Thank you both for explaining. I re-downloaded it with your command, I also should have just went with default because I thought I had to type the path.
This is the result from new node about 4-5 days old
Thank you both for explaining. I re-downloaded it with your command, I also should have just went with default because I thought I had to type the path.
This is the result from new node about 4-5 days old
Before you can run the script you need to make it executable:
chmod +x successrate.sh
Still waiting for my docker to be updated…

then just manually update it…
just make sure you got your full docker run command,
docker shutdown storagenode
docker rm storagenode
docker pull storjlabs/storagenode:latest
docker run… very long and complicated command i usually just copy paste…even tho i should have put it in a bash script
but yeah really it’s a 2min deal… if that…
Yeah sure I know how that works but we’ve also had multiple discussion here in the forum about not forcing to update / or keep watchtower to ensure ‘how it should be’…
I’m just whining here that’s all :D:D
why does it matter if you force an update… so long as you know it’s good…
ofc i’m not aware if doing a manual update can confuse watchtower… since i only manual update
well you better strap in… it might be days until it comes around to updating your SN ![]()
the real test of the network will be the day something like 60% of the states blackout… or when the internet breaks or is otherwise impaired across like say the atlantic…
some major shift, that might take 30% of the network offline for hours if not days…
that will be the first true test of if this really works.
i think updating will be hard pressed to make that effect… but it most certainly could… even if kinda tricky to pull off
Yeah I’ll sit it out ![]() Wasn’t it roughly within a week after the first docker update starts? I remember reading something about it but forgot it… Well. #waiting
Wasn’t it roughly within a week after the first docker update starts? I remember reading something about it but forgot it… Well. #waiting ![]()
version is launched for windows, then it takes about a week before it comes to docker and then maybe a few days to update everything… ofc maybe a bit more… but the further towards the end it gets the less likely it is that, you will be the one left ofc…
hitting 10% is not all that easy consistently ![]()
Well this is interesting. I thought 1000 uploads would be a decent sample size, but I ran the script again after 76,000 uploads and my success rate went from 91.2 percent to 98.1 percent. I didn’t change anything on my node. Perhaps it has something to do with time of day or distance to the customers that were active at the time of measurement.
there may be other factors that will play a role…
such a server or hdd’s activity, storage node activity, internet activity…
and then depending on what type of setup you have… then you might add , user activity, network activity…
then you might also have to take into account the storj network conditions… like say if nodes near you or not are performing up to standard… then you might also have some boot time where your system doesn’t run as smoothly, or just after you restarted the storagenode it will perform a lot of processes that will strain the computer and thus affect your successrate % over the short term… ofc long term it sort of drowns out… but it might be why you aren’t seeing higher than 98% but 98% is basically perfect…
i so want the last bit of DL and upload… would be awesome to get it to 99.99% in both just for kicks…
yeah, I forgot about the full node file scan that happens on node restart.
I was enjoying the sun the last two days and didn’t check, updated almost 40 hours ago … just moved old logs aside and will collect and share tomorrow ![]()
Finally here’s my update as well, also bringing back the initial format ![]()
Summary: Looks like almost nothing is failing any longer ![]()
Biggest change is the connection from ADSL 40down and 16 up to a new cable connection. And the logfiles I also re-started 40 hours after the automatic update plus have two nodes running on the same IP (where one I’m gracefully exiting one satellite after the other).
Hardware : Synology DS1019+ (INTEL Celeron J3455, 1.5GHz, 8GB RAM) with 20.9 TB in total SHR Raid
Bandwidth : Home Cable Connection with 300mbit/s down and 40mbit/s up
Location : Amsterdam
Node Version : v1.9.5
Uptime : 88h 19m
max-concurrent-requests : DEFAULT
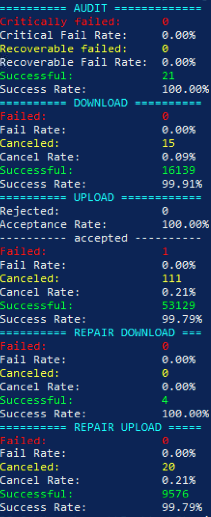
successrate.sh :
========== AUDIT ==============
Critically failed: 0
Critical Fail Rate: 0.000%
Recoverable failed: 0
Recoverable Fail Rate: 0.000%
Successful: 2000
Success Rate: 100.000%
========== DOWNLOAD ===========
Failed: 3
Fail Rate: 0.006%
Canceled: 8
Cancel Rate: 0.015%
Successful: 53650
Success Rate: 99.980%
========== UPLOAD =============
Rejected: 0
Acceptance Rate: 100.000%
---------- accepted -----------
Failed: 2
Fail Rate: 0.002%
Canceled: 39
Cancel Rate: 0.030%
Successful: 128441
Success Rate: 99.968%
========== REPAIR DOWNLOAD ====
Failed: 0
Fail Rate: 0.000%
Canceled: 0
Cancel Rate: 0.000%
Successful: 21637
Success Rate: 100.000%
========== REPAIR UPLOAD ======
Failed: 0
Fail Rate: 0.000%
Canceled: 0
Cancel Rate: 0.000%
Successful: 23976
Success Rate: 100.000%
========== DELETE =============
Failed: 0
Fail Rate: 0.000%
Successful: 23507
Success Rate: 100.000%
Hello , i´m new here ![]()
I have a test node to try storj.
