Hello dear Storj community,
At the start of the node or after a storagenode update or randomly scan pieces occur and make our HDD stressed at 99% and more. (100%)
I would like to know what is the answer from storj on that two points
Does Storj will pay this HDD activity (IOPS) to storagenodes operators ?
Is there in 2021 network v3 a real solution to achieve the scan pieces less intensively for our hardware ?
Since disk activity is 100% during scan pieces Storj should pay for HDD usage. Unless using bcache (a storagenode operator solution) with SSD is there another and official solution ? Achieving scan pieces by block or something else ?
Iam today frustrated to ear my HDD spinning at 100% for several minutes/hours, as i know that is trafic (internally called IOPS) and we are not paid for this even HDD are used for this scan pieces.
Best regards.
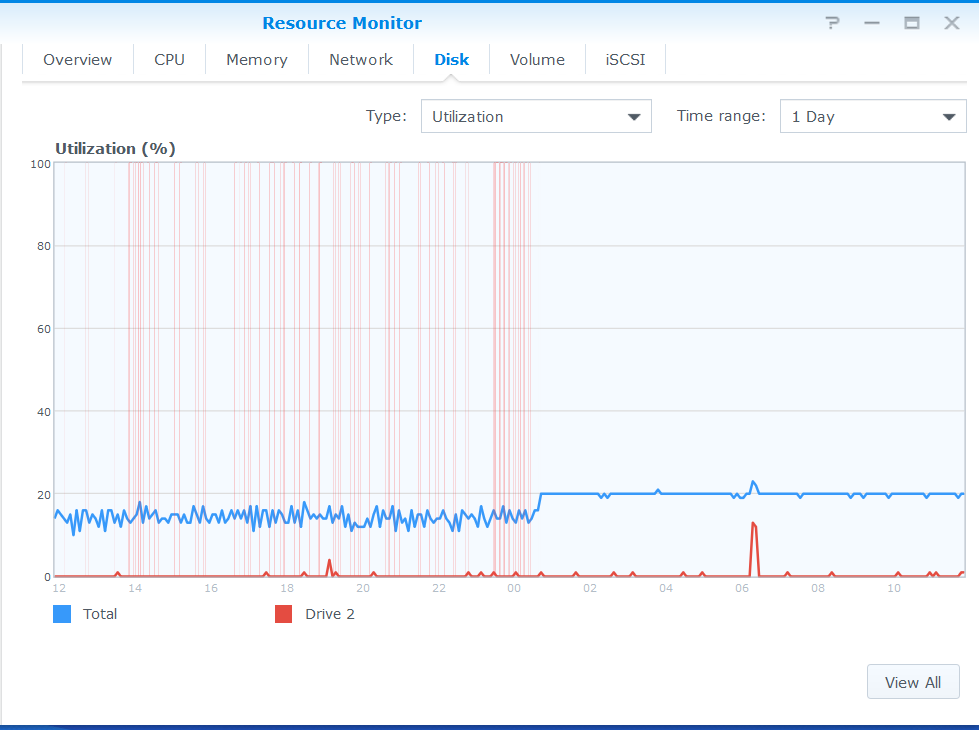
bellow the chart for scan_pieces from 04:00 to 11:00 am (in my timezone)
Hello dear Krystof,
Yes you can also include CPU activity in scan_pieces but guy we speak on storage not on IT as Service.
My disks are SATA 7200RPM. I dont think that they are SMR disks. HDD activity that i show on the attached chart is not only piece deleter it’s scan_pieces which permit each time to storj to identify if the pieces are still on the medium through docker container (lsstat).
I have 12 nodes on CMR disks and one SMR (Seagate Barracuda 5400rpm)
SMR is very slow and noisy and stressed as you write.
Full SMR node and i see the same as you… to be fair I have synology OS on this disk but i have this synology allocated only for storj.
Full SMR
My disks are HGST Ultrastar 7K4000 (0F17731) 3TB HDD 64 Mo 7 200 rpm SATA III 6 Gb/s 3,5in.
