How much pieces and how much collected? I was assured that our big BF should cover almost all sizes reported to the satellites…
Not running info log.
Hm. I would ask the team is it possible to get this info in a different way, maybe via a debug port…
I think @littleskunk might know too.
Finally someone who seems to be in the same boat with me.
Basically what I am seeing over my nodes. Trash in terabytes. But I must admit that I turned of filewalkers on some of them because they could not finish it. That’s we the upcoming fixes are so important to get the numbers straight again and I finally can tell how much used space, garbage or trash is even there.
Yes, I’ve seen attempts to fix some issues. Some of those fixes seem to be unstable, hopefully it’ll improve.
The option of community contribution is good to have. If this business turns out worthwhile for me I’ll see if I can make my 2 cents contribution.
Whilst I would love to do that, I am in that awkward position where I know just about enough to tell that something is going wrong but by no means enough to suggest how to make it right ![]()
Gonna be honest, I don’t even know what a “pull request” actually means! I’ll have to google that one at some point ![]()
Yes, this is a contribution too! It also helps if the Community provide a needed info to find a root cause faster.
And I believe that the case with these prospective customers helped a lot to improve the code, so I hope it should help to fix issues faster, too.
that’s fine. Not all should be a programmer (I’m not sure in the today world, though ![]() )
)
Can it be something done with piece_expiration.db size? Like make a few smaller ones than a single big one? Or something?
I don’t know how a db is write/read, but I imagine it is kept in RAM too and synced to HDD? That means it takes a lot of % of memory on the low RAM systems that could be used for something else.
I understand that at startup, the node performes a pragma integrity check on db-es?
Could it be implemented to perform the vacuum too, after the pragma OK?
This is already suggested here:
I shared this suggestion with the team.
yes, it’s possible… However, did you see a size of that DB? Can it be fitted into the RAM in all cases?
No, but it’s tried to open them, then the driver would sometimes tell something useful if it cannot open it. But we do not perform an integrity check directly.
The autovaccuum is enabled by default as far as I know. However, I believe it unlikely help if that database has all these records.
While it is nice to have a Bloom filter every day, if the corresponding filewalker process needs days to finish, then it does not help.
It would be great to have that on the dashboard.
Like when a filewalker started, is running or has finished.
I lost count of post I have to replay, so I’ll post it here.
I checked databases on all nodes, with Saltlake and without. I’ll put here what I found for a machine with 2 nodes fitting that description. Other machines look similar to this one, because all have 1 node with SL and one node without SL.
Without SL, the piece_expiration.db is in MB range, like 200MB for 8TB of data.
With SL, the piece_expiration.db is in GB range, and the biggest I have is 28GB, for 21TB of data.

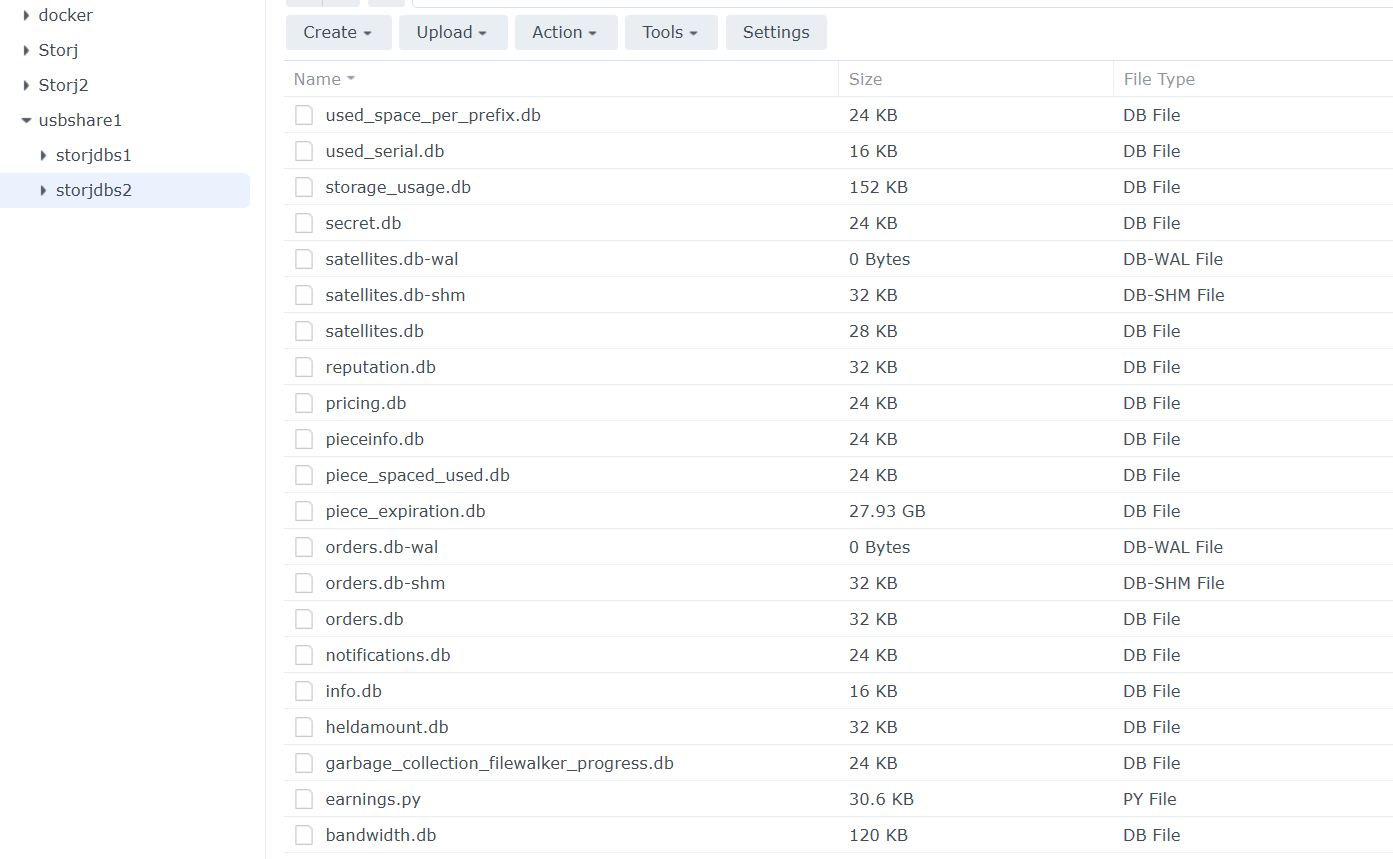
Another discovery: for the filled nodes like this one, with less than 5GB of available space, are missing those temp files for piece_expiration.db, -wal and -shm. I don’t know their role, but they are missing. The node is running, ver. 104.5.

