littleskunk:
My solution
committed 12:15PM - 23 Jan 25 UTC
Change-Id: I4ecbf6c024e36b920371ca1eb8b995ccc99976fe
I wonder why is it false by default.
In storj select we don’t run the maintenance jobs inside the storage node process. We run them as separate processes. I think that commit is for that cleanup process and the normal migration might still leave empty files behind even if you enable that setting.
2 Likes
Mark
February 18, 2025, 2:26am
227
Is this something that is possible for a regular node operator to do as well? I’d be interested in experimenting with the compaction options but it seems like the compaction jobs occur on a somewhat random 24 hour timer, which mostly just tests my patience instead of the config changes I make. In other words, is it possible to force a compaction?
snorkel
February 18, 2025, 3:03pm
228
Yesterday just finished the migration on the first node, so 17 days it took, but last 12 days it had no ingress, so it speeded up the process. In order to correct de used space calculation, I will delete all db-es and deactivate the badger. Let’s hope it will work.
2 Likes
molnart
February 18, 2025, 3:17pm
229
you’re saying deleting the dbs is safe?? i thought deleting dbs is a surefire one-way ticket to disqualify the node…
snorkel
February 18, 2025, 3:35pm
230
You can stop the node and delete the db-es. It’s safe. I’ve done it many times. The node is recreating them. You just loose some stats for the current month, but no payout is affected, or data or scores.https://forum.storj.io/t/what-can-i-delete-on-storagenodes/29187?u=snorkel
1 Like
Im curious if those that have migrated and stopped getting ingress have badger cache enabled or not? I dont think that would affect things, but just trying to think through possible correlating issues.
Tried your suggestion on my two smallest nodes(turned badger off as well). It made no difference at all for me. The difference between your setup and mine is that I have ‘Dedicated disk’ turned on. I think you said in an earlier post that you didn’t use that.
Great to hear you got your used space calculation to work. I tried deleting all the .db files under storage and also deleted the piece_expirations folder. Unfortunately that did not fix the used space calculation on my node. There is another .db file in the root of the node called revocations.db. Is that safe to delete as well? Could you share exactly which settings you are using on that node?
molnart
February 18, 2025, 7:01pm
234
i had no badger enabled. honestly i did not even know its a thing before stumbling upon this thread
snorkel
February 18, 2025, 7:56pm
235
This is the startup file walker on a full migrated 5TB node, on a system with 8GB RAM; usualy it was taking days to finish:
2025-02-18T15:11:01Z INFO pieces used-space-filewalker started {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S"}
2025-02-18T15:32:22Z INFO pieces used-space-filewalker completed {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Lazy File Walker": false, "Total Pieces Size": 0, "Total Pieces Content Size": 0, "Total Pieces Count": 0, "Duration": "21m21.60683003s"}
2025-02-18T15:32:22Z INFO pieces used-space-filewalker started {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2025-02-18T15:33:32Z INFO pieces used-space-filewalker completed {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "Lazy File Walker": false, "Total Pieces Size": 0, "Total Pieces Content Size": 0, "Total Pieces Count": 0, "Duration": "1m9.207302349s"}
2025-02-18T15:33:32Z INFO pieces used-space-filewalker started {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2025-02-18T15:33:32Z INFO pieces used-space-filewalker completed {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Lazy File Walker": false, "Total Pieces Size": 0, "Total Pieces Content Size": 0, "Total Pieces Count": 0, "Duration": "407.111412ms"}
snorkel
February 18, 2025, 8:00pm
236
So, I stopped and rm the node, I deleted all db-es in the storage directory (not in other directories, as I explained in the dedicated post); I also deleted piece-expirations dir and filestatcache dir.
