Notified the team, but weekends, so please, be patient. Thank you for notify!
1 Like

There is a pattern, maybe just normal behavior of repair queue? ![]()
Datum | GET_AUDIT | GET_REPAIR | PUT_REPAIR
===========+============+============+============
2025-11-20 | 60548 | 1026391 | 221189
2025-11-21 | 13477 | 1485985 | 241070
2025-11-22 | 1490 | 959964 | 350782
2025-11-23 | 0 | 956710 | 225705
2025-11-24 | 142980 | 782509 | 109223
2025-11-25 | 145651 | 926168 | 194103
2025-11-26 | 97111 | 519858 | 110719
2025-11-27 | 69843 | 523825 | 130900
2025-11-28 | 31559 | 937483 | 202901
2025-11-29 | 0 | 507687 | 118569
Seems that audits are again down
1 Like
Would you mind to share your results?
I don’t know about audits: but we feel overdue for a bloom filter. Normally it seems like total-used-space slowly grows for 2-3 days before a BF scrapes a bit off the top over around 12 hours. I think we’ve only-been-going-up for at least 4 days now…
…not that I’m complaining ![]()
Edit: Spoke too soon: about 10h after posting this a new bloom filter started chewing away used-space… all is well in the world again
1 Like
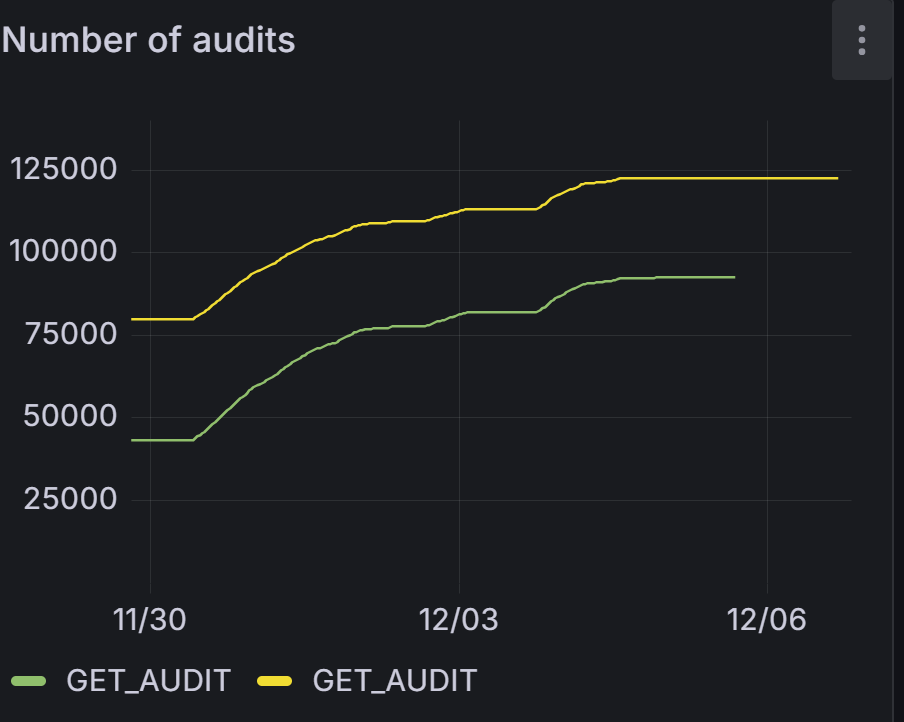
It’s from multinode
And it is the third time when audits not working the whole day
1 Like
root@server030:/disk101/storj/logs# date; for day in {01..06}; do echo -n "Number of GET_AUDITS @ 2025-12-$day : "; grep "^2025-12-${day}T" server*-v1.142.7-*.log | grep '"GET_AUDIT"' |grep -c "downloaded"; done
2025-12-09T12:05:39 CET
Primary Nodes (132) - 618.70 TB used
Number of GET_AUDITS @ 2025-12-01 : 8.000.460
Number of GET_AUDITS @ 2025-12-02 : 2.596.175
Number of GET_AUDITS @ 2025-12-03 : 2.740.627
Number of GET_AUDITS @ 2025-12-04 : 2.252.261
Number of GET_AUDITS @ 2025-12-05 : 1.739
Number of GET_AUDITS @ 2025-12-06 : 0
Number of GET_AUDITS @ 2025-12-07 : 0
Number of GET_AUDITS @ 2025-12-08 : 586.875
Number of GET_AUDITS @ 2025-12-09 : 1.548.178
Backup nodes - batch 1 (468) - 5.03 TB used
Number of GET_AUDITS @ 2025-12-01 : 186.128
Number of GET_AUDITS @ 2025-12-02 : 61.817
Number of GET_AUDITS @ 2025-12-03 : 66.234
Number of GET_AUDITS @ 2025-12-04 : 47.165
Number of GET_AUDITS @ 2025-12-05 : 0
Number of GET_AUDITS @ 2025-12-06 : 0
Number of GET_AUDITS @ 2025-12-07 : 0
Number of GET_AUDITS @ 2025-12-08 : 15.466
Number of GET_AUDITS @ 2025-12-09 : 27.860
Backup nodes - batch 2 (1000) - 0.49 TB used
Number of GET_AUDITS @ 2025-12-01 : 166.489
Number of GET_AUDITS @ 2025-12-02 : 52.211
Number of GET_AUDITS @ 2025-12-03 : 63.553
Number of GET_AUDITS @ 2025-12-04 : 43.628
Number of GET_AUDITS @ 2025-12-05 : 125
Number of GET_AUDITS @ 2025-12-06 : 0
Number of GET_AUDITS @ 2025-12-07 : 0
Number of GET_AUDITS @ 2025-12-08 : 14.871
Number of GET_AUDITS @ 2025-12-09 : 27.294
Th3Van.dk
3 Likes
Repair traffic still looking normal. So maybe audits just stopping when repair queue reaching upper limit and starting again when falling below lower limit.
