Do you have answer to this ?
I have 12 nodes on CMR disks and one SMR (Seagate Barracuda 5400rpm)
SMR is very slow and noisy ![]() and stressed as you write.
and stressed as you write.
Full SMR node and i see the same as you… to be fair I have synology OS on this disk but i have this synology allocated only for storj.
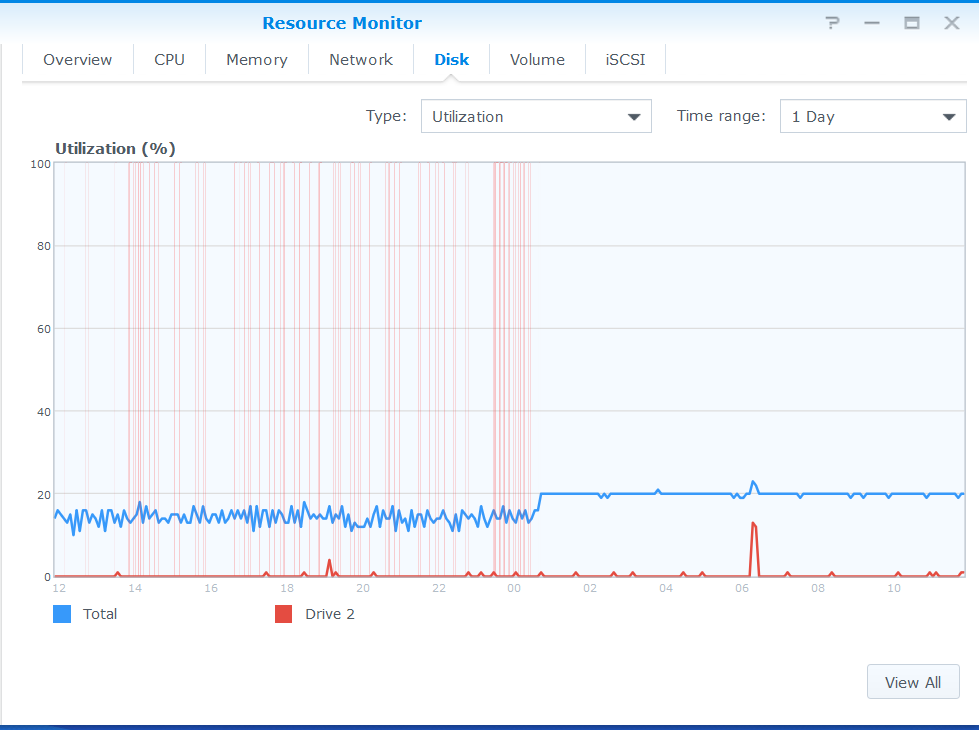
Full SMR

1 Month

VS full CMR node
1 Month
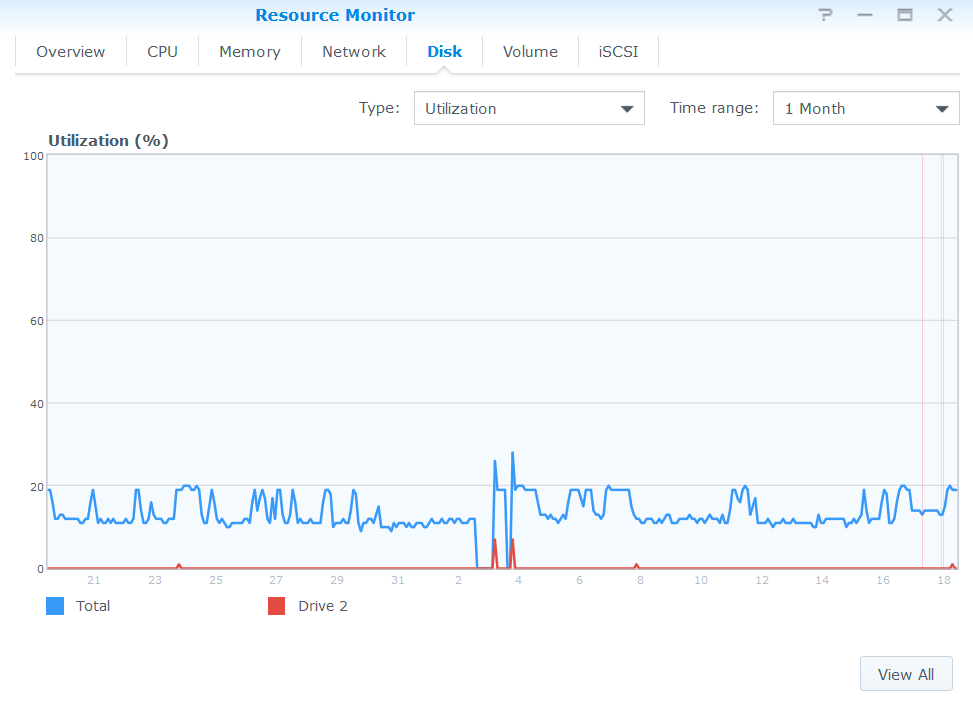
In past i have similar problem on CMR in RAID 5 with activity but now its repair by storj about maybe 6 months ago.