Synology NAS + Docker:
echo "net.core.rmem_max=2500000" >> /etc/sysctl.conf
sysctl -w net.core.rmem_max=2500000
echo "net.core.wmem_max=2500000" >> /etc/sysctl.conf
sysctl -w net.core.wmem_max=2500000
echo "net.ipv4.tcp_fastopen=3" >> /etc/sysctl.conf
sysctl -w net.ipv4.tcp_fastopen=3
docker run -d --restart unless-stopped \
--stop-timeout 300 \
--network host \
-e WALLET="xxx" \
-e EMAIL="xxx" \
-e ADDRESS="xxx:28901" \
-e STORAGE="7TB" \
--mount type=bind,source="/volume1/Storj/Identity/storagenode/",destination=/app/identity \
--mount type=bind,source="/volume1/Storj/",destination=/app/config \
--log-driver json-file \
--log-opt max-size=25m \
--log-opt max-file=3 \
--name storagenode storjlabs/storagenode:latest \
--server.address=":28901" \
--console.address=":14011" \
--server.private-address="127.0.0.1:14021" \
--debug.addr=":6001" \
--log.level=info \
--log.custom-level=piecestore=FATAL,collector=FATAL,blobscache=FATAL \
--pieces.enable-lazy-filewalker=false \
--storage2.piece-scan-on-startup=true
docker logs storagenode 2>&1 | grep "used-space-filewalker"
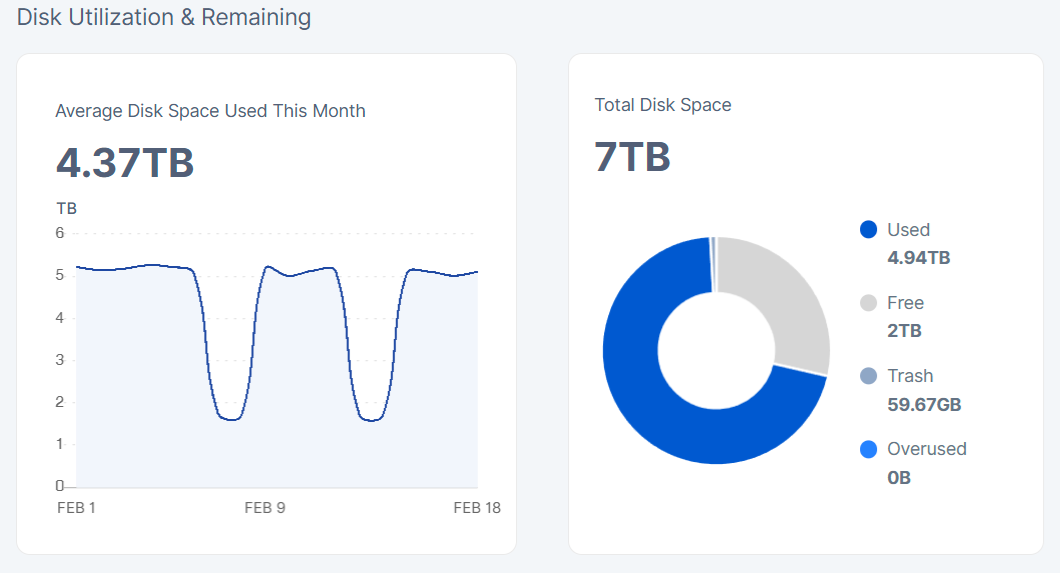
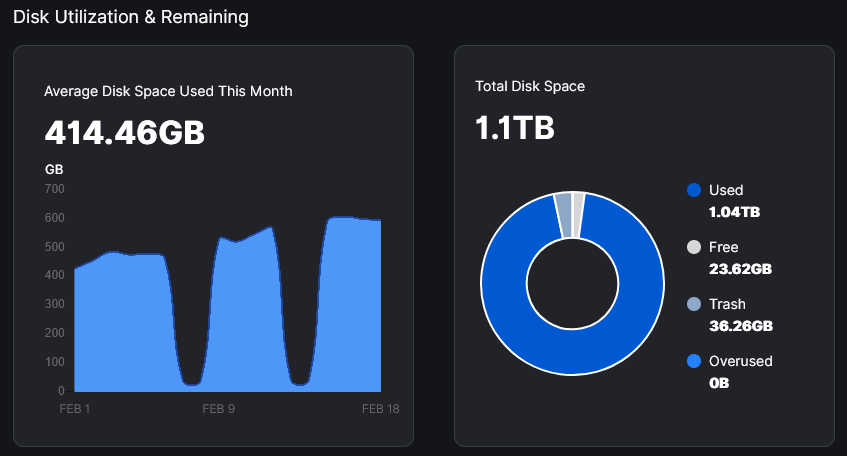
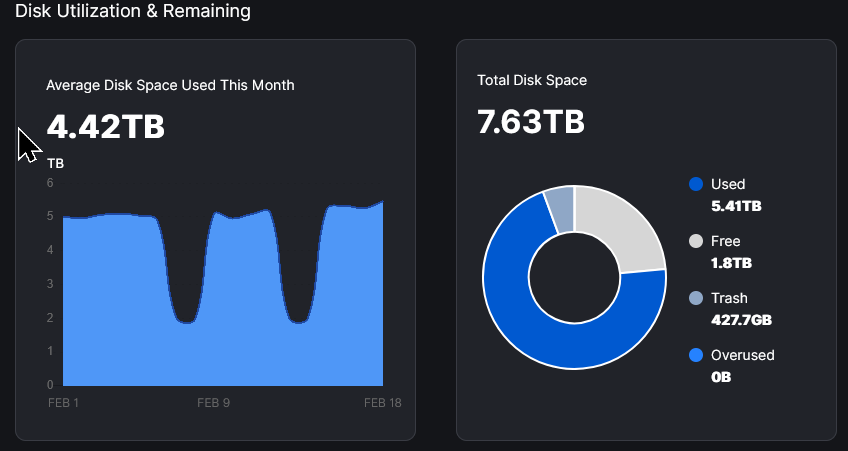
Thanks for that info. I now see the used space value
But I still don’t understand why there is such a big difference between used space and average disk space used this month. Used space has been above 700GB all of 2025
snorkel
February 18, 2025, 9:03pm
238
You see those dips? That’s why! There are some missing reports from US1 I believe.
