--hashstore.logs-path string path to store log files in (by default, it's relative to the storage directory)' (default "hashstore")
--hashstore.table-path string path to store tables in. Can be same as LogsPath, as subdirectories are used (by default, it's relative to the storage directory) (default "hashstore")
1 Like
it should be in the same format as in the storage?
OK, just tested. Working.
hashstore.table-path: /ssd/hashstore
/ssd/hashstore/1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE/s0/meta/
/ssd/hashstore/1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE/s1/meta/
/hashstore/meta/ should stay where it was placed before
1 Like
How does it work, you set the variable and restart the node and it move the data to the new location?
Or you have to move then while the node is offline?
Shut down node, move folders and set variable in config. Then start node. Doubt they can be moved automatically
1 Like
Same ![]() but I rather ask the one that tried first.
but I rather ask the one that tried first.
Thx!
It seems that sometimes multiple compaction jobs can be performed simultaneously. It would be good to limit their number to 1.
Also, there are too many compactions, they are almost unstoppable now. I see “rewritten bytes: 0.9 GiB”. It looks like default 75% threshold don’t working on 1.123.0.
1 Like
If somehow, after the node migrated to hashstore, we switch those flags to false, or delete them, what happens with new pieces? Will they be stored old way, in piecestore? Will the hashstore be unrecognised/unused by the storagenode software?
Second: to enable migration after setting those flags to true, is it necessary to restart the node? Or it will read those flags on the go and start the migration?
1 Like
AFAIK there are no other flags on the configuration file that you can change and have an effect without restarting the node.
I don’t see why this should be any different…
1 Like
Because you don’t set those in the config file. You just create some extra files, linux style, that say true or false. They can be read on the go, if the node keeps monitoring the hashstore dir.
1 Like
Must admit I didn’t pay too much attention to this. Seems very promising but very early stages so not deploying it just yet.
I thought it was just a configuration line added to config.yaml
I’ll crawl back under my rock now ![]()
2 Likes
I see Synology has a new 1 bay NAS, DS124, that is tempting if you use a big drive that will fill in 5+ years and don’t hope to use a second one.
But it has 1GB RAM soldered.
I ran 2 nodes with 10TB+ of data combined on 1GB, before hashstore or badger. But then, the new node selection algo wasn’t live also.
I wonder how and if the 1GB memory affects performance of a 20TB node on hashstore?
Is memory a bottleneck still?
It repeats the message, this is doesn’t mean that it actually rewrites it. Developers said that it’s not easy to deduplicate messages without slowing down the backend.
I asked the team. But I believe, that it will start to store new pieces in a piecestore backend, and will serve pieces from both backends.
The restart is required, unless you created these files before the node start.
1 Like
Has this situation improved any on your hashstore node?
There was an update that adds “env config for compaction”
I added this line to my docker start command (not sure if this is the correct way to do it)
-e STORJ_HASHSTORE_COMPACTION_ALIVE_FRAC=0.99 \
0.99 might be too high but I mainly just wanted to see if this setting was functional.
My dashboard is looking like this at the moment.