Date | GET_AUDIT | GET_REPAIR | PUT_REPAIR | GET | PUT
===========+============+============+============+============+============
2025-11-27 | 69843 | 523825 | 130900 | 4981789 | 1473598
2025-11-28 | 31559 | 937483 | 202901 | 4559119 | 1306454
2025-11-29 | 0 | 633021 | 153364 | 5325967 | 1223805
2025-11-30 | 154835 | 574405 | 121308 | 5567007 | 1206143
2025-12-01 | 163012 | 322076 | 69666 | 5423152 | 1204811
2025-12-02 | 49387 | 729818 | 132703 | 4755813 | 1097049
2025-12-03 | 58736 | 564826 | 126548 | 4553236 | 1318987
2025-12-04 | 50614 | 998196 | 228868 | 4677372 | 1104113
2025-12-05 | 116 | 622224 | 126139 | 4243282 | 1196342
2025-12-06 | 0 | 705784 | 196930 | 3955739 | 1298771
1 Like
Audits seems to stop every Saturday. Maybe they have Shabbat? ![]()
2 Likes
No change in online score since 19th November, AP1 and Saltlake - no change for over a month.
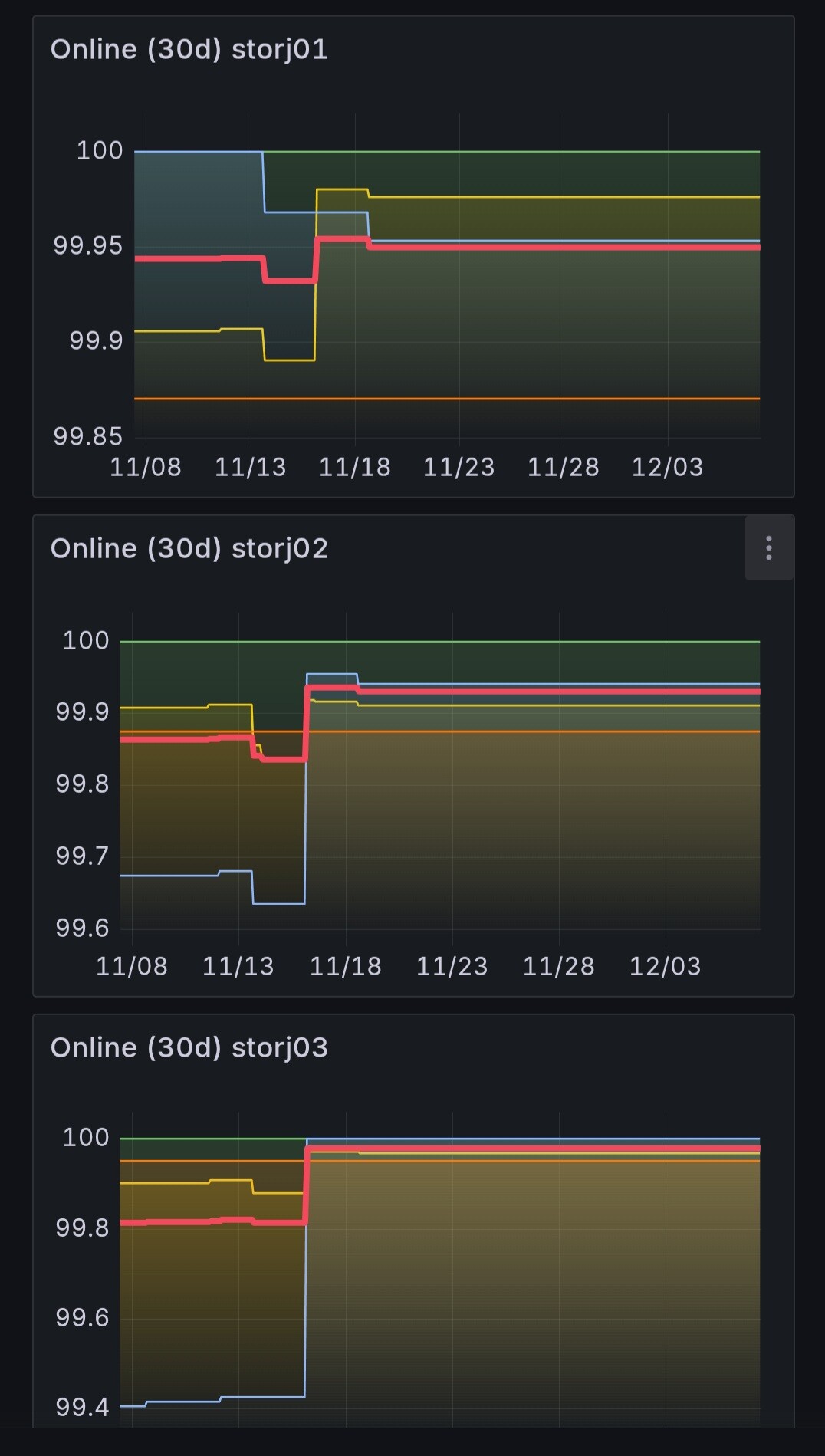
No change in Audit score (eu1) since 19th November.
