I have just started up a new node on Debian with the 107.2 release off of github. My last one had a space discrepancy and caused my zfs pool to fill up before the storj node knew how much space was actually used. This caused truenas to fail to run storj.
I have an idea. Why not take a periodic record of the ingress(perhaps once a minute) since the last filewalker run so that that would be a good estimate for storj to know how much disk space is left incase of a OOM or crash until next successful filewalker run.
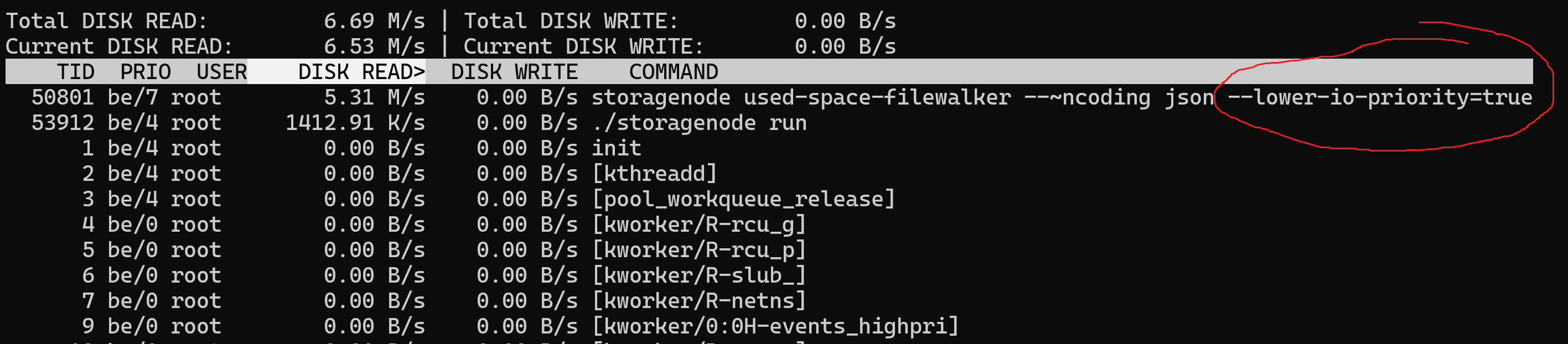
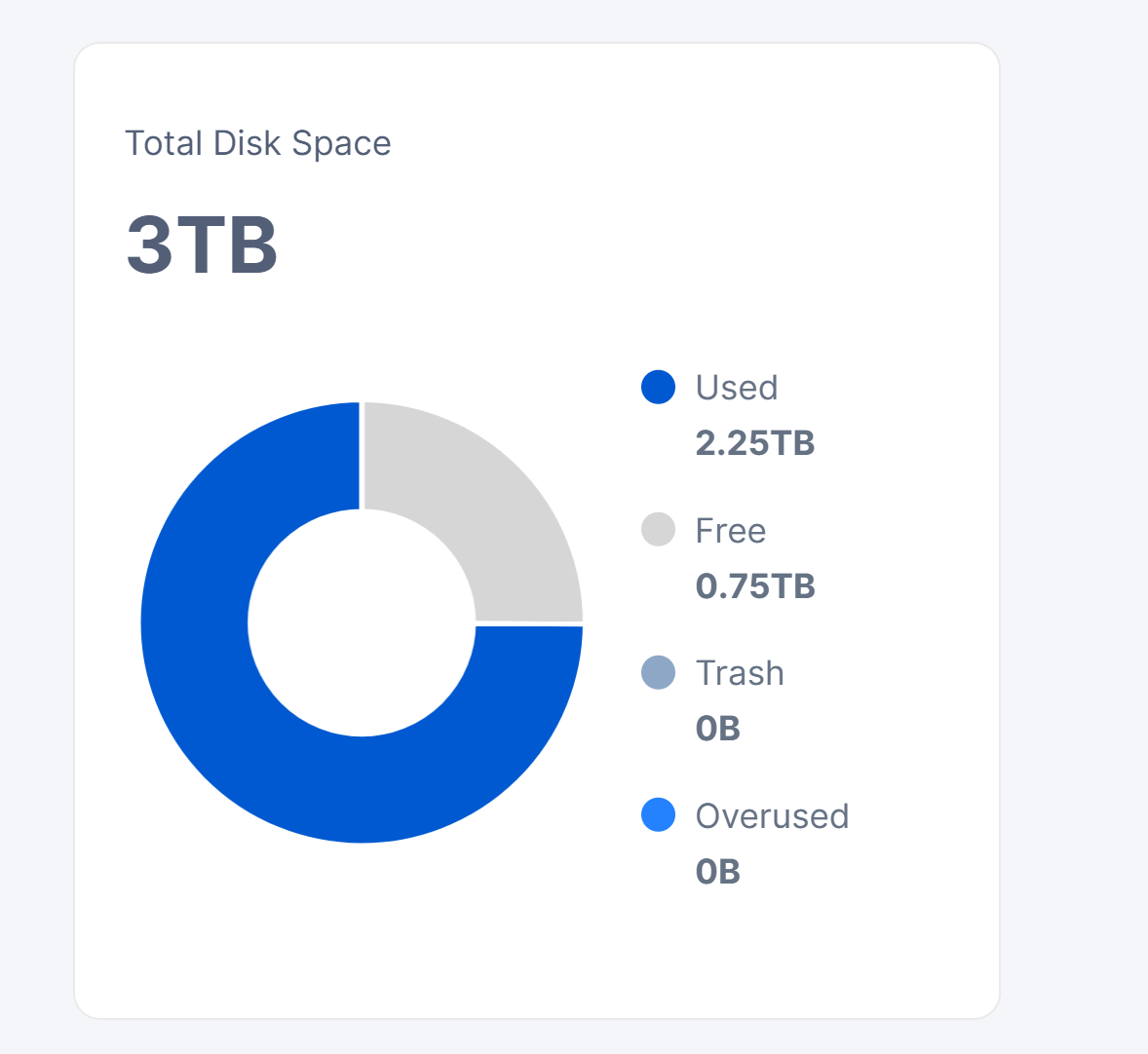
As you can see in the screenshot my problem… I’m just waiting for filewalker to finish then I can move my available disk space to 3TB and i will have the correct used space io storj will know when to stop ingress before my disks gets 100%
Another suggestion would be to set the priority for the filewalker to high when the ingress stops.
I can see that the only io activity is the filewalker atm so it should not be a problem to make it run with all resources since the disks are no longer being smashed with ingress. Hopefully it will cut the time a bit to scan through all the files.
Please double check if you have compression enabled. By default it is off and that will let ZFS bloat the used space on disk.
That is already implemented basically since a long time. The storage node doesn’t count ingress. It increases a counter every time a piece makes it to the end of an upload process. The difference is that if your node gets long tail canceld it would still consume ingress but the data that was written to the disk so far gets deleted and not stored.