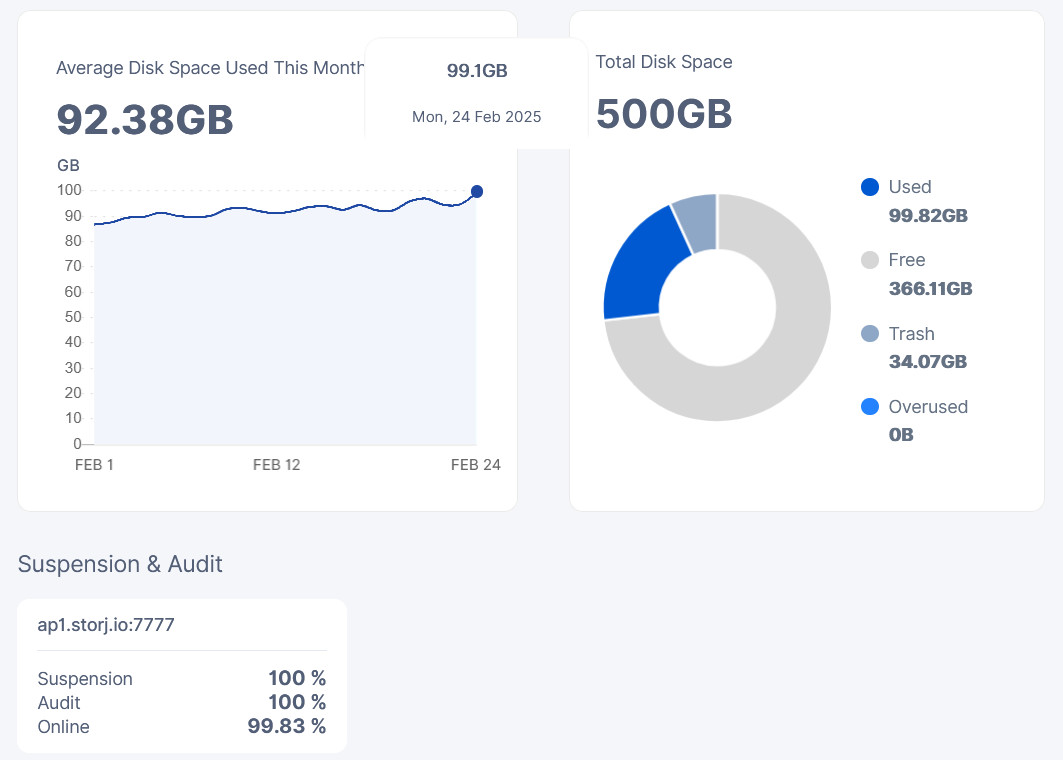
I’m not actually 100% sure that this setting is taking effect on my node. If it does work, the results were not instant. Even after some compactions, I saw no effect initially but eventually things got better all the sudden. I think the numbers we’re seeing on the dashboard could still be buggy at times. Hard to say.
@Mark, thanks for asking. That is certainly worth trying. But isn’t that a change coming in v1.123. My hashstore node is currently running v.122.1.
The situation has not improved. It was like this in January also.
Running sudo du -h now on the hashstore folder returns 1.2T. That fits with the right pie chart when adding Used with Trash.
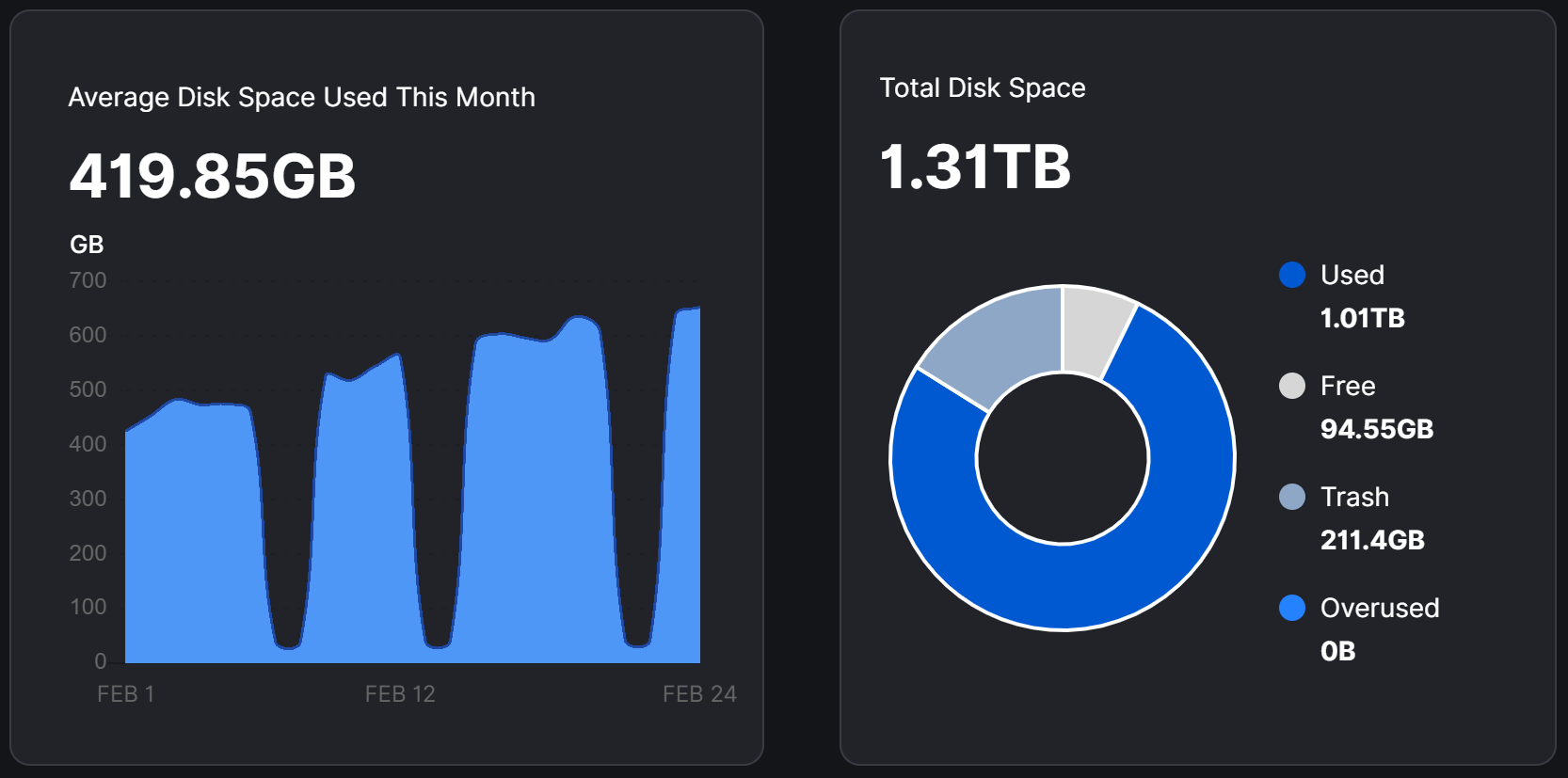
My suspicion is that there are forgotten log files in the hashstore folder taking up room. Could that be the case?
In 1.122.1 also
The default compaction settings are supposed to not waste more than 25% space if I understand correctly. However, the discrepancy on your node seems bigger than that ![]()
I would hope that compaction would rewrite the log file in that case. It remains a mystery.
1 Like
The increased compact activity is intensional. We want to try a bit more agressive compaction to see how that impacts performance and used space overhead. I would expect an intial catchup that might be a bit more expensive than usually but it should calme down after that. There are a few more changes in future releases. Just so that it doesn’t get borring. Please keep up the great feedback ![]()
2 Likes
hello, i am trying to migrate one node to hashstore, but there are still pieces left in the blobs folder.
du -sh blobs/pmw6tvzmf2jv6giyybmmvl4o2ahqlaldsaeha4yx74n5aaaaaaaa/
1,3G blobs/
the other folders were successfully deleted with the above provided command, as there were 0b pieces. but here are pieces that contains up to 22Mb. i dont see any error in the logs. or is there anything specific what i can search for? This is my smallest node with just 0.8Tb stored.
We had a discussion yesterday about moving the hashtable to a SSD. I believe there are even code changes in the release that would allow that. Please don’t do it. The main developer for hashstore is concerned about wearing off the SSD in a short time.
Here is a paper that explains the problem in details: https://paragon.cs.northwestern.edu/papers/2013-BigData-HashFlash-Clemons.pdf
Lets give the developers time to come up with a solution.
6 Likes
Thank you for keeping us updated!
2 Likes