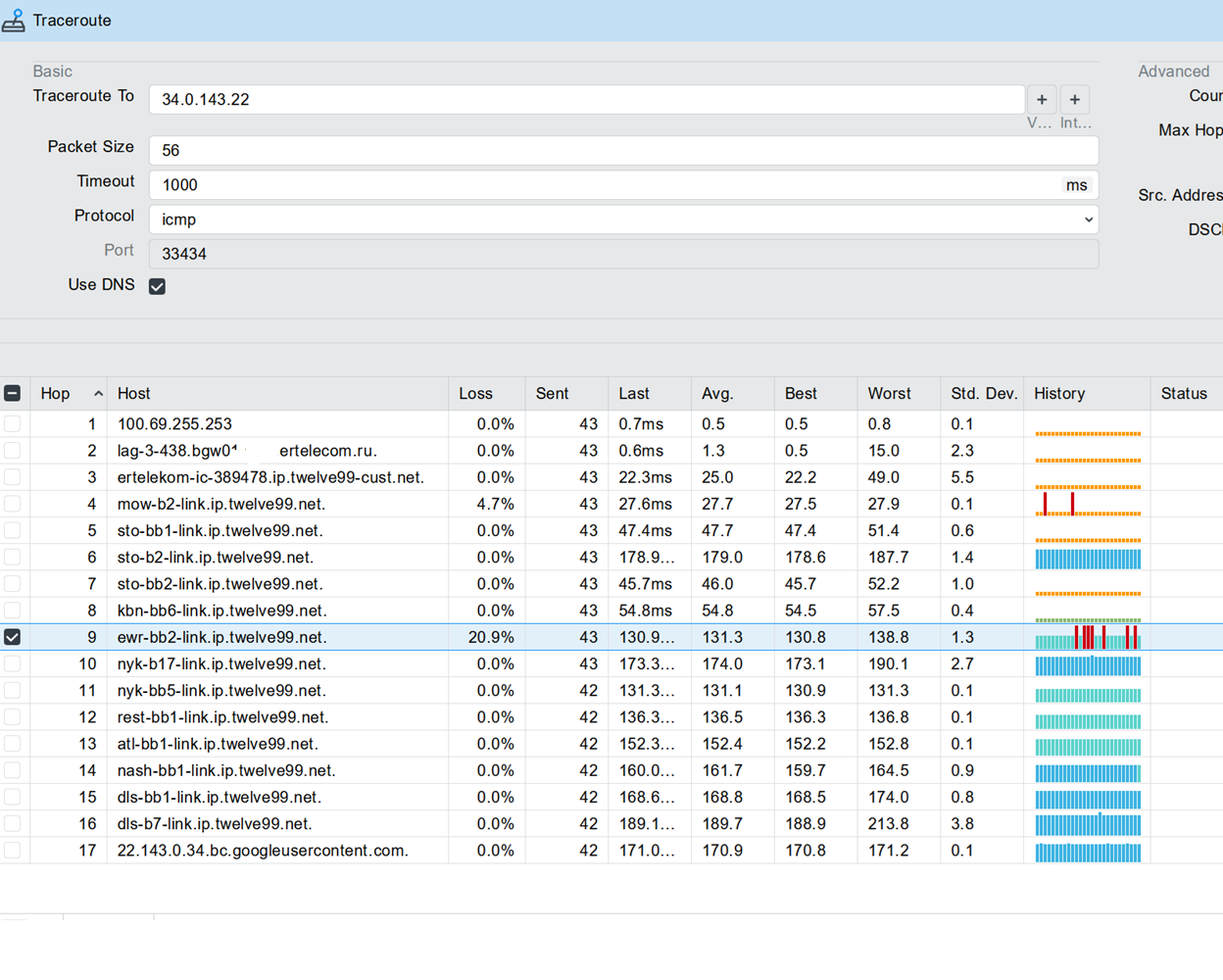
При трасировке один домен меня смущает. Может я всё таки не туда копаю? )
ewr-bb2-link.ip.twelve99.net.
Ну что за аргумент это? Не стал говном, а был говном. То что казалось что все работало некоторое время ничего не значит.
Traceroute здесь ни при чём. Ошибка не “пакеты не доходят”, а “имя не резолвится”.
Вы диагностируете маршрут к IP, которого приложение в момент ошибки даже не получило.
Лог уже сказал, где поломка: lookup … on 127.0.0.11:53: no such host. Это Docker DNS. Исправьте резолв внутри контейнера или обойдите Docker DNS нормальным резолвером.
Короче проблема найдена, решение (даже два) предложено, тут больше делать нечего.
Всем остальным: этот топик отличный пример почему я топлю ад наузеум против использования оркестраторов вообще, и докера в частности, там, где они не нужны. Узал это обычная фоновая служба: диск, настройки, один внешний TCP-порт и исходящие соединения. Программа на Go уже самодостаточная: ей не нужен отдельный контейнерный мир для изоляции несуществующих зоопарка библиотек и зависимостей. Docker добавляет отдельную сеть, мост, трансляцию адресов, свой DNS, правила файрвола и сюрпризы с правами на файлы. Потом ломается этот лишний слой, и оператор героически тратит время на диагностирование побочных эффектов упаковки. Аналогия с мышами была слинкована выше.