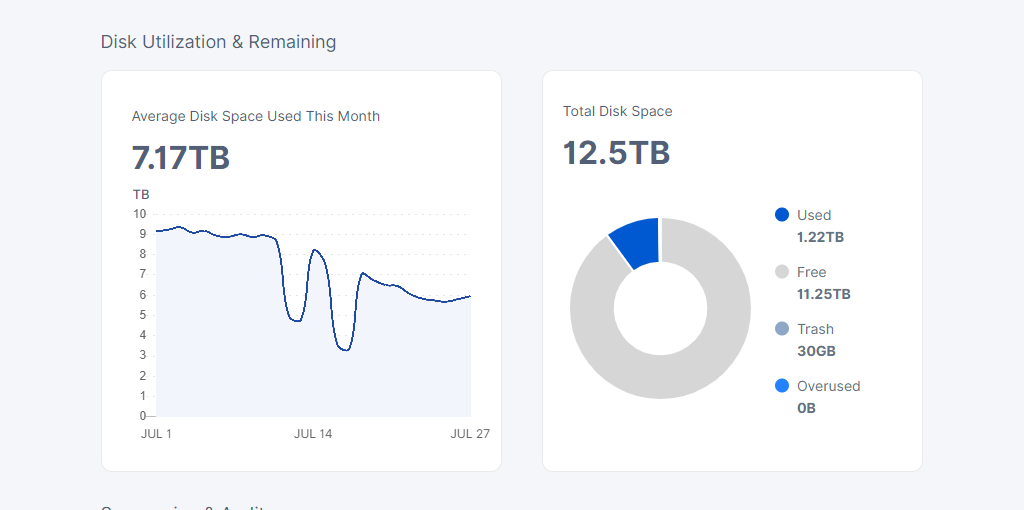
I recreated the databases since i got alot of issues when it updated. i have filled 11.5 TB but according to the satellite im only holding 5.81TB how do i remove all the trash? What is wrong
Everyone should be on 1.108 now, so I thought that problem would have corrected itself with the first used-space-filewalker run. Is filewalker maybe still running?
That is going to get expensive. Deleting the TTL database means your node doesn’t know it is allowed to delete these pieces. it will take a few garbage collection runs to clean that up. Next time better try to rescue at least the TTL database
This is an old feature, if you switch off the lazy mode (pieces.enable-lazy-filewalker: false), the filewalkers will work with a normal IO priority, so the scan on startup will go faster.
However, this requires a restart. If this is a docker node, it will download an older version 1.105.4, which is incompatible with 1.108.3 and it could enter to infinite restart mode (the node would crash, the supervisor will terminate the updater too, then the container will stop, docker will restart the container, the downloader would download an old version of storagenode and start it, etc.).