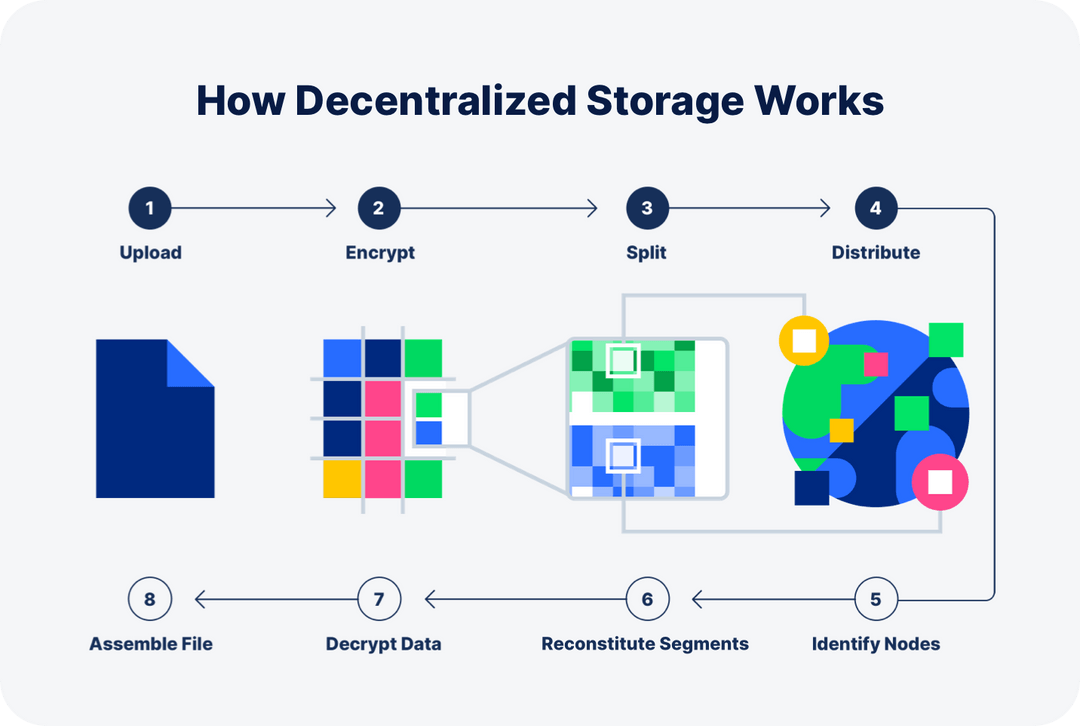
… the phrase “Finally, only 29 of an object’s pieces are needed to reconstitute that data for download.” … but nowhere in these steps is mentioned how many total pieces there are… 29 out of…? For someone who doesn’t know Storj… might be quite confusing in my opinion.
You don’t need to know the total because satellite operator can change that from 100 to 80 to an even lower number. The crucial point is that only 29 pieces are required.
True. But on the other hand it is one of the fundamental principles and core features that you need much much less pieces to get your data back and not all of them. Not even the majority.
So without mentioning somebody could get a false impression and believe maybe 29/31 pieces are required which would give a vary bad taste. Even 29/40 still doesn’t seem to sound very reliable or resilient.
So yes I believe it could (maybe should) be made clearer how few pieces this 29 really is.
This is similar to how Google stores data, it is not about decentralization but data distribution. Decentralization is the control of a system. Storj is centrally controlled not decentralized.
“At the most basic level, Web3 refers to a decentralized online ecosystem based on the blockchain. Platforms and apps built on Web3 won’t be owned by a central gatekeeper, but rather by users, who will earn their ownership stake by helping to develop and maintain those services.”
Thanks for pointing this out, I have brought it to the attention of our web designer and it should get fixed by tomorrow (today is an official holiday at Storj Labs - International Workers Day)
I believe the community can be stronger if we try to look for things to improve, that’s why I created this thread mainly.
About the actual modification on that page - If I can do a suggestion, would be to mention in “2. Split” paragraph, in how many pieces the data is split and for what reason that data is splitted.
The order 1. Upload, 2. Encrypt, 3. Split seems only true when using the S3 gateway. So this illustration does not show the full picture about some core security and privacy feature of Storj DCS and could create a wrong impression.
It works for both cases - you start an upload, then - if you use a native integration, it will be encrypted, split to pieces and distributed.
If you use an S3 integration, it will be uploaded, then encrypted, split to pieces and distributed.
However, for both cases you need to start an upload
It sounds like uploading your data unencrypted first and then it gets encrypted and split into pieces, which is the case for the S3 gateway only.
If you use uplink, you never upload unencrypted data and you don’t have to pass your passkeys to a 3rd party. You keep everything locally.