1 Like
What about the plotted values on the other days. Shouldn’t they be closer to the actual used space?
For example this piece stor node I can understand. The used space value corresponds with the graph
@PieceKeeper “It was setting dedicated disk to false that did the difference.”
So now we can confirm that setting ‘Dedicated disk’ to enable destroy the used space calculations.
I leave the dedicated disk turned on and wait for the bugfix. The node is working so the numbers shown in the web-app is not important to me.
Alexey
February 19, 2025, 4:48am
241
The usage calculation for Dedicated enabled is not working
opened 03:40AM - 13 Feb 25 UTC
Bug
<!--
Please make sure that we do not have any duplicates already open.
You can … ensure this by searching the issue list for this repository.
If there is a duplicate, please close your issue and add a comment to the
existing issue instead.
For more information about reporting issues, see
https://github.com/storj/storj/blob/main/docs/storagenode/CONTRIBUTING.md
---------------------------------------------------
GENERAL SUPPORT INFORMATION
---------------------------------------------------
The GitHub issue tracker is for bug reports and feature requests.
General support can be found at the following locations:
- Storj Community Forum - https://forum.storj.io
- File a ticket at https://support.storj.io/
---------------------------------------------------
BUG REPORT INFORMATION
---------------------------------------------------
-->
**Description**
Node with enabled disk dedicated feature doesn't show the used space neither on single node dashboards (web and CLI) nor multinode for both - hashstore and piecestore.
<!--
Provide a more detailed introduction to the issue itself, and why you consider it to be a bug
-->
**Screenshots**
## Dedicated disk piecestore node:
Single node GUI dashboard:

Multinode:

CLI dashboard:
```
$ docker compose exec storagenode1 storagenode dashboard --address=:30002
Storage Node Dashboard ( Node Version: v0.0.0 )
======================
ID 12L6jNwotMCZmXLGSrQKpCnYCdmpiSQusfPkwyKYJKdqCxVVoYW
Status ONLINE
Uptime 3m52s
Available Used Egress Ingress
Bandwidth N/A 128.28 MB 0 B 128.28 MB (since Feb 1)
Disk 12.55 GB 0 B
Internal :30002
External storagenode1:30001
```
disk usage
```
$ docker compose exec storagenode1 du --si -d 1 /var/lib/storj/.local/share/storj/storagenode/storage/
8.2k /var/lib/storj/.local/share/storj/storagenode/storage/piece_expirations
33M /var/lib/storj/.local/share/storj/storagenode/storage/trash
4.1k /var/lib/storj/.local/share/storj/storagenode/storage/temp
17k /var/lib/storj/.local/share/storj/storagenode/storage/hashstore
65M /var/lib/storj/.local/share/storj/storagenode/storage/blobs
98M /var/lib/storj/.local/share/storj/storagenode/storage/
```
disk free:
```
$ df --si /dev/sda1
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 41G 28G 13G 69% /
```
## Dedicated disk hashstore node
Single node GUI dashboard:

Multinode:

CLI dashboard:
```
$ docker compose exec storagenode10 storagenode dashboard --address=:30092
Storage Node Dashboard ( Node Version: v0.0.0 )
======================
ID 12LqASUH4LSfVYnfFmjQ6DnrJVYkodfhAMFMhn4ryRbERaFeHvL
Status ONLINE
Uptime 15m45s
Available Used Egress Ingress
Bandwidth N/A 124.71 MB 0 B 124.71 MB (since Feb 1)
Disk 12.54 GB 0 B
Internal :30092
External storagenode10:30091
```
disk usage
```
$ docker compose exec storagenode10 du --si -d 1 /var/lib/storj/.local/share/storj/storagenode/storage/
8.2k /var/lib/storj/.local/share/storj/storagenode/storage/piece_expirations
13k /var/lib/storj/.local/share/storj/storagenode/storage/trash
4.1k /var/lib/storj/.local/share/storj/storagenode/storage/temp
