Hi,
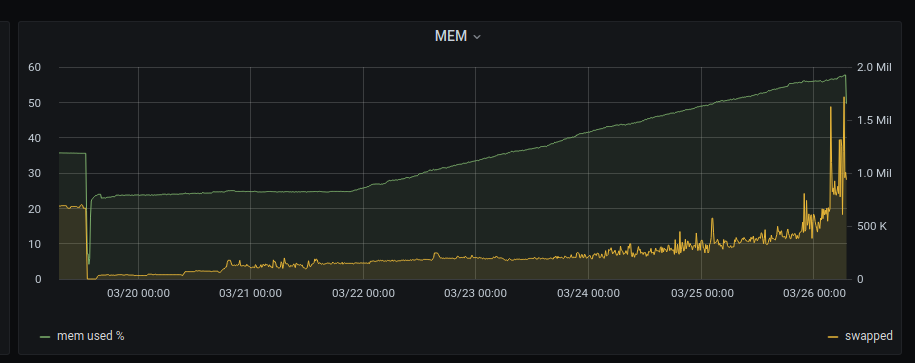
I’ve set up a storage node up and running since 1 week but I’ve realized via telegraf monitoring that memory consumption has grown day by day till saturate the capacity.
memory usage may spike a bit from time to time, but from what i’ve seen from tests lacking memory just limits performance,
i think the highest memory usage i’ve seen was around 3 GB on a single node, but normally its like 200mb avg over months.
so long as you have something like 1GB free memory for the node it shouldn’t be a problem, high memory usage can also becaused by disk latency, if the system cannot write incoming data to disk fast enough, then it will be stored in memory.
We do not support network attached storage, in general the storagenode is incompatible with any network attached storage, especially NFS and SMB.
The only working protocol is iSCSI, but even then your node will lose race for pieces to nodes with direct attached drives.
You can take a look on other problems with NFS: Topics tagged nfs
Sooner or later your node will stop to work.
you might be able to patch it by doing the database move to an ssd… then if that isn’t on the network drive it should in theory be less of a problem… not saying it will fix anything…
but something i might try, but i’m crazy so most likely don’t do that lol
just saying it could help lol if nothing else there are others that will be interested in how well it works