
It seems that about one-third of the hard disk space is free of charge. In the last two months, a large number of files have not been deleted. How can I receive filters to delete files stored on the hard disk but not charged
I don’t know how you come to this conclusion. “Free” means free disk space. There are no files stored in there.
2 Likes
1.67TB of storage space takes up 1.67 * 24TB * h every day, but this chart shows that only about 25TB * h is used. Trash is rare in the last two months. Before July, it always exceeds 100GB. So did I miss too many notifications of deleting files? Will you regularly send a clean filter to clean up files that should not exist?
Just pitching in to clarify my own understanding - free space is space not used by anything so obviously, you aren’t paid for it.
However, his 90.32TBh confuses me. Let’s take just the first four days (24 * 4 = 96) and then even say he had only 1TB used he should be at bare minimum at 96TBh by October 4 no? That’s the part that confuses me.
Will you regularly send a clean filter to clean up files that should not exist?
Yes, files deleted from the system (customers) get stored for 2 weeks and then deleted from the nodes. I believe satellites send some sort of rainbow file that the node checks for matches and deletes what is not needed based on it.
Need to receive some form of list to clean up the documents that should not exist?
Need to receive some form of list to clean up the documents that should not exist?
This happens automatically, without SNO intervention, one thing you can do is check your logs to make sure there aren’t any weird errors…
My understanding is that before July, my slow connection node Trash was always greater than 100GB. Now the situation is completely opposite. The slow node stores too many files that should not be stored. These files that should not exist always entered Trash quickly before July, but now it is always stored on the hard disk and cannot be deleted
In addition, the faster nodes do not see this situation
This is based on real user.
You can’t predict when they will be deleting their files.
Storing files is a good thing, since you are getting paid for it.
Did you want your node not store “too many files”?
On my 10TB nodes, I only have about ~30-50G of trash whenever I check it.
Hi @chinabjy
Please can you post an updated dashboard screenshot showing the current graph and pie chart.

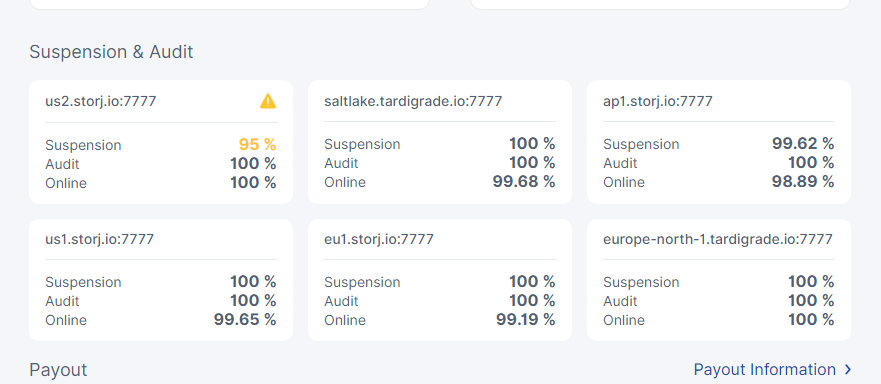
Thanks. Please can you also post the dashboard section showing the ‘suspension & audit’ scores.
I expect we’ll need to delve deeper into each satellite to work out if one is misreporting.
This node is slow. Previously, many files were deleted to Trash, but few were deleted in the last two months. I have some faster nodes that do not have this problem.
Hope to receive the filter to clean up the files that should not exist
If the node is slow then it could be that the filter (retain) process is running but not completing. There is a monkit (monitoring) port which can be used to extract data for the node processes. By default the monitoring port is randomly assigned each time the node is started - Guide to debug my storage node, uplink, s3 gateway, satellite
If you can find the port then please run the /mon/ps command in a browser, against that port.
About the end of July, after the node trash was automatically cleared, the number of deletions became very small. Trash was always greater than 100GB before July. I think the list of deletions sent from satellites after August was not comprehensive enough, and some types of deletions were omitted
This isn’t really possible. The deletion process uses a bloom filter. If a deletion was missed on the first run it would catch it on the next run … unless the deletion process never completes. That is why the next step would be to check the running processes.
FYI - my node used to take over a month to complete some delete runs as multiple deletions were running simultaneously.