But lets say I wait 3hrs and let it ingress some more data. Then ctrl-c the storage node and run it again… the used data that is shown on the dashboard is rolled back maybe 100 or 200 gb… That 100-200gb is not deleted it comes back maybe 10 or 15hrs later when filewalker finishes a run. My problem is why can’t storj remember it has just downloaded 100-200gb before I closed it. That might catch some sno’s out with the disk usage being more than the disk capacity because storj believes there’s 100-200gb free.
Suggestion: Im not a programmer but i hope i can make my self understood.
Set a variable when a node starts
ingressAtNodeStart = bandwithUsedThisMonth
Now every 5 or whatever seconds save this value to disk
ingressSinceNodeStart = bandwithUsedThisMonth - ingressAtNodeStart
If the filewalker hasnt updated the database before u close storagenode.
ingressSinceNodeStart should be roughly how much more data is on the disk than it is reporting
LMfao idk. make a new piece on the chart called estimated usage on last session
Maybe it can’t write the used space db file. There is some caching involved but for that amount of data the last successful write would need to be hours ago.
I know… If i set the allocated space to 10TB then the total space in the dashboard says 3.2TB which is my total disk space. I get that… but the problem is with used space and filewalker not the total amount.
If i shutdown storj when my used space is at 3.1TB and filewalker has not finished. When I restart storj. The dashboard will report the disk usage that was set by the last successful run of filewalker. which may be a few hundred gb. What happens if I only have 100gb of disk left which is reported by zfs list and the dashboard says 300gb free space.
Actually it’s used, but only in the case when the allocation is less than possible to fit (accordingly the used space known by the node though).
It’s also used, if the free space on the disk is lower than 5GB, it should report to the satellites, that’s full.