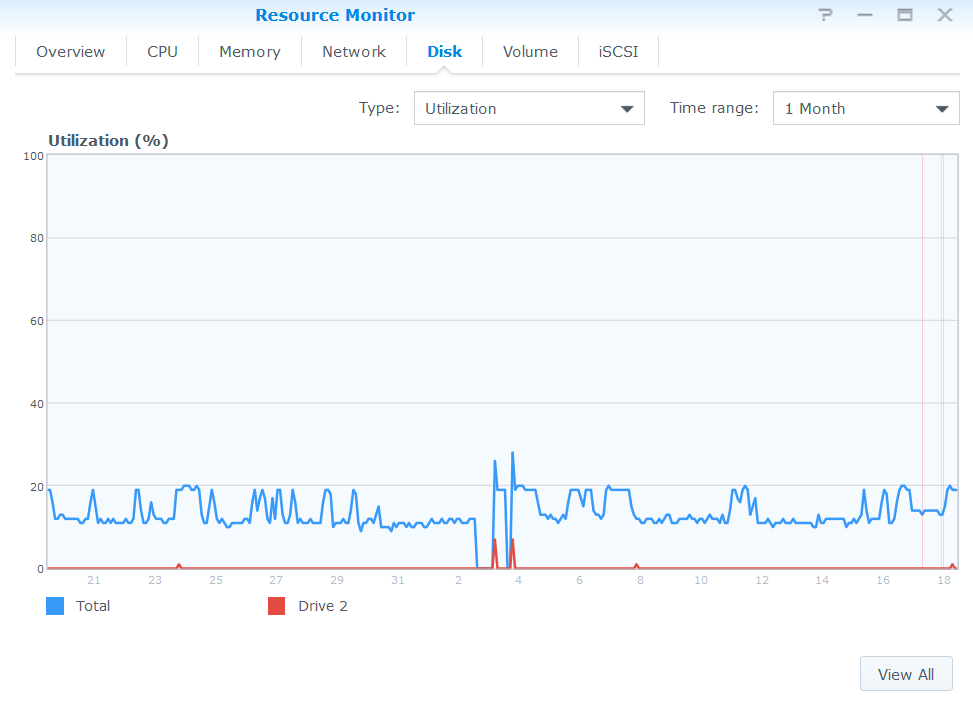
i can provide you the 1 month chart also (this raspberry pi is only dedicated to storj) :
This could probably be configured to run periodically, instead of at startup. Every 5 days for example, of course I don’t know what it does exactly, so I might be wrong. Does it simply enumerate all the files on the drive?
After restarting node or even a node update storagenode may scan files to be sure that files are still accessible accordingly to the db (files list). This method may prevent data to be loss on the network by repairing on a online node in case of the file isn’t here for many reasons as possible, HDD crash, removed by operator or any technical problem that can cause to a file to don’t be accessible on the volume. I can’t say if this pieces scan occur on Windows because i don’t have Windows node, but on linux raspberry this process consume 100% on HDD for a time depending on your volume capacity.
I don’t think they repair any data on your node. It might trigger a repair on the satellite, in which case it only hurts you by uploading “your” piece elsewhere.
The load could be perhaps be made to be configurable, e.g. 40%/60%/70%. Would be useful for low IOPS nodes.
Neither is true. Repair only happens on a satellite after a failed audit (or due to downtime). the node never tells the satellite about a lost piece unless it asked first using an audit.
I am sure that theses scans are from storj side, yes i agree with you that it could be a nice feature to offer a configurable IOPS (Storage load) limit.
Until this it could be very great to
first reduce the intensiveness of this pieces scan
integer with storagenode a option to deport DB folders to other volume
provide a cache capability in the whole code (storagenode side).
The first question is : Is the cache and DB folders redirection is at the end of the storagenode operator ?
The second question is : does storj should pay for IOPS during pieces scaning ?
To answer to @kevink yes, so, audit may be made on db file after db file is completed by pieces scaning (maybe).
It could be appreciate to have more transparency with pieces_scanning process.
If you have the same issue feel free to write here, and please precise your Operating System.
yes that is something we were hoping for for a long time now.
There already is an option to move the DBs to a different volume, just search the forum.
A cache is completely worthless for the piece filewalker because it scans all files. You can’t have all that (or all their metadata) in a cache. Even I with 30GB of zfs cache don’t have a visible improvement. (except for a little less load for writing files and reading from the dbs).
of course not… you get paid for storing files and uploading them. nothing more and nothing less.
No, audits are done by downloading the file from your node which the satellite chooses.
I’m sure you can find information in the source code and documentation. It’s basically for book keeping on the node.
Everyone on every system has the same problem because that’s how the storagenode software works. Some systems might perform better because they have better HDDs, bandwidth or whatever. But still everyone will have the problem of high IOwait after start.
--device-read-bps=[] Limit read rate (bytes per second) from a device
--device-read-iops=[] Limit read rate (IO per second) from a device
--device-write-bps=[] Limit write rate (bytes per second) to a device
--device-write-iops=[]
Guess it could be worth a try. However, it will definitely make the filewalker take longer. And I’m not sure what effect it would have on the remaining operations of the node like egress, since both the filewalker and egress are read-iops. So maybe by halving the read-iops you might shoot yourself in the foot with twice the time for filewalker with problems in egress?