no, the m here is stands for a “minutes”, not “months”.
Regarding the send pieces to trash: false option, I’ll try to check if there are new pieces in trash, but that system is very slow and low responsive, with 1GB RAM.
After setting the option and stop, rm, restart node, I see this log entries:
2024-06-21T22:30:10Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-17T17:59:59Z", "Filter Size": 1484102, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2024-06-21T22:50:49Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 13546, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 2501193, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Duration": "20m39.544946417s", "Retain Status": "enabled"}
2024-06-22T12:47:26Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-18T17:59:59Z", "Filter Size": 1484102, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2024-06-22T13:06:17Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 4892, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 2495443, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Duration": "18m50.974793335s", "Retain Status": "enabled"}
2024-06-21T22:23:19Z INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE"}
2024-06-21T22:23:19Z INFO pieces:trash emptying trash finished {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "elapsed": "6.683105ms"}
2024-06-21T22:23:19Z INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2024-06-21T22:23:19Z INFO pieces:trash emptying trash finished {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "elapsed": "31.133444ms"}
2024-06-21T22:23:19Z INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S"}
2024-06-21T22:23:19Z INFO pieces:trash emptying trash finished {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "elapsed": "11.699328ms"}
2024-06-21T22:23:19Z INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2024-06-21T22:23:19Z INFO pieces:trash emptying trash finished {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "elapsed": "12.187975ms"}
2024-06-22T22:23:20Z INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2024-06-22T22:23:20Z INFO pieces:trash emptying trash finished {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "elapsed": "147.114507ms"}
2024-06-22T22:23:20Z INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE"}
2024-06-22T22:23:20Z INFO pieces:trash emptying trash finished {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "elapsed": "170.166µs"}
2024-06-22T22:23:20Z INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2024-06-22T22:24:08Z INFO pieces:trash emptying trash finished {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "elapsed": "48.548610977s"}
2024-06-22T22:24:08Z INFO pieces:trash emptying trash started {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S"}
2024-06-22T22:24:09Z INFO pieces:trash emptying trash finished {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "elapsed": "149.062982ms"}
The node is runnig, but no log entries today.

so, they are stands for a journal. If they are absent, then probably you do not have any changes in that database since the last restart (they should be deleted after the grace shutdown or after the replay and should be created back, if there are changes which should be applied to the database).
Is the trash folder empty as for now?
If it is fast on your nodes then it is great.
However it could take longer on other nodes:
This needs to be kept in mind.


Hahahahaha! Have a beer! ![]()
How can I check if there are newer files in the trash folder since restart 30h ago, for EU1 sat?
The path to pieces is like:
/volume1/Storj/storage/trash/v4weeab67sbgvnbwd5z7tweqsqqun7qox2agpbxy44mqqaaaaaaa/2024-06-22/2a