97M /var/lib/storj/.local/share/storj/storagenode/storage/hashstore
41k /var/lib/storj/.local/share/storj/storagenode/storage/blobs
99M /var/lib/storj/.local/share/storj/storagenode/storage/
```
disk free is the same
```
$ df --si /dev/sda1
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 41G 28G 13G 70% /
```
**Steps to reproduce the issue:**
1. run storj-up with satellite-api/core, db, storagenodes, satellite-gc and satellite-bf
2. enable hashstore for one node using https://forum.storj.io/t/tech-preview-hashstore-backend-for-storage-nodes/28724
```
sed -i 's/false/true/g' storagenode9/storj/storagenode/storage/hashstore/meta/12whfK1EDvHJtajBiAUeajQLYcWqxcQmdYQU5zX5cCf6bAxfgu4.migrate
echo -n 'true' > storagenode10/storj/storagenode/storage/hashstore/meta/12whfK1EDvHJtajBiAUeajQLYcWqxcQmdYQU5zX5cCf6bAxfgu4.migrate_chore
```
3. enable disk dedicated feature for that hashstore node
```
storj-up env set storagenode10 STORJ_STORAGE2_MONITOR_DEDICATED_DISK="true"
```
4. enable disk dedicated feature for piecestore node
```
storj-up env set storagenode1 STORJ_STORAGE2_MONITOR_DEDICATED_DISK="true"
```
5. `docker compose up -d`
6. configure `uplink` to work with storj-up
7. Upload the file with TTL and without TTL
8. Delete the file without TTL
9. Make sure that it's moved to the trash on nodes
10. Check both dashboards for hashstore+dedicated and piecestore+dedicated
11. Compare results with `du --si`
**Describe the results you expected:**
Used space and trash on dashboards should match (or being pretty close to) the actual usage on the disk.
GUI dashboards should show the free space on the disk (CLI and Multinode dashboards shows it)
**Describe the results you received:**
Used space and trash both zero, single node GUI dashboards shows the disk size as a free space, Multinode dashboards shows the free space on the disk, but the used space is still zero.
**Possible Fix**
disable the dedicated disk feature.
**Your environment**
- Operating system and version:
```
$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 24.04.1 LTS
Release: 24.04
Codename: noble
```
- Additional environment details (Raspberry PI, Docker, VMWare, etc.):
```
$ storj-up version
panic: runtime error: slice bounds out of range [:-1]
```
but it's built from `main`
```
$ docker compose exec storagenode1 storagenode version
Development build
Build timestamp: 01 Jan 70 00:00 UTC
Git commit: 35385635fdbb5f31bf2bc44cb9e12032d240bd82
Modified (dirty): true
```
built from `main`
Alexey
February 19, 2025, 4:51am
242
No, the badger is not affecting this, but databases seems are not correctly updated after migration. So, deleting them may fix the issue. I think that this one should be enough:
Only wait until all used-space-filewalkers will finish the scan since the last restart.
Because right now you logs shows only several starts of the used-space-filewalkers but only a few completed.
I have a suspicion that we might introduced a bug in used-space-filewalker, when we tried to implement a continuation of the used-space-filewalker.
You can test that:
Stop and remove the container (or stop the service, if you use a service based setup)
Rename the used_space_per_prefix.db database …
Alexey
February 19, 2025, 4:56am
243
You may use the latest full report data point as a rough estimation of the used space from the satellites perspective. The exact would be in the payout receipt, so you would need to check it after day 15 of the next month.
@Alexey , can you explain v1.123 change? 23ce0ba storagenode/hashstore: make the location of hashstore hashtables configurable
what flag should i use to configure hashtable meta on ssd and what dir structure should it have?