Now it work and in a few days it will be a Raid 5 System with 4 TB Storage
Hardware : Intel i7 6700k
Bandwidth : Home Cable Connection with 1059mbit/s down and 54,2mbit/s up
Location : Kaarst
Node Version : v1.9.5
Uptime : 133h 40m
max-concurrent-requests : DEFAULT
successrate.sh
========== AUDIT =============
Critically failed: 0
Critical Fail Rate: 0,00%
Recoverable failed: 0
Recoverable Fail Rate: 0,00%
Successful: 57
Success Rate: 100,00%
========== DOWNLOAD ==========
Failed: 0
Fail Rate: 0,00%
Canceled: 2
Cancel Rate: 0,18%
Successful: 1125
Success Rate: 99,82%
========== UPLOAD ============
Rejected: 0
Acceptance Rate: 100,00%
---------- accepted ----------
Failed: 0
Fail Rate: 0,00%
Canceled: 17
Cancel Rate: 0,03%
Successful: 55227
Success Rate: 99,97%
========== REPAIR DOWNLOAD ===
Failed: 0
Fail Rate: 0,00%
Canceled: 0
Cancel Rate: 0,00%
Successful: 0
Success Rate: 0,00%
========== REPAIR UPLOAD =====
Failed: 0
Fail Rate: 0,00%
Canceled: 0
Cancel Rate: 0,00%
Successful: 35357
Success Rate: 100,00%
@Phillip
raid 5 with 4 tb capacity…???
so 3 x 2tb drives?
raid 5 will work for 4tb but make sure you can make it into a raid6 because raid5 has fundamental flaws that will long term kill larger storages arrays… it’s just a matter of time…
raid6 doesn’t have this solution or issue… also you might want to strongly consider if you would be better off making multiple nodes instead of a raid5
raid 5 disadvantages… 1 all disk in the array work in harmony… meaning the array has 1x hdd iops
nr 2. raid 5 vs non raided gives you 50% more storage…
nr.3 raid 5 cannot protect against bit rot, and thus essentially the more drives in a raid5 the higher the odds of bit rot becomes, and the array cannot detect where the corruption is coming from, and thus may have you data and then might delete it for migrating the corrupted data to ensure the redundancy.
something raid 6 has no trouble with…
so if i was in your case… i would want to run raid later in my storagenode adverture… but for starting up… might as well make multiple nodes… many advantages to that
9 posts were split to a new topic: And how i can make 4 nodes @ one pc?!
Well, the solution for the high error rate I had previously using the same hardware finally arrived. Some time ago I created a post indicating the disaster of the cancellation rate, and now it seems that the numbers have been turned around.
The photograph indicates all the data provided from a cleaning done at the beginning of the month.
I just recently (18th of October) learned about Storj and since I anyway had a machine running 24/7 with a small unused 2TB drive I figured I give it a try.
I’m wondering how/why almost everyone here has 90% or more success rate. I thought Storj would request files for customers from multiple nodes and whoever delivers the files that the fastest would “win” the race?
That’s actually a very good question now that I think about it. ![]()
not everybody has 100% and especially not as nodes get larger, the avg is more like 90-95% for most decent sized nodes and that may be setting the bar kinda high…
the network doesn’t send requests to all nodes, it picks them by sequence and by locality (latency)
if your system is slow you will get worse results, you just have to beat those that are nearby because the further away other nodes are the slower their response will be due to internet latency.
but yeah the % does seem kinda high… but sending lots of requests and cancelled transfers is also a huge waste of resources… so that would be one thing that there would be a lot of interest in keeping low.
duno the exact magic that makes it so good tho… from what i’ve seen in the past, it does seem to be related to traffic on the network, the more load the more cancelled requests there will be.
which means fewer nodes will have near 100% in those cases…
i suppose one way of thinking of it could be like this…
we know the satellites keep a tally and distributes the data evenly across the nodes… thus if a node is ready when asked it will have selected because of its latency to the customer or so… thus it’s in optimal conditions and will take the data almost instantly…
as we imagine more traffic this tally cycle gets shorter so that its more often that a satellite will pick the same node… thus increasing the load until the node starts to gets cancelled uploads, ofc those with still 100% or near will then be picking up the slack from the rest…
still doesn’t make completely sense… hmmmm somebody set us straight please ![]()
has to be something with the latency selection the satellites do or some sort of timer or something.