[root@osd-r7 ~]# curl http://192.168.0.108:5999/mon/ps
[6213759445242752933,2354476574718370747] storj.io/private/process.root() (elapsed: 38m38.182651118s)
That seems short. After restarting my node it is this…
[2206357308291004708,8606774546701498039] storj.io/common/rpc/rpctracing./piecestore.Piecestore/Download() (elapsed: 14.9787924s)
[5029312106735287186,8606774546701498039] storj.io/storj/storagenode/piecestore.live-request() (elapsed: 14.9787661s)
[7852266905179569663,8606774546701498039] storj.io/storj/storagenode/piecestore.(*Endpoint).Download() (elapsed: 14.9787572s)
[2341774652569835744,8742191890980329074] storj.io/common/rpc/rpctracing./piecestore.Piecestore/Download() (elapsed: 3.0796095s)
[5164729451014118221,8742191890980329074] storj.io/storj/storagenode/piecestore.live-request() (elapsed: 3.0795844s)
[7987684249458400699,8742191890980329074] storj.io/storj/storagenode/piecestore.(*Endpoint).Download() (elapsed: 3.0795755s)
[3649273968950409047,826319170506126570] storj.io/common/rpc/rpctracing./piecestore.Piecestore/Download() (elapsed: 16.9590489s)
[6472228767394691525,826319170506126570] storj.io/storj/storagenode/piecestore.live-request() (elapsed: 16.959027s)
[71811528984198194,826319170506126570] storj.io/storj/storagenode/piecestore.(*Endpoint).Download() (elapsed: 16.9590188s)
[1079425995273001462,7479843233683494793] storj.io/common/rpc/rpctracing./piecestore.Piecestore/Upload() (elapsed: 4.2795649s)
[3902380793717283940,7479843233683494793] storj.io/storj/storagenode/piecestore.live-request() (elapsed: 4.2795555s)
[6725335592161566417,7479843233683494793] storj.io/storj/storagenode/piecestore.(*Endpoint).Upload() (elapsed: 4.2795432s)
[3919243216659407668,1096288418215125191] storj.io/common/rpc/rpctracing./piecestore.Piecestore/Upload() (elapsed: 40.1031519s)
[6742198015103690146,1096288418215125191] storj.io/storj/storagenode/piecestore.live-request() (elapsed: 40.1031192s)
[3164735575137479293,1096288418215125191] storj.io/storj/storagenode/piecestore.(*Endpoint).Upload() (elapsed: 40.1031068s)
[4866471967163504307,2043517168719221829] storj.io/common/rpc/rpctracing./piecestore.Piecestore/Upload() (elapsed: 1.4118049s)
[7689426765607786784,2043517168719221829] storj.io/storj/storagenode/piecestore.live-request() (elapsed: 1.4117818s)
[1289009527197293454,2043517168719221829] storj.io/storj/storagenode/piecestore.(*Endpoint).Upload() (elapsed: 1.4117735s)
[6140108289231273344,3317153490786990866] storj.io/common/rpc/rpctracing./piecestore.Piecestore/Upload() (elapsed: 3.5691205s)
[8963063087675555821,3317153490786990866] storj.io/storj/storagenode/piecestore.live-request() (elapsed: 3.5690964s)
[2562645849265062491,3317153490786990866] storj.io/storj/storagenode/piecestore.(*Endpoint).Upload() (elapsed: 3.5690867s)
[4891401955366636579,2068447156922354102] storj.io/private/process.root() (elapsed: 41.6288515s)
[6845379731310873036,2068447156922354102] storj.io/storj/storagenode.(*Peer).Run() (elapsed: 41.0769864s)
[4335190180998065440,2068447156922354102] storj.io/storj/private/server.(*Server).Run() (elapsed: 40.2437547s, orphaned)
[4349697945278926407,2068447156922354102] storj.io/storj/storagenode/bandwidth.(*Service).Run() (elapsed: 38.9912243s, orphaned)
[43523292842582901,2068447156922354102] storj.io/storj/storagenode/collector.(*Service).Run() (elapsed: 38.9931698s, orphaned)
[7393523940418435631,2068447156922354102] storj.io/storj/storagenode/console/consoleserver.(*Server).Run() (elapsed: 38.9934035s, orphaned)
[1357462808243008627,2068447156922354102] storj.io/storj/storagenode/contact.(*Chore).Run() (elapsed: 38.992987s, orphaned)
[8707463455818861358,2068447156922354102] storj.io/storj/storagenode/gracefulexit.(*Chore).Run() (elapsed: 38.9932433s, orphaned)
[2086175020713141280,2068447156922354102] storj.io/storj/storagenode/monitor.(*Service).Run() (elapsed: 38.9907228s, orphaned)
[6808296637488142558,2068447156922354102] storj.io/storj/storagenode/orders.(*Service).Run() (elapsed: 38.9929129s, orphaned)
[2671402323643434354,2068447156922354102] storj.io/storj/storagenode/pieces.(*CacheService).Run() (elapsed: 38.992944s, orphaned)
[8317311920531999309,2068447156922354102] storj.io/storj/storagenode/pieces.(*Store).SpaceUsedTotalAndBySatellite() (elapsed: 38.9929348s)
[8876743794410496660,2068447156922354102] storj.io/storj/storagenode/pieces.(*Store).WalkSatellitePieces() (elapsed: 38.9927339s)
[8122236152888568284,2068447156922354102] storj.io/storj/storage/filestore.(*Dir).WalkNamespace() (elapsed: 38.9927277s)
[4544773712922357431,2068447156922354102] storj.io/storj/storage/filestore.(*Dir).walkNamespaceInPath() (elapsed: 38.9927224s)
[2011974200095294294,8412391438505787624] storj.io/storj/storagenode/pieces.(*Store).EmptyTrash() (elapsed: 38.7106904s)
[4834928998539576771,8412391438505787624] storj.io/storj/storage/filestore.(*blobStore).EmptyTrash() (elapsed: 38.7106803s)
[7657883796983859249,8412391438505787624] storj.io/storj/storage/filestore.(*Dir).EmptyTrash() (elapsed: 38.7106589s)
[1257466558573365918,8412391438505787624] storj.io/storj/storage/filestore.(*Dir).walkNamespaceInPath() (elapsed: 38.7106532s)
[5221895067288898639,2068447156922354102] storj.io/storj/storagenode/retain.(*Service).Run() (elapsed: 38.9874481s, orphaned)
[993106702007942301,2068447156922354102] storj.io/storj/storagenode/version.(*Chore).Run() (elapsed: 38.9934029s, orphaned)
This might also be relevant to this thread. We’ve got some testing in progress related to optimizing garbage, garbage collection and emergency restore from garbage for durability analysis. We’ll be wrapping up this work shortly and will resume regularly scheduled garbage collection soon, possibly next week.
3 Likes