Hello,
I have been working with several members in the unraid forums using the V3 docker and there were several questions that came up, perhaps someone here can help us answer. Several folks running unraid have 10s maybe 100s of TBs to loan but the following answers will help us setup optimal parameters for running storj nodes inside unraid.
All of the following questions assume a single public IP and all storagenodes are running inside docker containers V3 beta.
- When running multiple nodes does the vetting process take longer?
- Based on this post it seems much more efficient to run, for example, 5 8TB storage nodes than it is to run 2 20TB nodes, is this correct?
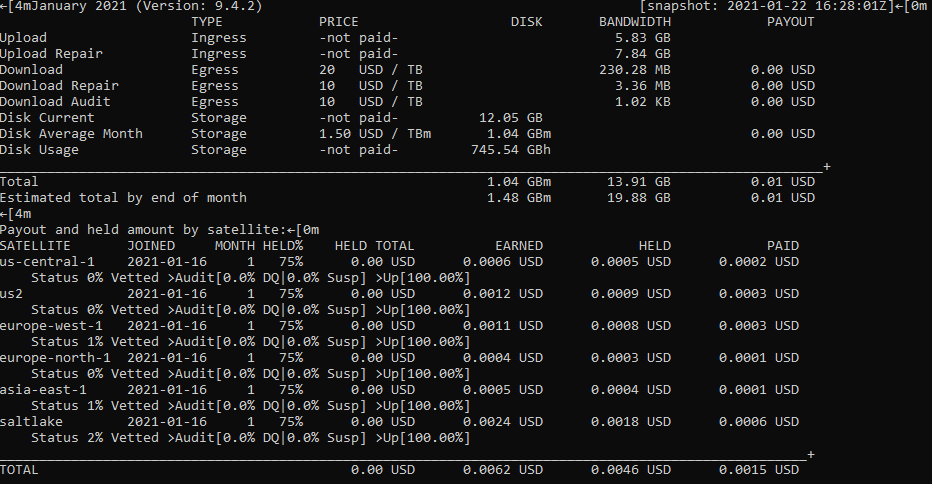
- How can one determine the count of audits completed per satellite (vetting process)? I ask because I can see 100% everywhere but I understand that I need 100 successful audits from all satellites to be fully vetted. This will also help me track / confirm the answer to #1.
Finally, if you had 100TB to loan what via docker containers and a single IP how do you suggest one set it up for optimal utilization?
Thank you.