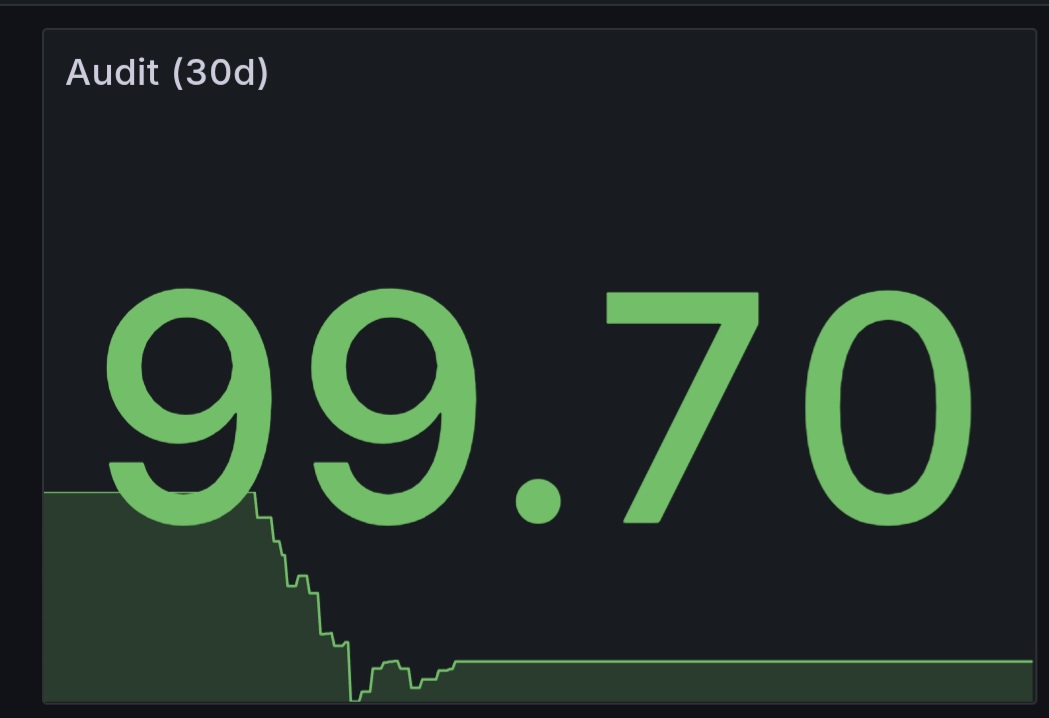
2 Likes

Could you please check with these scripts:
Same, my online score is not updating.
Output of script for 1x Node. Nothing after 17/11.
{
"id": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE",
"auditHistory": [
{
"windowStart": "2025-10-16T00:00:00Z",
"totalCount": 37,
"onlineCount": 35
},
{
"windowStart": "2025-10-22T00:00:00Z",
"totalCount": 42,
"onlineCount": 41
}
]
}
{
"id": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6",
"auditHistory": []
}
{
"id": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S",
"auditHistory": [
{
"windowStart": "2025-11-05T00:00:00Z",
"totalCount": 1985,
"onlineCount": 1981
},
{
"windowStart": "2025-11-12T12:00:00Z",
"totalCount": 1537,
"onlineCount": 1522
},
{
"windowStart": "2025-11-17T12:00:00Z",
"totalCount": 1755,
"onlineCount": 1751
}
]
}
{
"id": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs",
"auditHistory": [
{
"windowStart": "2025-11-12T12:00:00Z",
"totalCount": 324,
"onlineCount": 318
},
{
"windowStart": "2025-11-17T12:00:00Z",
"totalCount": 352,
"onlineCount": 349
}
]
}
This is mean that the latest discrepancy was at 2025-11-17, so your online score should recover when it will be out of 30 days window, so around 2025-12-18
AP1 and Saltlake have not changed in over a month.
Other satellites have not changed since 17/11.
There has been down time (not shown in Storj stats).
What about AUDIT score, unchanged since (curiously), 17/11?
2 Likes
The audit score depends on failed audits, if you still have them - then it will not recover.
Goes down with failed audits, goes up with successful audits. Yes I understand how it is supposed to work.
Problem is, it is not working at all!!.
2 Likes