I have similar experiences, trash is much older 7 days.
drwx------ 3 root root 4096 Apr 18 06:01
drwx------ 3 root root 4096 Apr 18 06:01
drwx------ 3 root root 4096 Apr 18 06:01
drwx------ 2 root root 4096 Apr 26 08:10
drwx------ 3 root root 4096 Apr 26 08:13
drwx------ 4 root root 4096 Apr 27 09:28
drwx------ 4 root root 4096 Apr 26 08:07
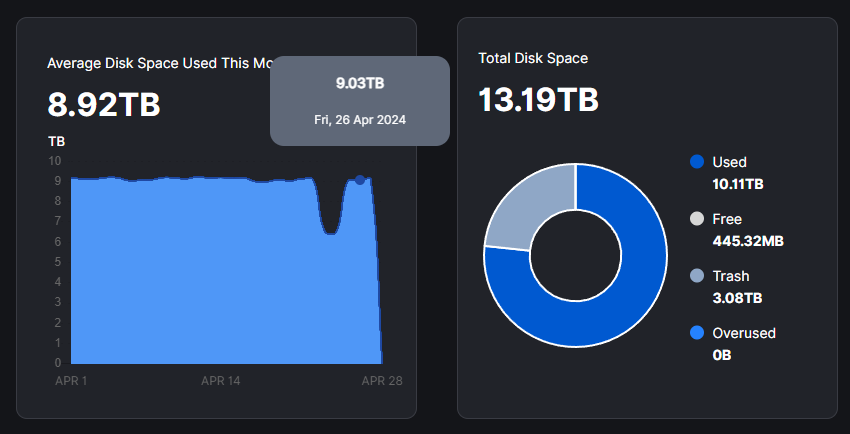
Node is stuck >8days with 1.64TB trash on it (18th of April),
it seems like this behaviour was first seen with v 1.101.3
After watchtower updage from 1.99 to 1.101 i found tons of following logs:
2024-03-27T16:00:22Z ERROR collector unable to delete piece {"process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Piece ID": "HEUJFR5PLARV5TMZSIP36VQ6PKUTYIIHMLICIR56AX4CHELQBIQQ", "error": "pieces error: context canceled; v0pieceinfodb: context canceled", "errorVerbose": "pieces error: context canceled; v0pieceinfodb: context canceled\n\tstorj.io/storj/storagenode/pieces.(*Store).DeleteExpired:365\n\tstorj.io/storj/storagenode/pieces.(*Store).Delete:344\n\tstorj.io/storj/storagenode/collector.(*Service).Collect:97\n\tstorj.io/storj/storagenode/collector.(*Service).Run.func1:57\n\tstorj.io/common/sync2.(*Cycle).Run:99\n\tstorj.io/storj/storagenode/collector.(*Service).Run:53\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2.1:87\n\truntime/pprof.Do:51\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2:86\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75"}
followed by a bunch of:
2024-04-12T13:00:28Z ERROR collector unable to update piece info {"process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Piece ID": "47KWWXM3FN67VXVIHZZAKLQO5SEQTKO5LXT7MMJANS4OQVQE66LA", "error": "pieceexpirationdb: context canceled", "errorVerbose": "pieceexpirationdb: context canceled\n\tstorj.io/storj/storagenode/storagenodedb.(*pieceExpirationDB).DeleteFailed:99\n\tstorj.io/storj/storagenode/pieces.(*Store).DeleteFailed:597\n\tstorj.io/storj/storagenode/collector.(*Service).Collect:109\n\tstorj.io/storj/storagenode/collector.(*Service).Run.func1:57\n\tstorj.io/common/sync2.(*Cycle).Run:160\n\tstorj.io/storj/storagenode/collector.(*Service).Run:53\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2.1:87\n\truntime/pprof.Do:51\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2:86\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75"}
Unfortunately the node was running full last night with now 2.24TB trash on it.
However i noticed that the disk is not full at all, the 1.64TB of trash seems already to be deleted on disk but not released again.
Filesystem Size Used Avail Use% Mounted on
/dev/sdb 25T 22T 1,7T 93% /mnt/datastore
Storage Node Dashboard ( Node Version: v1.101.3 )
======================
ID ;)
Status ONLINE
Uptime 227h43m2s
Available Used Egress Ingress
Bandwidth N/A 2.14 TB 0.88 TB 1.26 TB (since Apr 1)
Disk 457.67 MB 25.10 TB
Internal 127.0.0.1:7778
root@storj: find /mnt/datastore/storage/trash/ -mtime +7 -type f -exec du --block-size=1000 '{}' ';' | awk '{total+=$1; count++}END{print "TOTAL", total/1000, "MB\n" "count", count}'
TOTAL 582340 MB
count 2043449
root@storj:
Bug?
Docker, Ubuntu 20.04.6 LTS